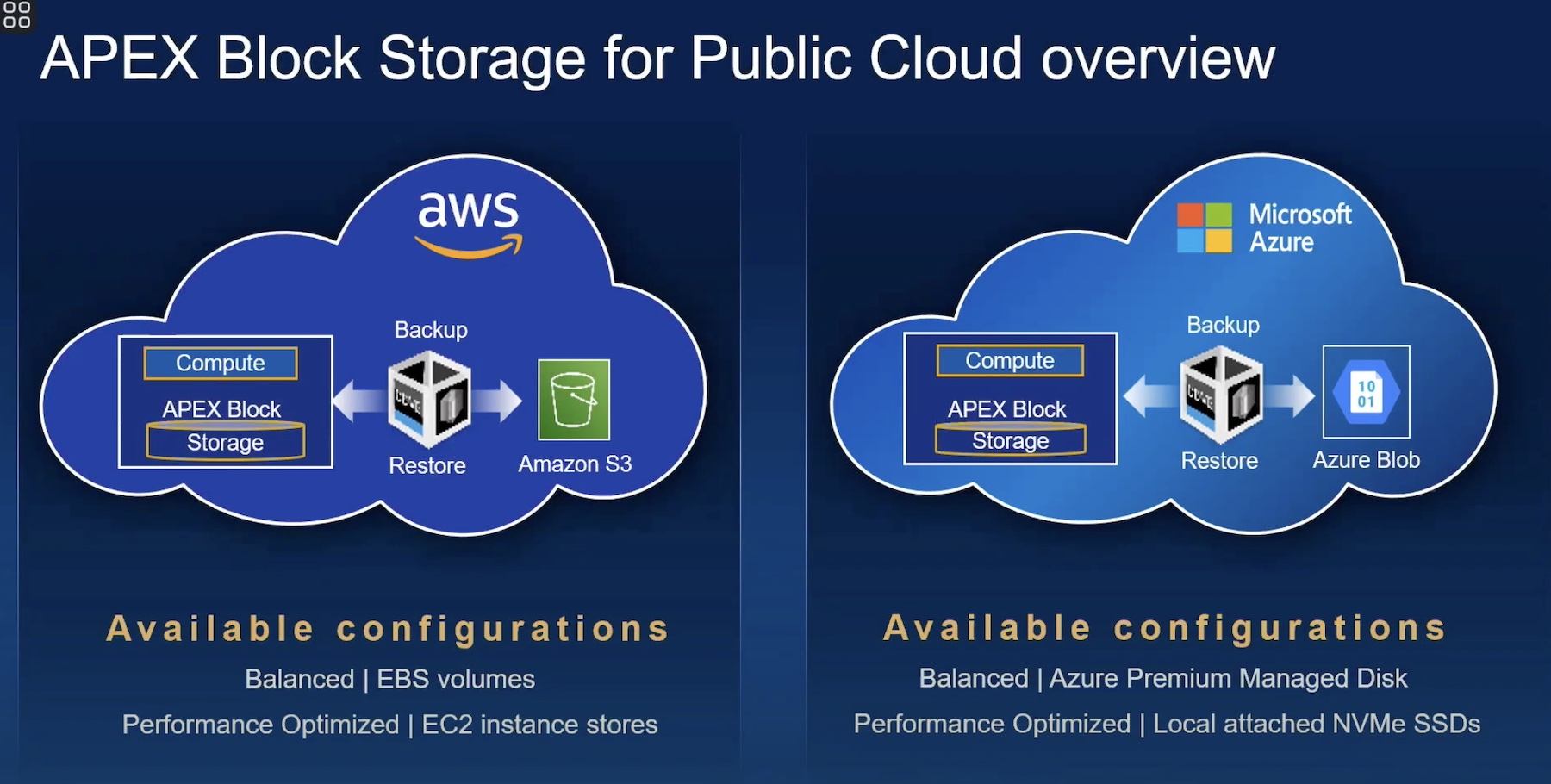
We need to move beyond fake disks and deploy application-centric storage
Change is not a word normally associated with storage, and revolution is practically unheard of. Today’s modern enterprise storage systems and networks employ massive resources to do one simple thing: Emulate the basic hard disk drives used over three decades ago. But cracks are appearing in our mausoleum of fake disks: Application developers are discovering the value of object storage, and storage systems are appearing to support this need.
I also wrote about this two years ago, proclaiming that We Need a Storage Revolution and forecasting The Techie/Business Schism
The CAS Revolution
Caringo founder and CTO, Paul Carpentier, rose to prominence around 2000 at FilePool, one of the prime movers in the content-addressable storage (CAS) space. I recall a light going off in my head as Paul introduced me to FilePool’s CAS technology back then, imagining the possibilities of the concept. Files would be stored based on “what they were” rather than “where they were” and could be organized according to application needs rather than the conventional “extent of blocks” or tree heirarchy.
CAS discarded decades of filesystem and block storage baggage, introducing a new method for storing and retrieving data that better-matched the burgeoning web and enterprise applications of today. I had seen the failure of the first wave of storage service providers from inside StorageNetworks, and it was this desire for a real storage revolution that led me to dive into cloud storage at Nirvanix almost a decade later. Although I am now on my own, I remain convinced that the future belongs to storage systems that look nothing like today’s SAN and NAS.
Shortly after that 2001 meeting, EMC acquired FilePool and launched it as the Centera product line. But CAS systems quickly ran into a serious roadblock: Conventional applications cannot read and write to unconventional storage systems like Centera. EMC pushed key software vendors (especially in the archiving space) to create special Centera interfaces, and the industry bogged down developing the XAM standard. Other companies, like Seven Ten Storage Software, jumped in to help with the translation from proprietary CAS interfaces, but the transition from legacy files and blocks to object storage has been long and slow.
Cloud Storage: Another Dimension
Meanwhile, in an alternate dimension, web developers realized they had a serious problem. They were developing applications that scaled massively, spanning servers and exhausting conventional filesystems. Conventional systems just wouldn’t cut the mustard.
Since they were soaking in web applications, these developers applied the lessons of web services to storage: Why not just make an HTTP connection and ask for an object by a unique ID rather than walk a filesystem tree? Why not encapsulate the “state” of this request in the request itself rather than make a lasting connection and association between the client and server?
Thus was born cloud storage, and it was bookseller Amazon who opened the floodgates with their 2006 introduction of a “Simple Storage Service” or S3. They allowed anyone to store and retrieve objects from their massive web services infrastructure. S3 and similar services from Rackspace, Nirvanix, and others, are special-purpose web servers, and their simple interfaces are wonderfully attractive to web developers. For example, this WordPress-based blog uses cloud storage to serve images to your browser!
Similarities in CAS and Cloud
Although developed from vastly-differing starting points, CAS and cloud storage are essentially similar: Both reject conventional blocks and files in favor of object storage; both organize data with metadata databases; both multiply and scale out. There is one other major similarity between CAS and cloud storage: Both are attractive to service providers.
Imagine you operate a business that stores data for customers. You would want a flexible infrastructure that would scale with demand and segment each “tenant” from others for security and performance. As we learned at StorageNetworks, conventional SAN and NAS systems just weren’t meant to work in this kind of environment. Whether operating an internal service or a public cloud, service providers require something entirely different.
Cloud storage was designed from the start with service providers in mind, embedding per-object and per-”bucket” security, scalability, and abstraction between hardware and clients. Although quite complex to design, cloud storage is amazingly simple to use, provided an application can interface with it.
CAS wasn’t designed like this. Systems like EMC’s Centera were created for the needs of applications like enterprise archiving, but secure storage of content and extreme scalability are critical here as well. But early CAS systems didn’t need simple web-style interfaces or extreme hardware abstraction. These were enterprise systems, after all.
The CAS/Cloud Colission
CAS wasn’t exactly successful. Although object storage found a niche in enterprise archiving, the enterprise storage world has mostly continued with blocks and files. The major storage vendors all have some kind of object storage, but most are repurposed NAS rather than dedicated CAS like the Centera.
Although much skepticism has been raised about cloud storage in the enterprise, its impact on application development cannot be denied. Indeed, the majority of developers are now focused on programming platforms that abstract both compute and storage from conventional operating systems. The next generation of applications will run in “platform as a service” environments first, and cloud storage is a key component.
Storage vendors are rapidly moving to rework their conventional systems for cloud use. Although block and file systems from 3PAR, NetApp, Isilon, Symantec, HDS, HP, and others are useful in cloud environments, unconventional CAS becomes more valuable here. This is where EMC, Mezeo, and Caringo (with Dell) shine, and why HDS bought Parascale, NetApp bought Bycast, and what Overland could do with MaxiScale. In the mean time, “gateway” products from Nasuni, Cirtas, StorSimple, Twin Strata, and Asigra are awfully interesting.
Stephen’s Stance
The storage revolution is coming, whether we in the industry are ready or not. Developers are voting with their feet, targeting cloud storage and application platforms rather than conventional filesystems. Although the market for cloud storage products is slow to develop, the cloud storage concept will eventually dominate the landscape.
It seems most likely that this revolution will decimate the storage industry as we know it today. Unable to push high-margin storage arrays into the ballooning cloud space, product vendors will see their market share eroded by service providers with no use for these expensive systems. Monolithic file and block will soldier on in the new legacy applications, but the action will inevitably slip away.
The likely winners will be those who can leverage commodity hardware for scale-out cloud storage use. The proliferation of cloud platforms will settle down, with a few gaining traction and the rest discarded. Then we will see companies like HP, Dell, and Oracle rise to lead the storage sales charts with massive volume shipments to service providers.
Disclosure: I used to work for StorageNetworks (which is now defunct) and Nirvanix.
Image credit: Barcelona Graffiti by Aeioux