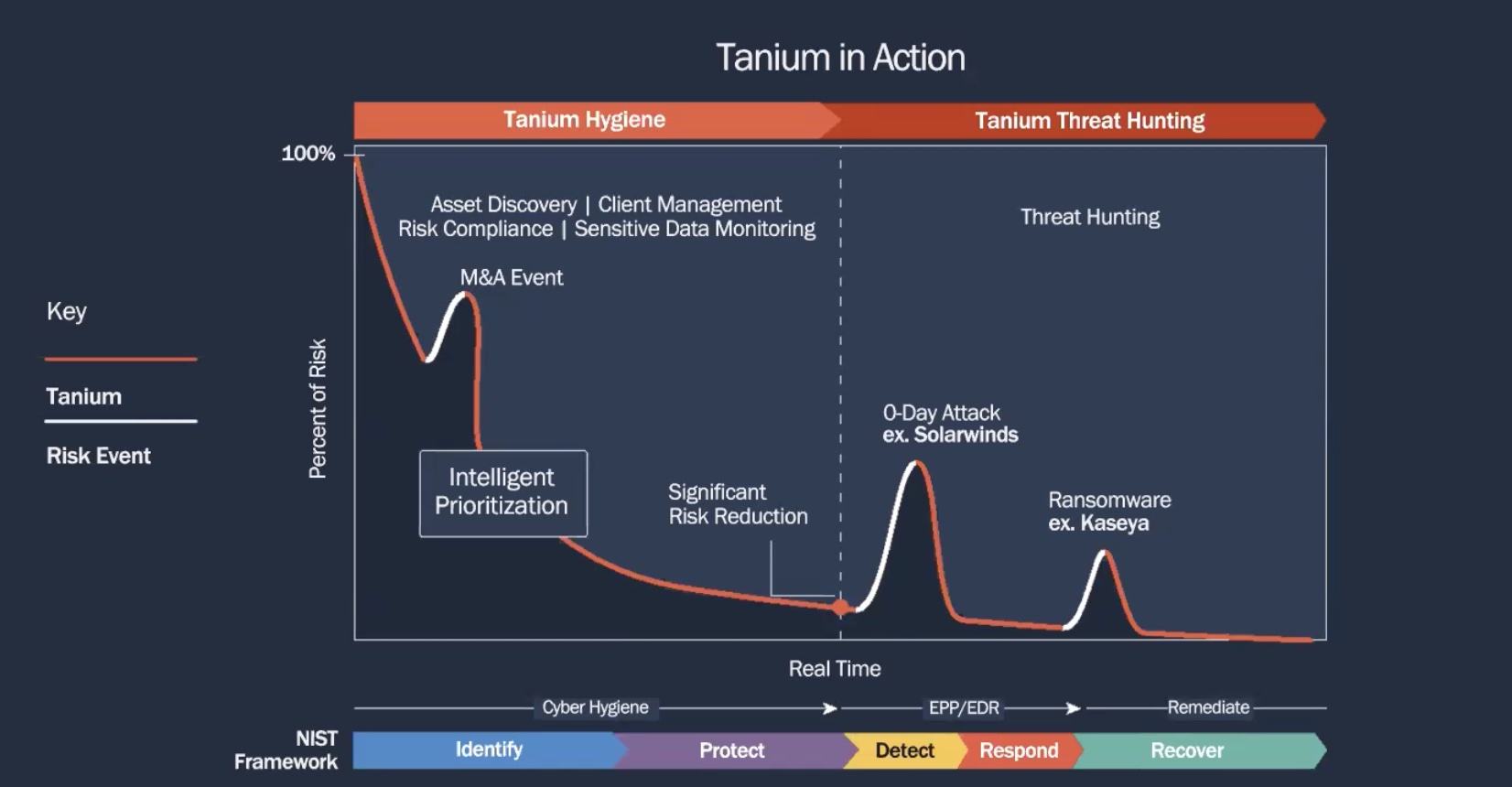
Slaying SPOFs
Some of you know I took on a new job earlier this year, where the challenge was (and is) to transform a globally distributed network for a growing company into an enterprise class operation. A major focus area has been eliminating single points of failure (SPOFs): single links, single routers, single firewalls, etc. If it can break and consequently interrupt traffic flow, part of my job is to design around the SPOF within the constraints of a finite budget.
The network documentation I inherited ranged from “mostly right but vague and outdated” to “a complete and utter fantasy requiring mind-altering substances to make sense of”. Ergo, untrustworthy to the point of being useless beyond perhaps slideware to show a particularly dim collection of simians. I have therefore been doing complete network explorations, building new documentation as I go.
To my horror, I one day discovered an egregious SPOF, where a single, fragile piece of CAT5 provided the sole physical path between two major concentrations of network activity. If that link ran into any trouble, an entire room containing hundreds of physical and virtual servers (and their storage) would have been cut off from the rest of the company.
To eliminate the physical path SPOF, the easy choice was to transform the single link into an etherchannel. This I did; the single 1Gbps became a 4x1Gbps etherchannel plumbed back to one core switch. For good measure, I added a second 4x1Gbps, plumbed to a second core switch. Spanning-tree roots had already been established such that even-numbered VLANs would traverse one of the 4x1Gbps etherchannels, and odds the other…which you can read more about here if interested.
All should now be sweetness and light, right? A 1Gbps SPOF (and probable bottleneck) was transformed into a load-distributed pair of 4x1Gbps etherchannels, and hey, if they weren’t complaining about the 1Gbps link before, they ought to be blissfully happy now!
Mad Maths
Enter the scaling problem: when it comes to etherchannel, 1+1 does not equal 2.
The reason adding more physical links does not proportionally grow your available bandwidth is that your friendly neighborhood Cisco switch does not load-balance across etherchannel members frame by frame. You might assume that the frame #1 gets sent down etherchannel member #1, frame #2 down etherchannel member #2, etc. in a round-robin fashion. Reality is rather different. What the switch actually does is math. The sort of math will vary depending on the capabilities of the switch, and on what you have configured.
Commonly available etherchannel load-balancing methods include source and destination MACs, source and destination IPs, and (my personal favorite) source and destination layer 4 port. To determine which etherchannel member will be used to forward a frame, the switch performs mad maths based on the load-balancing method you’ve selected. The practical upshot is that the same conversation is always going to be forwarded across the same etherchannel member, because the math always works out the same.
This behavior can impact the network. Imagine backup server BEAST with enough horsepower to fill a 1Gbps link who is runing a restore operation to server NEEDY. BEAST and NEEDY are uplinked to different switches interconnected by an etherchannel. As the restore runs, each frame is hashed by the switch to determine which etherchannel member to forward across; the math will work out the same for every frame, meaning the entire conversation between BEAST and NEEDY is going to be forwarded across the same etherchannel member. The result is kind of like the picture above — one member that’s crushed, while the other members lie comparatively idle.
Congestion Indignities
The switch is not sensitive to an etherchannel member getting crushed; the switch just keeps on doing mad maths. Therefore, some other conversations heading across the link will just happen to get hashed to the same link that the BEAST-NEEDY restore operation is using. Those other unfortunate conversations will therefore suffer the indignities that happen during link congestion: dropped frames and increased latency. The real-world experience is that certain applications act slow or throw errors. Storage could dismount. Monitoring applications get upset as thresholds are exceeded.
Yuck.
Of course, it’s now up to the network engineer (you) to discover why the alarms are going off, track down the offending traffic flow (you are modeling your interswitch links, right?), and figure out what is to be done about it. In my experience, you won’t have a lot of luck explaining what’s happening to non-network people. I’ve had a hard time explaining that 1+1 doesn’t equal 2, (or 1+1+1+1 doesn’t equal 4). You don’t really have a 2Gbps or 4Gbps link just because you’ve built a fancy etherchannel. You’ve really got multiple parallel 1Gbps links, any one of which can still get congested in BEAST-NEEDY scenarios.
So Fix It, Network Guy
There’s a few ways to tackle the challenge of 1+1 not equaling 2.
- Learn your traffic patterns. See if you can group heavy hitters into the same switch. That’s a pretty old-school way to go after the problem, and it won’t scale to large data center deployments. But you can find wins in this approach from time to time.
- Build a dedicated link. By this, I mean that you could build a link dedicated to just the traffic that’s causing the interswitch etherchannel all the heartburn. If your etherchannel is a trunk carrying a whole bunch of VLANs, you could build a parallel link that carries traffic for just a problem VLAN, while pruning that problem off of the etherchannel trunk. Might help, might not, depending on your situation…and of course, it’s a “one-off” fix, not a scalable solution necessarily. Some shops build networks dedicated to storage or to backup, and plumb specific interfaces on hosts to these specific networks for exactly this reason. There are increased in hardware, cabling, and complexity to make it happen, though.
- Add even more 1Gbps links to the etherchannel. This is not terribly practical. At the end of the day, you still have a potential bottleneck, but at least you’ve decreased the number of conversations that are likely to get hashed to a congested link.
- Replace the 1Gbps links with 10Gbps links. Increasing bandwidth is always an option. The jump to 10Gbps is a tough one, though: new switch hardware, higher power requirements, and likely new cabling will be required. And don’t forget to break out your checkbook.
- Apply QoS. If you have known offenders or predictable traffic patterns, you can write a QoS scheme to help manage the congestion. I tend to pump traffic like this through a traffic shaper, but there are other approaches, such as guaranteeing minimum bandwidth to important traffic, while dumping the link beast into the scavenger class. I have found that latency still tends to suffer when using a guaranteeing minimum bandwidth (CBWFQ) scheme. I have had the best luck with shaping.
- Tweak the beastly application. It’s not uncommon for certain applications to have a built-in throttle, so that you can cap network utilization right at the app. Talk to your system engineer and see…I’ve heard they’re people, too.