
As an old-school database administrator (DBA), I’ve overseen more than my share of migrations between database platforms, both on-premises and in the cloud. The projects required considerable planning, experimentation, and zero tolerance for data loss.
Fortunately, they were all successful because modern databases have robust backup and recovery mechanisms in addition to sophisticated transaction logging to guarantee data synchronicity during transference.
Databases depend on block storage for data retention, and that moreover enables DBAs to easily ascertain accidental corruptions, if any, within a single block.
But when dealing with data that’s read and written at the application level – often stored within thousands, even millions of individual files and retained within object storage – migrating entire applications without losing any data while keeping them executing is a much trickier challenge. The process can consume days or even weeks as files containing terabytes of critical application data are ported between source and target environments.
Consonance, Security, and Chain of Custody
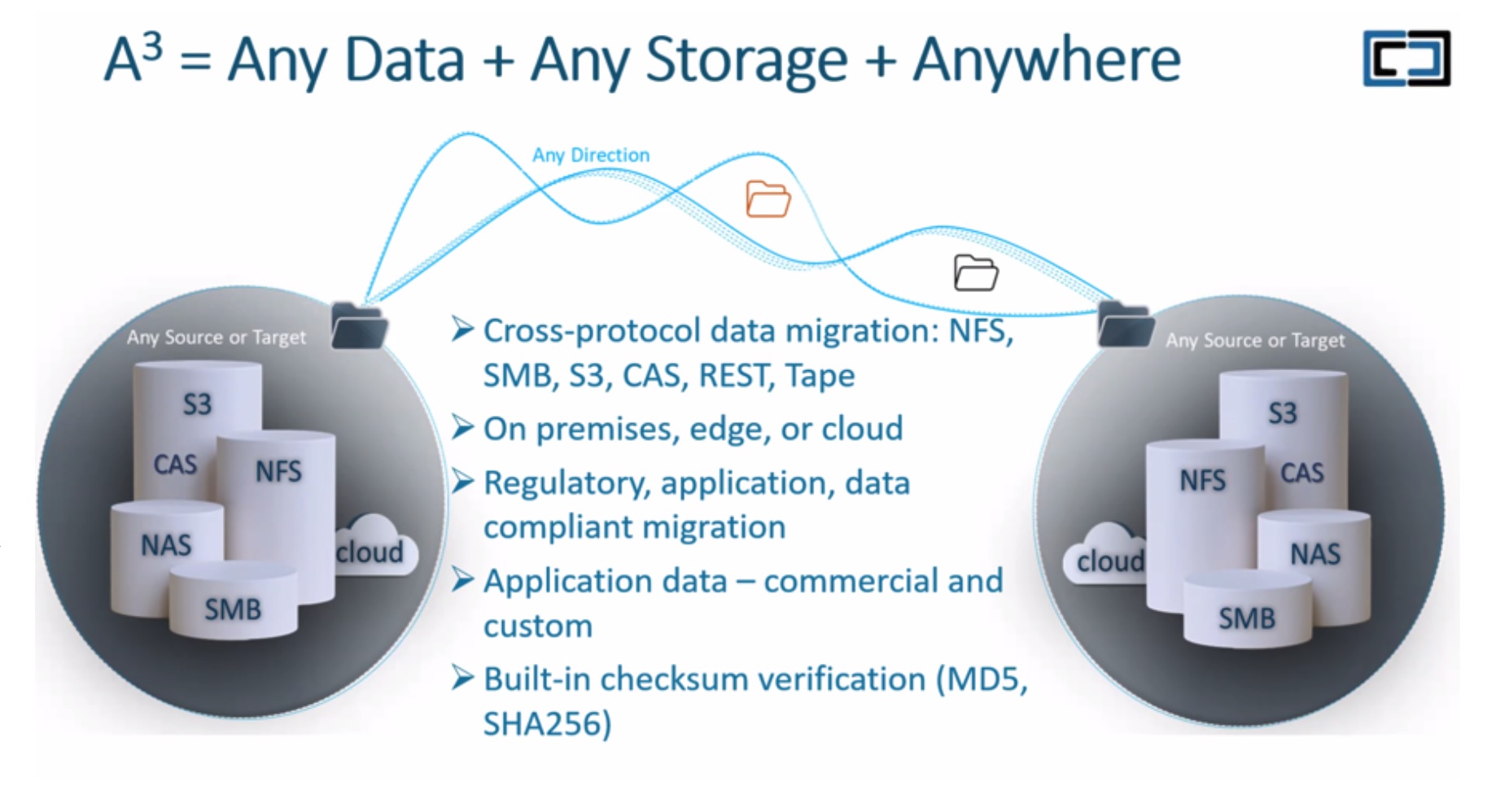
Any migration process must guarantee application consonance, in other words, seamless execution while the app’s underlying data resides at the source or target. Consonance must be maintained regardless of the file’s current location – be it a local file storage or a cloud “bucket”, and the access method, whether using REST APIs or application-specific protocols.
But consonance is only the first concern. Data that’s encrypted for security purposes must remain encrypted during transfers. In cases of extremely sensitive data, it must be seen that only the migration tool touches it, so that a legal chain of custody is maintained.
Even more problematic is that it can take considerable computing power and reliable networking to migrate application files at speed, and that could mean compromising current hardware and bandwidth at the source right in the middle of crucial business cycles.
DATAFORGE: A Migration Solution, Cubed
I recently came to know about a comprehensive solution that squarely addresses these data migration challenges. From Noemi Greyzdorf (VP ofOperations) and Massimo Yezzi (CTO) of Interlock, I heard about DATAFORGE, a solution designed to satisfy the potentially tricky and voluminous object migration requirements.
Interlock calls DATAFORGE their A-cubed (A3) solution for object migration. Designed to move any data between any storage, anywhere, it guarantees application consonance while handling all the other aforementioned issues.
DATAFORGE currently comes in two flavors:
- For IT teams that are overwhelmed with work, Interlock offers DATAFORGE Classic. DATAFORGE Classic comes with Interlock’s team of experienced and certified migration engineers who handle the solution deployment and migration process end to end for enterprises.
- For organizations that can spare resources, Interlock allows members of the staff to train to be DATAFORGE-certified migration engineers and manage the migration in-house.
Nuts and Bolts
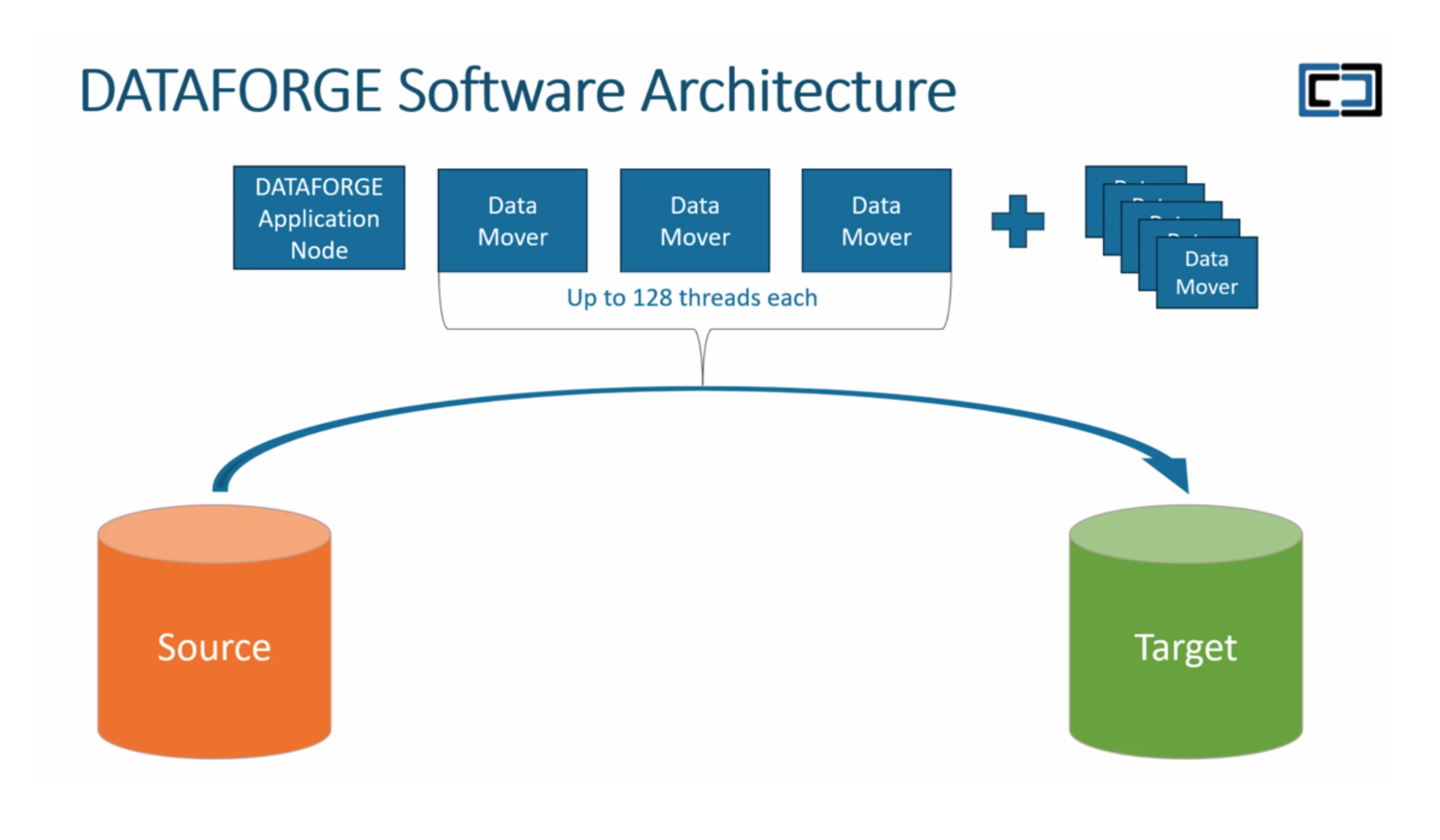
At its heart, DATAFORGE uses a series of Data Movers – usually a VMware virtual machines configured via ESXi – and managed by a single DATAFORGE application node. As the name implies, Data Movers move application files from source to target, but what makes them unique is Interlock’s proprietary software.
As Data Movers continually copy data to the target system, the apps continue to communicate with the files stored at the source until cutover is completed at the target, thus ensuring application consonance. DATAFORGE remains outside the migration path, and since the Data Movers migrate data at the storage level only, this keeps them focused on completing the process as rapidly as possible.
DATAFORGE provides a web-based UI that constantly monitors the migration progress, and includes the ability to migrate files via multi-threaded migration processes.
Migration engineers can use DATAFORGE’s built-in performance scheduler to control the number of threads each Data Mover is using allowing them to throttle migration during peak application business hours, and ramp up migration processing during off-peak periods.
Migration is not just about moving files. It’s also crucial to maintain individual file’s metadata for handling security and retention requirements post-migration. Data Mover processes can be tuned to accommodate files whose contents rarely change – long-archived logs, documents, or images – that need to be retained historically for regulatory purposes. Data Movers interrogate those files’ metadata less frequently, and focus more efforts on volatile ones.
Maintaining Consonance Regardless of Format
Maintaining application consonance during migration is trickier than it appears. For one, the application may use several different connection methods to read from or write data to files. They may be using a vendor-defined REST API or even content-addressable storage (CAS) if there are specific security requirements to access and write data via cryptographic means.
Data within the files themselves are likely to be stored in any one of a plethora of proprietary formats: images (JPEG, JIFF, PNG), audio-visual recordings (MP4, M4A), geographic information systems (GeoJSON, GML, KML), standard documents (JSON, XML), and so on.
DATAFORGE’s software is designed to handle this seamlessly regardless of the file format. If required, Interlock can even build a custom application connector so that it appears to the application as though it had written data directly to the target storage system.
Never Break the Chain
Maintaining the chain of custody for any secured data stored within the object file system is a crucial requisite. An encrypted file must remain so during the transfer process without the need to first decrypt it. Otherwise, data might be corrupted, to say nothing of the risks of security regulation violation through accidental glancing of the data.
DATAFORGE’s software calculates a hash on every bit comprising the file as the transfer proceeds, meaning it can guarantee that the file and its metadata is never modified while migrating. Interlock guarantees that its chain of custody reporting is solid enough to stand up in a court of law.

So How Fast is Fast?
Interlock says that as long as there are adequate resources – essentially, a sufficient number of Data Movers and a robust network connectivity between source and target environments – a migration engineer should be able to move over 20 terabytes of files per day, and up to a billion files per week. That’s a pretty bold claim, but not one that is unsupported by successful customer stories:
- The closing of an on-premises datacenter necessitated a complete migration to AWS S3 buckets in the cloud. This required DATAFORGE to migrate 176 million files over a 14-day period at a daily transfer rate of 24 terabytes. This case was rather unique, as the data was essentially trapped within the customer’s application but needed to be retained for 10 years to satisfy regulatory requirements. DATAFORGE satisfied the need to reliably migrate file metadata ensuring that individual retention periods for each file is honored at the target system.
- For a very different customer use case, a financial institution specifically, a DATAFORGE configuration of eight multi-threaded Data Movers leveraged a 1GbE network connection to copy over 220 terabytes of data from the source system to its new target – an on-prem object store. DATAFORGE maintained application consonance during the 30-day period during which over three billion files with an average size of 75KB were successfully migrated across multiple protocols. DATAFORGE also produced a chain-of-custody report to satisfy regulatory requirements.
Conclusion:
In closing, though my object storage migration experience is admittedly limited, I believe that Interlock’s DATAFORGE solution appears to check all the boxes I’d be concerned about when tasked with a cross-platform migration project.
For more, head over to the Tech Field Day website or YouTube channel to see videos from the Interlock Tech Field Day Showcase.