The future of Intel’s Optane 3D XPoint persistent memory technology has been in the news a lot lately, with Micron announcing it will exit the 3D XPoint manufacturing business. Much of the commentary has declared that Optane, and persistent memory with it, are now dead. That would be a big deal for MemVerge, which closely partners with Intel to use Optane as the hardware backing for its Big Memory software, if it were true.
But I don’t think it is.
Jim Handy’s analysis is well worth reading to understand why. As he points out, PMEM is cheaper than DRAM, while MRAM and ReRAM are much more expensive than DRAM. Z-NAND and XL-FLASH don’t have the DIMM-style bandwidth and latency characteristics of Optane.
Optane is neatly nestled in a nice niche between DRAM and SSDs, and it provides the first practical step towards the Big Memory architecture championed by MemVerge.
A Bridge to Tomorrow
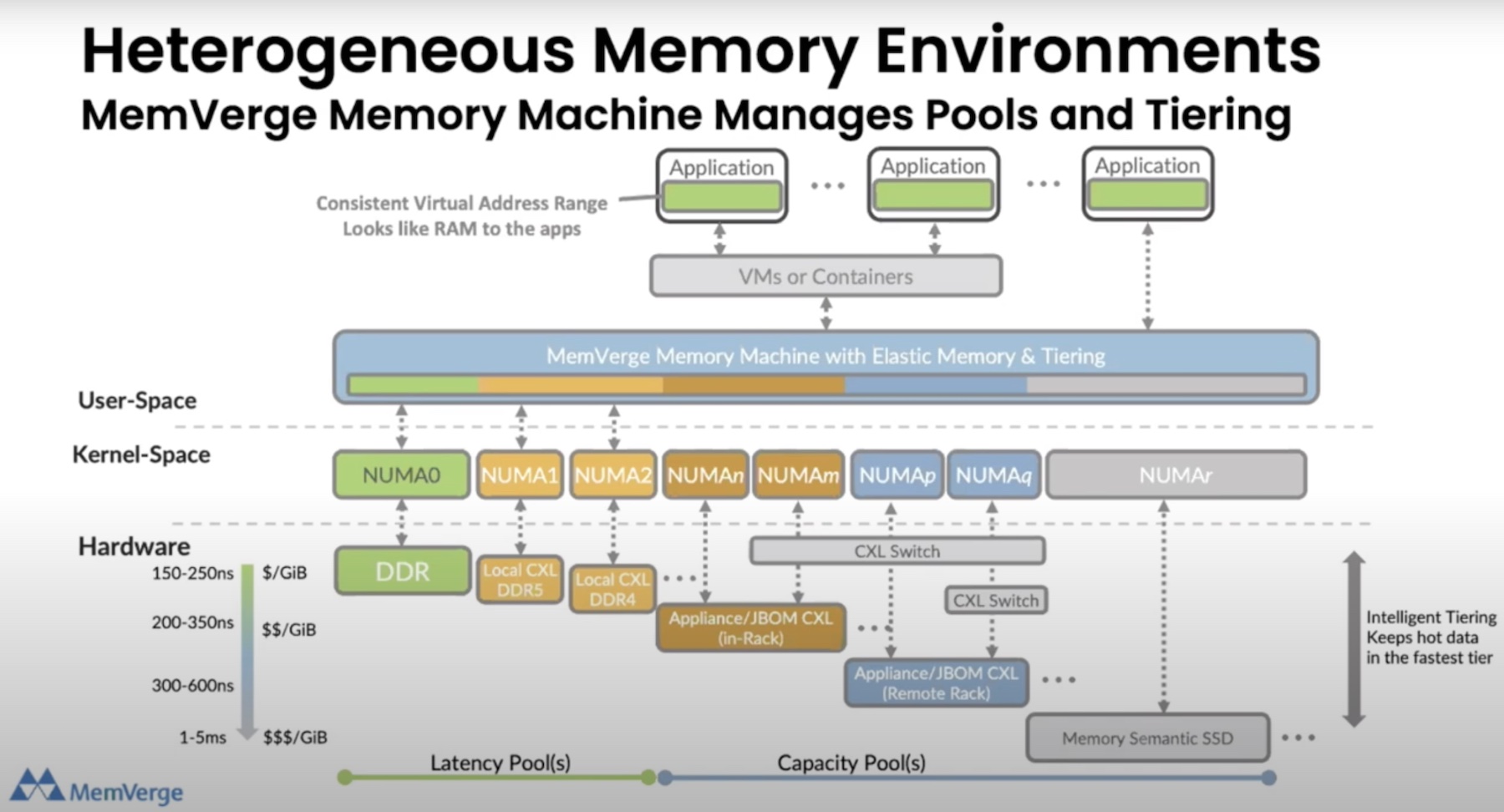
A major challenge for the adoption of Optane has been the software changes required to take advantage of it. Persistent memory functions differently from DRAM and needs software to change how it talks to memory. MemVerge’s approach here has much to recommend it. Rather than requiring programmers to completely change the way they write software to get the benefits of big memory, MemVerge’s Memory Machine can provide many of the benefits of persistent memory to existing programs, without major changes.
Adding memory-based rapid snapshot and restore functionality to an existing data processing pipeline and taking restore times from tens of minutes to mere seconds, is a compelling proposition. Data scientists are tired of waiting around for ages between runs because the infrastructure can’t keep up.
When setup times are long, mistakes are very costly indeed. Rapid cycle times increase the number of experiments you can run. Shipping smaller amounts more often is a hallmark of modern software development, but this approach is strangled by the glacial slowness of even SSD I/O compared to doing everything in-memory.
And while those working with large datasets are already well aware of the limits of small memory compared to big memory, once we adopt big memory techniques we will not merely have a faster horse, but something qualitatively new.
MemVerge is the missing piece required for Optane to demonstrate concrete value today for large, expensive problems that can’t wait for new software to maybe arrive soon.
Unlocking the Future
The adoption of technology depends on humans, not technology. And human nature hasn’t changed much in thousands of years.
If we look at the way technology adoption happened in the past, we can get an idea of the characteristics of how big memory is likely to play out. VMware was adopted because it provided a clear, if boring, benefit at the time: workload consolidation and economies of scale. But that was not all it did. It also opened up new possibilities: virtual machines were software that could be moved around dynamically in ways that physical servers could not. Disaster recovery of workloads became a major selling point. Resource allocation within and across clusters made infrastructure more dynamic and software-defined.
Similarly, there were real advantages to the cloud that some people embraced enthusiastically with both hands from the very beginning. But most people took a little longer to get comfortable with what is a completely different way of thinking about the world. Cloud is not a location or a technology, so much as it is a state of mind.
With VMware and the cloud, we have used software to free us from the restrictions of physical infrastructure. Why not use an API to create a new virtual machine running in someone else’s data center whenever you need one? Why not dynamically reconfigure resources under autonomous software control in response to changing demands?
Why not do the same for memory?
Software-Defined Memory
MemVerge’s approach of using software to provide a bridge from how programs use memory today to the software-defined memory pools of the future has one key advantage: flexibility. The rise of alternate memory technologies to Optane, and promising interconnects like Compute Express Link (CXL), works in MemVerge’s favor. MemVerge, like VMware before it, can abstract the physical nature of the specific memory technology away while providing useful benefits to existing software today as well as a bridge to the very different software of tomorrow.
I would argue that while we can clearly predict some of the future benefits of big memory techniques, we will also inevitably be surprised by what people decide to do with them. Just as the advent of cloud computing has ushered in an explosion of new ways of writing software and operating infrastructure, so too will large pools of persistent memory allow us to do things that simply aren’t possible today. Many of them haven’t even been imagined yet.