In my previous post on data management, we evaluated how organizations typically evolve to use to include cloud resources, and how tools can be used to support those new public resources as well as legacy on-prem resources. After a clear process for data management is defined and a solution is put in place to support the process, the next iteration of cloud adoption typically revolves around the ability to grab more value out of the chosen solutions.
Cake? I want cake.
Organizational value can be defined in two modes. There are either cost cutting value propositions or innovation enablement value propositions. Leveraging a data management platform that covers data management for both on-prem resources and cloud-based IaaS instances provides the ability to cut the need for multiple tools as discussed earlier. This aligns with the cost cutting organizational value because we’re eliminating tools in this scenario.
Another great example that I regularly see, is the attempt to cut into CapEx costs around disaster recovery implementations. Many see disaster recovery as a sunken ship of cost that’s simply a compulsory exercise in ensuring that in the event of a critical failure your business can continue to operate. In an earlier post, I discussed using Rubrik to protect archival data in the cloud. Here, we’ll go one step further and consider how to use Rubrik to provide recovery for a tier of your organization’s apps in the Public cloud.
Pilot-light DR?
When we look at DR strategies, while necessary, no organization run’s out to say YES!!!, let’s spend a ton of money on infrastructure, licensing, and operating cost on an environment that we’ll never use! Instead, DR environments become a sunk cost, where old gear may be recycled into additional use, or even worse where org’s just say nope, we don’t need to spend money there (trust me, I’ve worked at one of those).
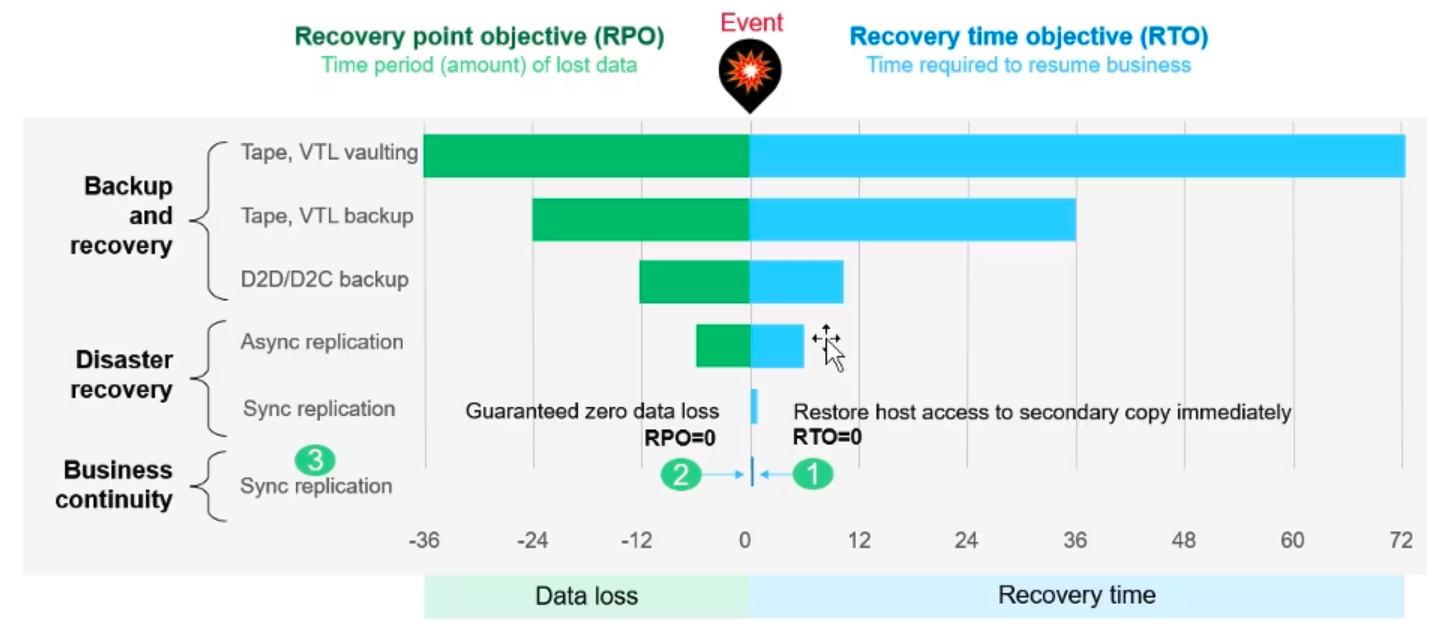
Luckily, when looking to leverage the Rubrik platform for recovery, Rubrik offers the capability to recover existing workloads to a public cloud endpoint. By leveraging CloudOn capabilities in the Alta release of the Rubrik platform, architects are free to consider leveraging recovery capabilities by powering on instances with your VM’s data in AWS. Rubrik addresses the conversion from VMware VM to Amazon Instance for you. For companies with RTO and RPO requirements that will allow for this option, it’s possible to leverage this feature to recover without the need of having a Rubrik appliance running in the cloud full time. This diagram shows what the process looks like logically during replication to AWS:

During an example vSphere storage disaster, recovery is made on instances in the public cloud:

Keep the change!
One challenge with any recovery scenario is always related to change rate, and this use case is no different. While Rubrik does a good job at only sending the blocks that have changed over the wire, each application stack will have varying amounts of data change. Your data mileage and change rate may vary from application to application, and it’s not okay to just think that your workload is probably just average. Understand that your limitation may be the connectivity between your site and the public cloud. In this scenario, it’s always a good idea to get a partner or a vendor involved to help you understand and model your rate of change. There are a ton of tools and a ton of partners willing to assist with this task.
Defining Tiers for Recovery
Strategically, I recommend looking at data recovery in tiers that you map your applications into. Perhaps tier one and two applications are recovered in a secondary datacenter from a Rubrik cluster that’s replicated to that site. Tier three applications might be recovered leveraging a public cloud endpoint to reduce the need to purchase hardware to support the recovery pattern. Regardless of the level of criticality of your application, understanding RPO/RTO and then ensuring each of your apps are placed into a bucket that meets those requirements is critical to ensure that there are no resume generating events in the event a disaster does happen. Here’s an example of how Tiers might be broken out in an environment that’s just starting to get a grasp on public cloud:

Notice how critical Tier-1 apps are still replicated between datacenters while this org is gaining momentum for using the cloud by leveraging cloud based recovery for Tier-3. This is a small and simple step towards enablement of public cloud, but an easy, and low-risk step to take.
Practice, Practice, Practice
I think this next part goes without saying, but I’ll say it anyhow: Even if you think that you’ve designed an appropriate environment for your application’s recovery and that you’re confident that your application can be recovered, test it out just to be sure. You’d be surprised what happens when you actually take the time to test a recovery. It’s important to have a confident grasp on how everything works and what to expect during recovery and making sure that you’re prepared for the event is critical. In this example, because you’re working with two differing platforms there will likely be some time differences in your ability to instantiate a vSphere Virtual Machine directly from a Rubrik cluster vs an AWS instance that you should be aware of. These are exactly the things that you test and be ready for when it’s go time.
So we’ve had our cake, let’s make sure that we get to eat it too. Aside from cost cutting, how can we use this type of pattern to enable innovation? What’s that a backup appliance that does more than just backs my stuff up? Let’s dive into the use case.
Having Your Cake and Eating it too!
For nearly this whole post we’ve discussed how to place apps in groups, test the recovery, and rationalize what apps should be recovered and where they should be based on SLA Tiers. This exact same framework can be leveraged to give our application teams exactly the thing that many of them want, access to a production-like copy of your data. With a little bit of networking and automation magic, it’s possible to leverage the Rubrik platform to bring up an instance of your businesses’ application on a Rubrik appliance itself in your datacenter, or in a public cloud provider. To a developer this is gold! To an automation engineer, it’s simple because by default the ability to perform these actions is all natively exposed by a feature-rich REST-API that Rubrik has deployed for all their features from day one. In general, if there is a platform feature in Rubrik, there’s an API call for it.
So how do you market this to your dev team? It’s really as simple as sitting down with your developers and understanding the requirements of the data that they might want to test. From there, figuring out how to properly isolate the instance of the application from the rest of the environment is the next challenge (here is a HUGE argument for considering a public cloud endpoint that’s network isolated from production). After considering these two things, it’s onto integrating that REST call into your development team’s CI/CD tooling and giving the developers’ access to bring up copies of the appropriate stack when needed. A strong warning here, be sure that whatever systems that you deploy are also removed as a part of the development lifecycle, you don’t want a million copies of your app consuming AWS or on-prem resources when they aren’t needed. Make sure that if your developers are bringing up images leveraging their orchestration tooling that you’re working with them to ensure that they clean up after themselves by removing un-needed copies.
Wrapping up
There you have it. These are just some of the basic ways that I’ve seen customers start the journey to leveraging public cloud for their enterprise datacenters as it relates to data management. Hopefully, we’ve covered a couple of use cases that get you thinking about how data management is just a little more than backing your stuff up. Hopefully, you’ve picked up a couple of potential workflows that could work for your business in the future. Until next time, don’t back up, go forward!
![]() This post is part of a Rubrik Tech Talk series. For more information on this topic, please see the rest of the series HERE. To learn more about Rubrik, please visit https://www.Rubrik.com/.
This post is part of a Rubrik Tech Talk series. For more information on this topic, please see the rest of the series HERE. To learn more about Rubrik, please visit https://www.Rubrik.com/.