Inefficiencies in today’s AI work environments
Time and Economic Costs
When thinking about relevant aspects to consider when improving performance in AI work environments, the two that first come to mind are the associated time and economic costs required to build AI systems. As it is well known today, Machine Learning and Deep Learning algorithms’ insatiable appetite is mainly responsible for these costs; consequently, the solution should be intrinsically tackled during the development process.
Timewise speaking, the ML-life-cycle requires hundreds if not thousands of iterations over the training samples so the algorithm can be well optimized since ML/DL architectures are memory heavy and training datasets are laborious to process. Pricewise speaking, most hardware AI acceleration methods that are used today, such as CPUs, GPUs, TPUs, FPGAs, or ASICs, for the sake of speeding up multilinear algebra and computer graphic operations, all have power consumption and use price associated.
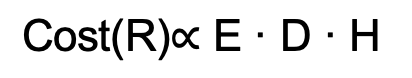
Moreover, these costs can exponentially increase if the model is brought to production, since these usually require to be updated every certain time so they can better generalize to real-world data (a process known as data flywheeling). An example of these inefficiencies can be seen in the development of OpenAI’s GPT-3 model, with an estimated cost of $12M for the completion of the training phase.
Lack of Standardization in Architectural Programming Environments
The more the AI field gets expanded with new research discoveries, new specialized techniques and frameworks are introduced to provide development solutions. Not only that, but nowadays the diversity in hardware is extremely large, from cloud to in-house solutions supplied by multiple vendors.
This open and broad configuration is beneficial for the final customer, but sometimes it also leads to scenarios of heterogeneous compute architectures and indirectly ends up limiting the freedom for AI developers when it comes to choosing tools for their AI environments. Under this context, dependency issues can arise between software and hardware that may impact directly in the product/research life cycle.
Software AI Accelerators
The AI community is quite familiar with the benefits of hardware accelerators, to the point of entirely depending on these when launching new experiments.
However, the “software AI accelerator” concept is relatively new but is starting to get a lot of attention with the increase in diversification of ML/DL applications, complexity of AI models, and size of datasets. In essence, software AI accelerators are a set of code optimization methods that under a fixed hardware setting are able to outperform traditional code in terms of runtime and energy consumption.
oneAPI – An Open Industry Initiative
Under these premises, the oneAPI initiative is catalogued as an industry-wide effort to drive a vision of software AI acceleration in contemplation of the aforementioned time and cost concerns related to heterogeneous hardware architectures. Specifically, it is brought to the users in the form of two software assets:
- oneAPI Spec: this is an open industry initiative that promotes the definition and standardization of a unified programming model for cross-architecture and AI accelerated computation. The main goal from this initiative is to move towards a standard-based programming model that is agnostic to hardware specifications, middleware and frameworks, where the developer is empowered to develop software without accelerator architectures dependencies. This standard is built around the concept of parallel application development, based on API programming and direct programming methodologies. As oneAPI is a project with open specifications, everyone can contribute to the oneAPI Spec repository.
- Intel oneAPI products: Alongside the oneAPI industry initiative, the Intel oneAPI products offer a wide set of advanced code compilers, porting, libraries, and analysis & debugging tools so the specifications can be applied to the Intel’s hardware products in combination of the popular programming languages such as Python, C++, Fortran, and OpenMP, among others. This enables the portion of code built on different frameworks (TensorFlow, PyTorch, MXNet, Scikit-learn, etc.) so it can run seamlessly in any hardware accelerator.
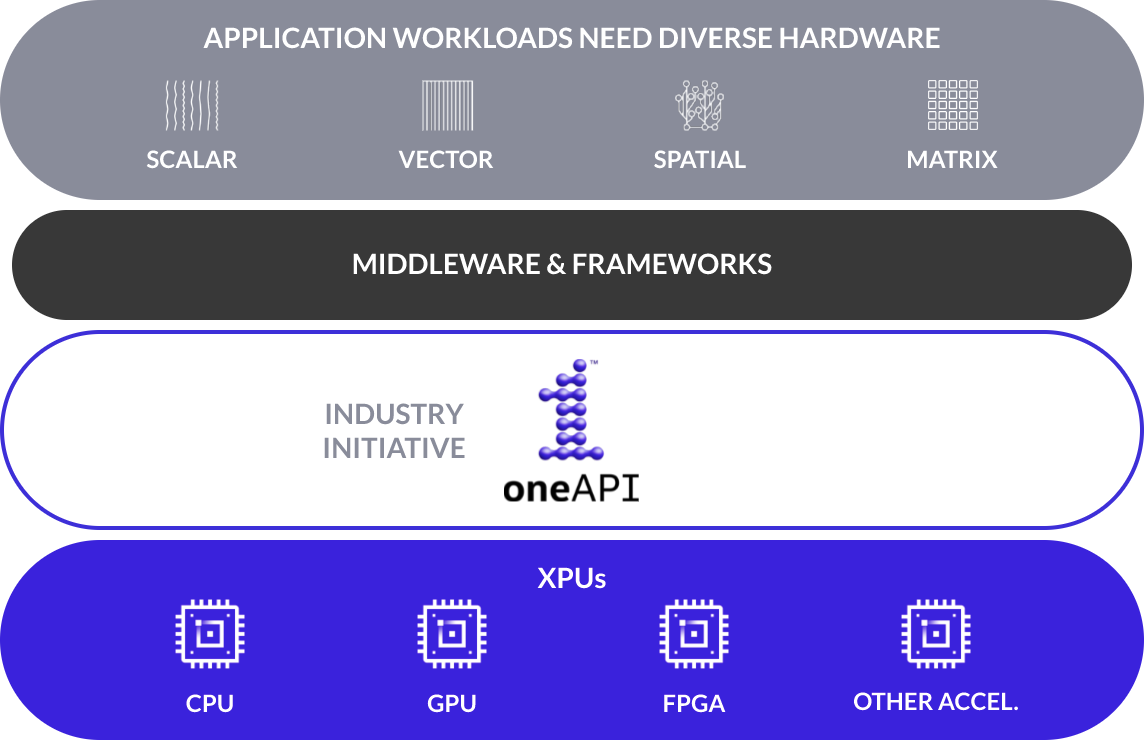
oneAPI-powered AI Tools and Framework Optimizations
The oneAPI programming model forms the foundation of Intel’s suite of AI tools and framework optimizations. oneAPI libraries help deliver 10x to 100x optimizations for popular frameworks and libraries in deep learning, machine learning, and big-data analytics, such as TensorFlow, PyTorch, Scikit-learn, XGBoost, Modin, and Apache Spark. These are complemented by a collection of tools for your end-to-end AI workflow, including data preparation, training, inference, deployment, and scaling.
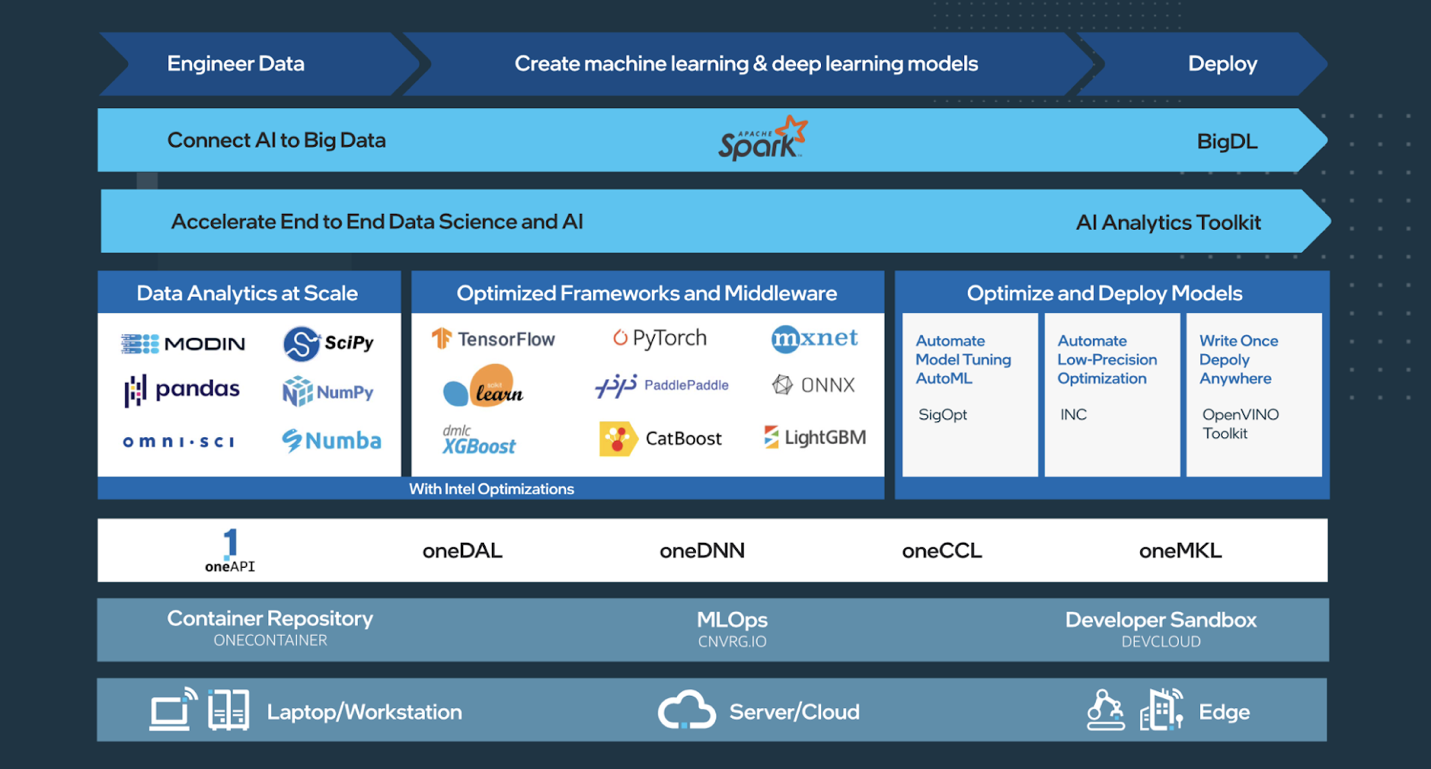
Intel® oneAPI AI Analytics Toolkit

Among a very diversified and comprehensive portfolio of AI products, Intel provides access to the oneAPI AI Analytics Toolkit, being one of the most relevant toolkits included in the oneAPI Product for Data Scientists, AI researchers and practitioners. It offers a wide set of tools to accelerate and optimize end-to-end ML/DL pipelines running on Intel architectures: from data preparation and ingestion, model training, inference, deployment and monitoring. This AI-specific toolkit brings to the user a set of Python tools and frameworks in order to provide interoperability for efficient model creation.
In order to get started, the toolkit can be run both in local or cloud (Intel’s oneAPI DevCloud) environments following the Getting Started samples.
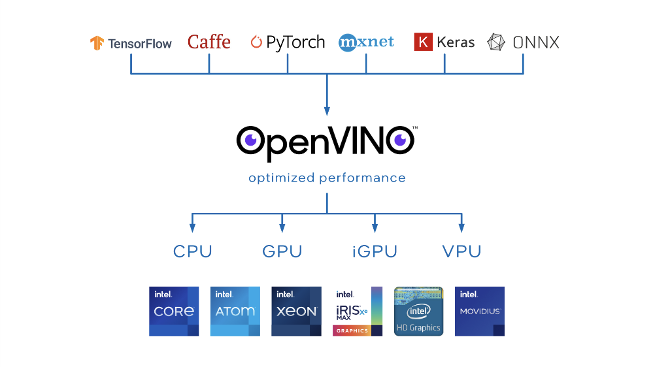
Intel® Distribution of OpenVINO™ Toolkit
OpenVINOTM helps deploy high-performance deep learning inference applications from device to cloud. The toolkit includes an optimizer, runtime, model repository, and development tools to tune and run comprehensive AI inference with a write-once, deploy-anywhere efficiency, across accelerators and environments.
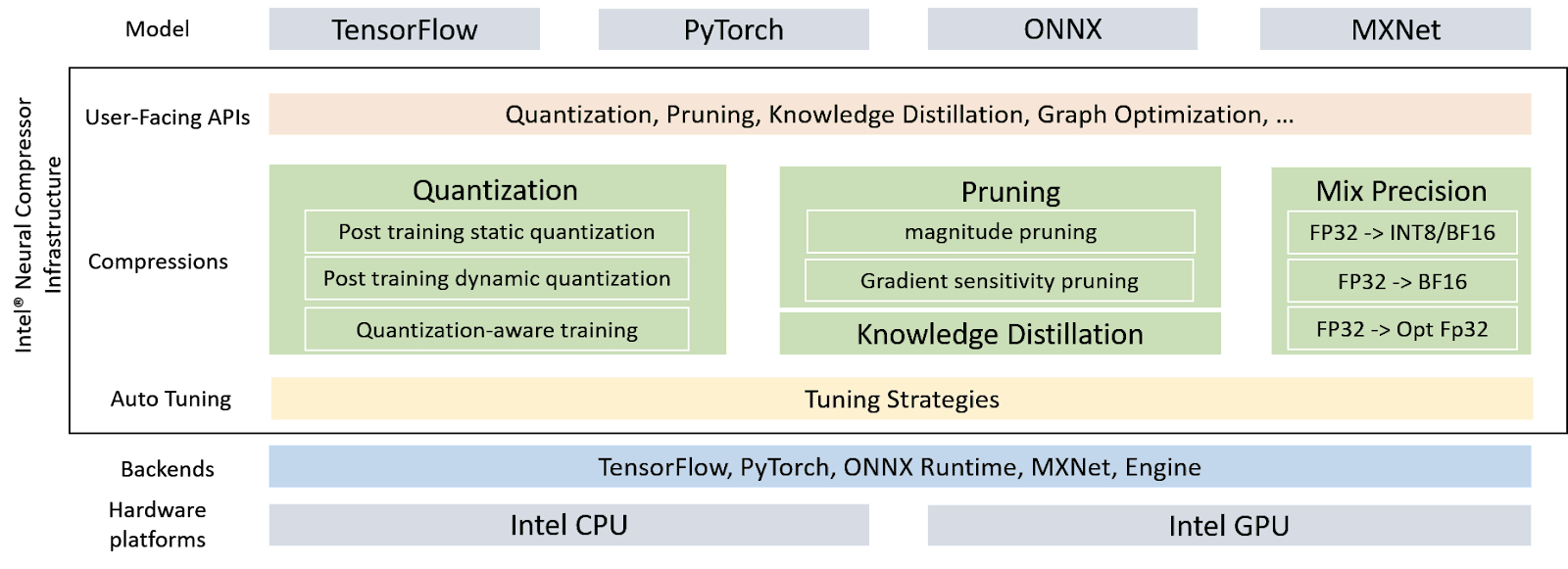
Intel Neural Compressor
One of the key components of the oneAPI Product AI suite to make existing code more efficient is the Intel Neural Compressor engine. This tool is responsible for performing distributed training and network compression techniques such as low-precision quantization, pruning, or knowledge distillation of the exposed code, always delivered across multiple deep learning frameworks.
TensorFlow & PyTorch Optimizations
All major AI frameworks including TensorFlow and PyTorch have been optimized by using oneAPI libraries such as Intel oneAPI Deep Neural Network Library (oneDNN). These Intel software optimizations help deliver drop-in and orders of magnitude performance gains over stock implementations without the need to learn new APIs. All these performance optimizations are also eventually up-streamed into the official default releases of the frameworks.
In collaboration with Google, Intel recently published a performance benchmarking study using TensorFlow 2.5 with oneDNN Optimizations which states that improvements of up to 3x and 2.4x were obtained in inference and training, respectively, using the 2nd Generation Intel® Xeon® Scalable processors.
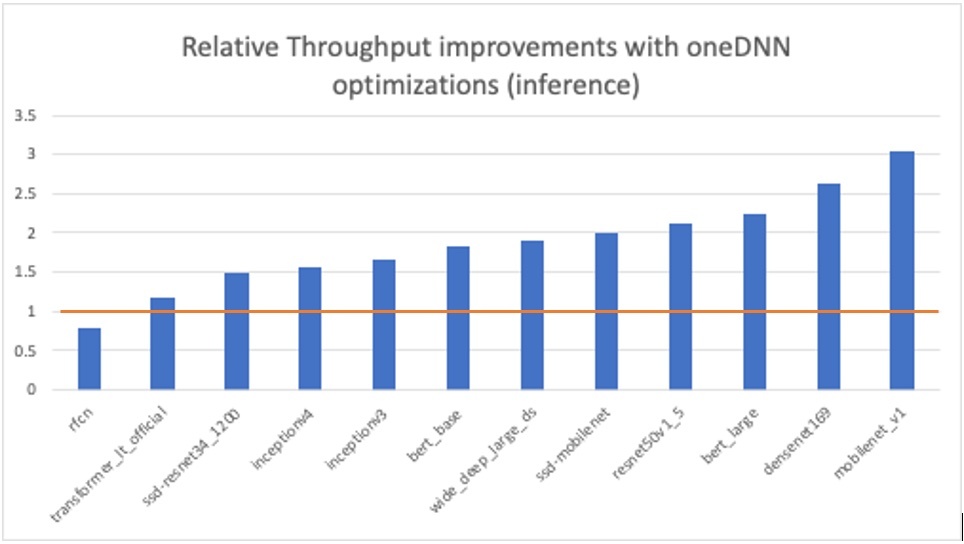
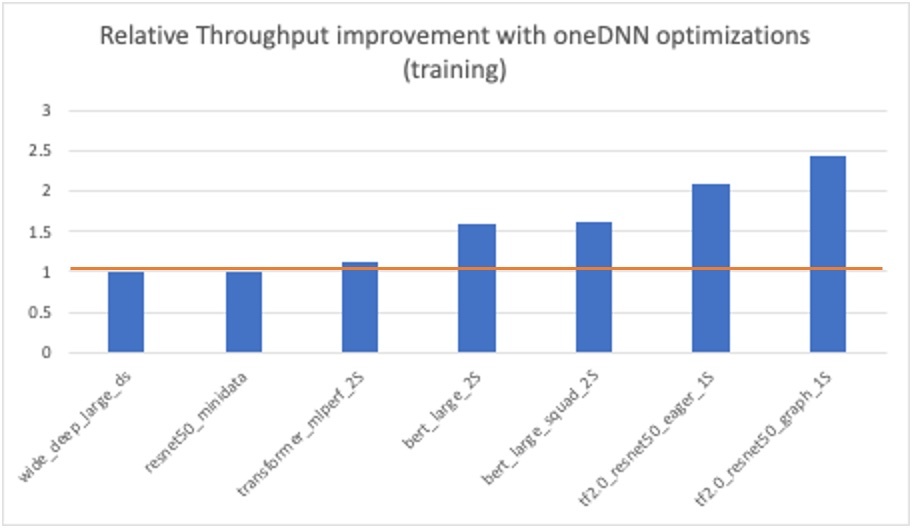
To enable default oneDNN Optimizations in TensorFlow v2.5, simply set the environment variables TF_ENABLE_ONEDNN_OPTS to 1.
Likewise with Facebook, Intel was able to accelerate PyTorch by up to 1.64x training and 2.85x inference performance improvements using the 3rd Generation Intel® Xeon® Scalable processors.
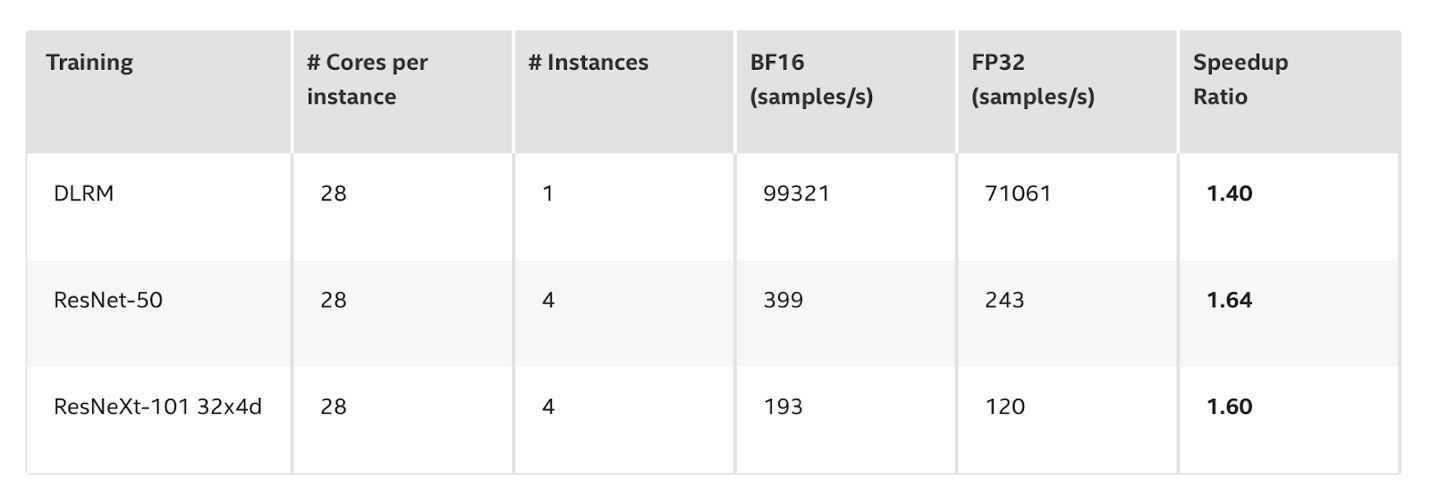
ModelZoo for Intel Architectures
The AI Analytics Toolkit provides access to the Model Zoo for Intel Architectures, that includes pre-trained models built on the most popular ML/DL architectures, datasets for image classification (ImageNet) and object detection and segmentation (COCO), and sample scripts for frameworks such as PyTorch and Tensorflow, so the proposed code can efficiently run on Intel® Xeon® Scalable processors. For further information, the benchmarking section shows a wide coverage of supported tasks and use cases.
Intel-Optimized Python Extensions
Along with the framework-specific optimizations, the AI Analytics Toolkit also aims to bring optimization and high-performance advances to the Python programming level. This can be translated into achieving greater performance by accelerating Python numerical and scientific packages such as NumPy, SciPy, Numba, Pandas by using Intel’s High Performance Libraries. Additionally, Data Parallel Python enables a standards-based development model for accelerated computing across accelerators while interoperating with the rest of the Python ecosystem. This way, users can supercharge their current Python workflow by using the Intel® Distribution for Python set of packages.
One of the most popular ML framework extensions is the Intel Extension for Scikit-learn, letting machine learning algorithms profit from the Intel® oneAPI Data Analytics Library (oneDAL) in order to speed up baseline executions up to 322.2x in training and 4,859.3x in inference using Intel® Xeon® Platinum processors.

Use Cases
As a consequence of the productivity and performance boosts provided by Intel® oneAPI tools and their seamless integration to current software stacks, they have been broadly adopted across different industries and research institutions in a record time since their public release.
Success Stories Highlights Include:
- Accenture reported a 10x cost reduction by replacing GPUs with CPUs for model inference.
- KFBIO, an AI-Powered world-leading digital pathology company, obtained 1.14x faster inference.
- Accrad, an AI Radiology company, inventors of CheXRad, a deep learning algorithm able to detect COVID19-affected samples from X-ray images, was able to speed up their labeling chest radiography tasks by 160x.
- AsiaInfo reduced their processing time by 3x and obtained a 2.5x model accuracy when building an AI-based solution to optimize and accelerate 5G networks.
A featured use cases selection is included below:
- Samsung Medison uses oneAPI to power obstetric ultrasound systems [article] [video]
- Intel & Facebook accelerate PyTorch performance [article]
- Acceleration for HPC & AI inferencing at CERN [article]
- LAIKA studios & Intel join forces to expand what’s possible in stop-motion filmmaking [article][video]
- Accrad AI-based Solution Helps Accelerate Lung Disease Diagnosis [solution brief]
Final Thoughts
From research institutions, small AI companies and startups, to well consolidated companies, the shared perspective of all these rely on granting AI developers and practitioners access to the right AI tools and resources so they can complete their work in the most effective manner.
The maturity stage that the AI ecosystem sits in today requires to start exploiting AI hardware and software accelerators in close collaboration. We must transform the current development of AI solutions so it can be efficiently achieved not just from a technical point of view, but also environmentally when considering the carbon emissions and electricity usage derived from it.
You can get free access to Intel® oneAPI on Intel DevCloud, or download it from software.intel.com/oneapi. Learn more about Intel’s AI software offerings at software.intel.com/ai.
References:



