Welcome to Phase 2 of the average organization’s onboarding of a public cloud platform. As discussed in my earlier post, phase one normally relates to how an organization begins to consume very basic public cloud services.
By this point in a cloud journey, most are using services like Microsoft Office 365 or Google Apps to help offload typical messaging and productivity overhead from an organization. Along with these SaaS-based offerings, many have also implemented a public cloud object storage offering. Object storage is a great first step into public cloud services, it’s easy to understand, cheap the experiment with, and secure if you follow your provider’s documentation guidelines. In my previous post, we covered how you can use object storage for the archival needs of a data management platform like Rubrik. These initial steps into the public cloud arena allow teams to familiarize themselves with cloud resources. Moving forward, momentum typically gathers for the enablement of other cloud resources.
Looking back to help with the vision of the future:
Phase Two of a typical cloud journey usually starts with a retrospective on phase one highlighting what can be better in future implementations. As organizations adopt public cloud resources, they realize that security and compliance requirements are still just a present in the public version of their data center.
As momentum for consuming public cloud resources gains traction and more business services begin to rely on public cloud offerings to execute critical business transactions, security and compliance concerns inevitably become higher. While all who are on the public cloud journey should look at security, governance, and compliance requirements on day one, many start out as a need that was executed on by part of the organization that wasn’t considering these key areas. Couple this pattern with the fact that the offerings now support a larger amount of the businesses’ profitability potential, all the sudden it’s now subject to additional scrutiny. As a result, re-evaluation of security and compliance postures as they relate to these services is commonly a part of this second part of the cloud journey.
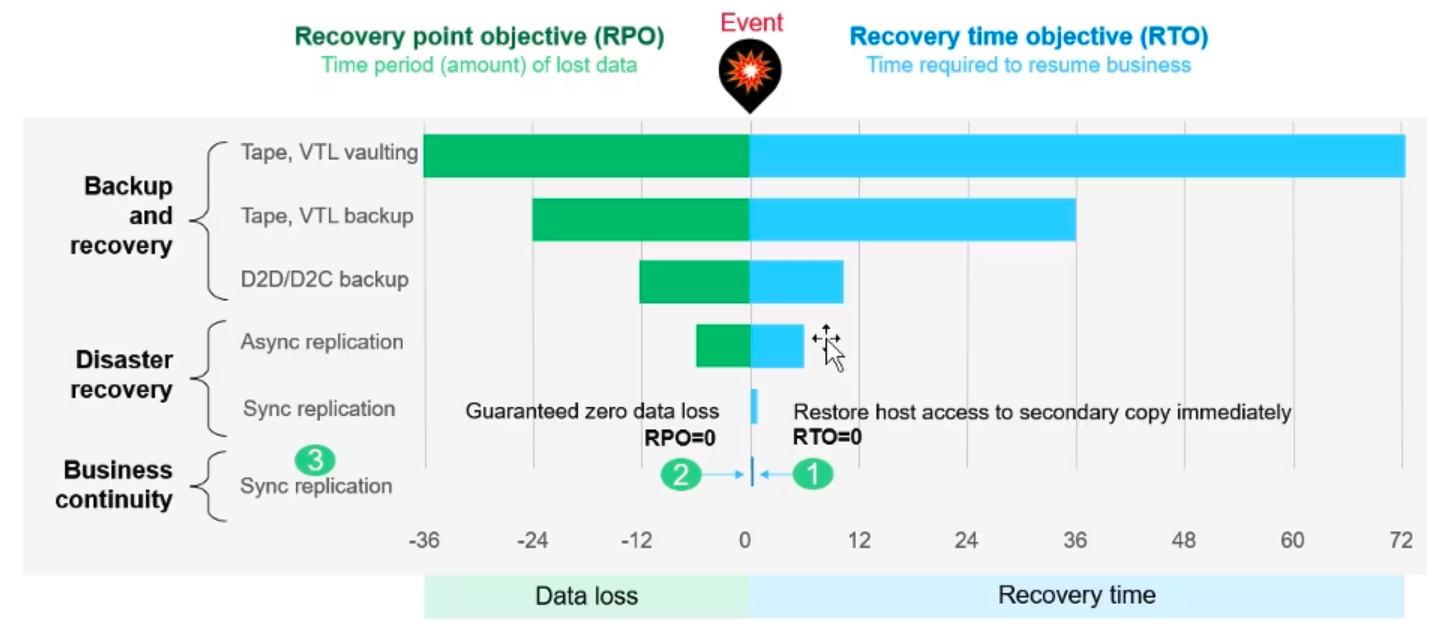
In the case of data management, this means understanding things like data encryption, encryption key management, data lifecycle, user access control, RTO and RPO profiles and how they relate to all the public cloud services that are being on-boarded. While this second phase is where organizations usually start this evaluation process, it’s important to know that this process is cyclical for every new service offering that’s added to an organization’s tool belt.
What it means to step out of a software ecosystem:
VMware, for many, is the platform that is used to host the most critical on-premises workloads. While many will argue that several other players in the space have begun to commoditize the concepts that have made VMware a mainstay in data centers (vMotion / HA) the fact remains that for many, the most critical on-premises workloads still run on VMware vSphere. What does make VMware great is the number of ecosystem partners that support the platform. VMware customers take for granted that if they want to find a vendor for data management, it’s easy to look around to find a great one like Rubrik. The same is true for nearly every other space, monitoring, capacity management, etc.
As a part of phase two, many organizations start to onboard public cloud services for compute and related block storage services. Commissioning these services, which have clear parallels in the typical enterprise data centers, bring the usual enterprise questions into play. These process driven questions have been around since the dawn of systems. How do I manage my asset? How do I monitor my asset? How do I ensure that in the event of a problem I can recover from failure? In addressing these questions, and having the challenge of leveraging both the new platform and the old platform, engineers and architects are forced to work to define solutions that work for both. In the even that tools aren’t available to support both, tool sprawl becomes an issue. So where does that leave us? Unfortunately, it leaves us in a place where we must make decisions about supporting multiple platforms in the most efficient way possible.
How can we combat tool sprawl as a part of our cloud backup strategy?
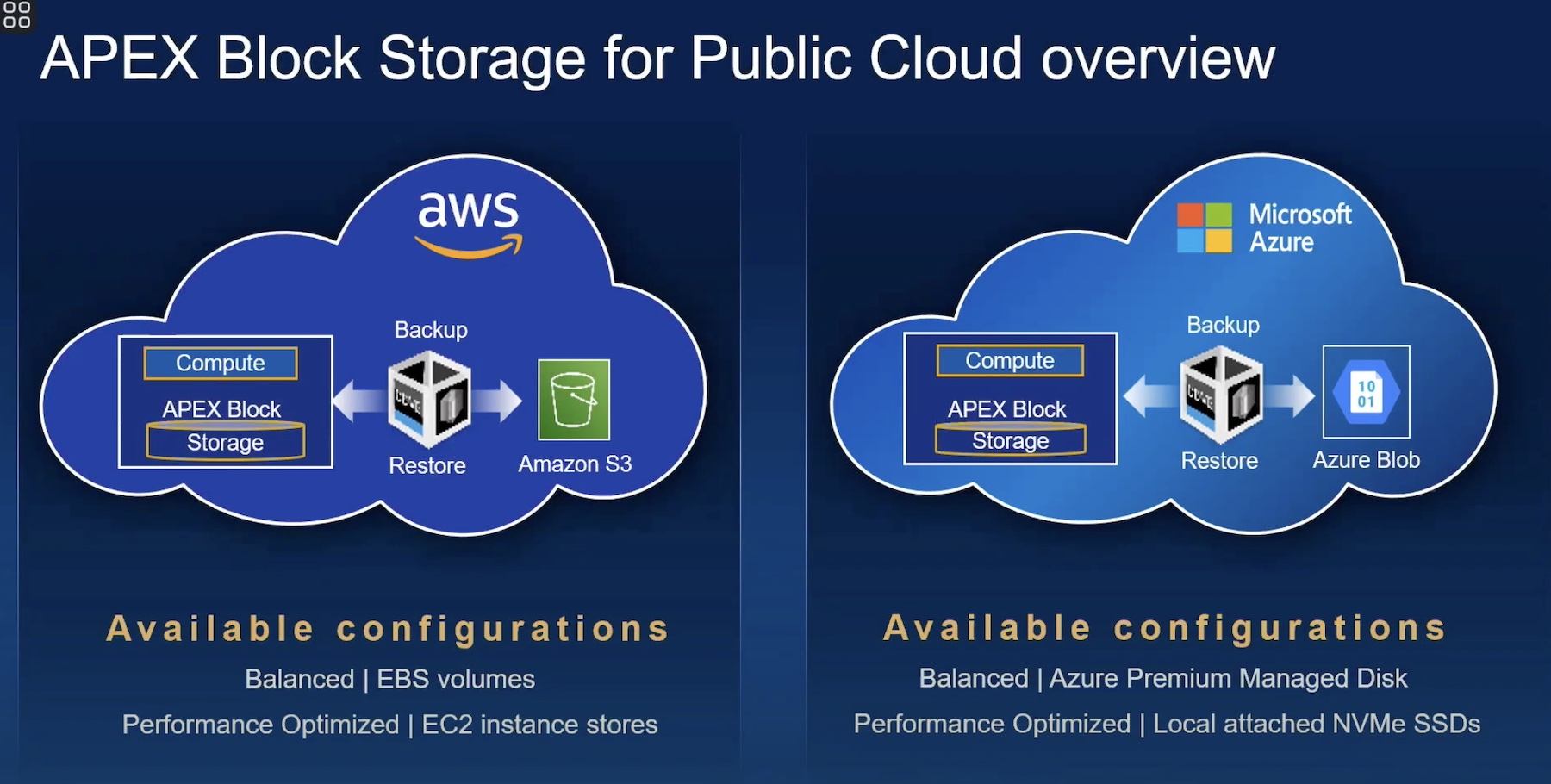
A byproduct of choosing to support a new compute service provider (not simply a public cloud problem) is stepping out of the comfy space where there are many choices of partners to meet your needs into an area where you’re building your own compatibility matrix. Building a “choose your own adventure” compatibility matrix among products complicates management of systems and adds work for support engineers. If due-diligence isn’t performed around the selection of tools and definition of these processes extra work can be created. Luckily in the backup space, Rubrik has this problem covered. Rubrik can natively backup VMware virtual machines and then by leveraging a small operating system based agent can also backup and recover the operating systems of your public cloud AWS instances or Azure VMs. The solution ends up logically looking like this when leveraging VMware for on-prem workloads and AWS for public cloud workloads:

The brilliant part is that by leveraging a solution that can cover both your existing on-premises workloads and also your public cloud data management requirements, we’re easing the onboarding of this new platform for compute consumption. Are there platforms out there that natively backup AWS instances to S3 storage? Sure, but a solution like this gives us the capability to leverage a known platform that also integrates with what the operations teams normally leverage to help make our cloud strategy just a bit more seamless. I hope that this gets you thinking about tooling. As you look at your data center food groups (storage, networking, compute, recovery) be thinking how you can help your company be agile in the face of changes like these.
On-premises, in the cloud, where should a backup stack exist?
This logical view of a backup strategy considers an SLA policy that maps virtual machine and public cloud instance assets to a “Backup Appliance.” I use the term appliance in this context because the notion of the Rubrik platform being an appliance may be somewhat misleading. In this use case, you have the ability to run the Rubrik platform in a physical configuration or as a cluster of instances running in a public cloud provider. Understanding where this stack should live is a vital part of your cloud strategy when it comes to minimizing cloud costs and maximizing backup performance. When leveraging Rubrik to backup instances in a public cloud provider, it makes a fair bit of sense to use a software-based stack that’s close to your application data itself. The Rubrik platform gives us this ability.
From conceptual idea to proof of concept.
The best part of leveraging the public cloud for a solution like this is that running a “Proof of Concept” of a solution is easy. Like any use case, you pay for only what you consume. To get going, you’ll need to work with Rubrik to request a copy of their images for the Rubrik cloud software (access to an AMI in AWS) and then configure a cluster of AWS instances or Azure VMs to support it. From here, you’ll be testing your ability to backup cloud resources using cloud resources. While the instances are pretty beefy, if you’re just running a PoC it’s easy to power them up for a short duration and then power off or delete them.
Considering costs when moving beyond a PoC
If you’re architecting a cloud-based solution, you always want to think about how to optimize your consumption costs. If you’re leveraging AWS for your platform, and you know that your backups stack will up and running 24×7, you should consider leveraging pre-purchased reserved instances. Whether you choose reserved instances or not; it’s important to understand that you have purchasing choices that impact overall cost when bringing a service online. Frequently there are better options to the standard hourly consumption cost model. This use case is an excellent example. I’ve included a quick hit at what that costing might look like using three-year reserved instances with the Amazon Cost calculator here.
Is backing up my cloud instances to the same cloud provider an anti-pattern?
If you were thinking this reading the previous sections, good work. Yes, you’re spot on. When it comes to architecting any solution, it’s important to call out risks just like this one. In this case, we’re putting all of our chickens (and backups) into a single basket. That said, it’s surely possible to ship copies of your Rubrik cloud platform’s data to an on-premises Rubrik platform to account for the risk of a complete network or cloud meltdown.
In this post, we’ve covered how to consider architecting your data management platform to manage and recover both on-premises and public cloud resources. In the next part of the series, we’ll get into leveraging the Rubrik platform to support more advanced recovery and even development based use cases.
![]() This post is part of a Rubrik Tech Talk series. For more information on this topic, please see the rest of the series HERE. To learn more about Rubrik, please visit https://www.Rubrik.com/.
This post is part of a Rubrik Tech Talk series. For more information on this topic, please see the rest of the series HERE. To learn more about Rubrik, please visit https://www.Rubrik.com/.