Since I’ve started developing my cooking skill more and more, I’ve had to resist the urge to fill my kitchen full of gadgets. The allure of an all-in-one food processing mixer with pasta maker and meat grinder is hard to ignore. However, I also know that if I buy it it’s either going to be used 100% of the time for something it wasn’t designed to do or sit on the shelf in favor of other tools that may not be the perfect solution for my problem but are much easier to use instead.
The journey of chips in networking isn’t much different when you think about it. We spent a lot of time with the perfect solution for all of our networking ills — the ASIC. It was fast and relatively cheap and made it so that we could fire packets across the network as fast as they could go. We built ASICs for everything we could think of. We even built things into ASICs we might never use in the network. Why? Because the dirty little secret of ASICs is that they’re super fast for a reason. They’re completely inflexible when it comes to new technologies.
ASICs are purpose-built. It’s in the name. When you want a new technology introduced into the network you’re going to need to design a chip to accelerate it and then get it into your gear. If you’re lucky and you can get your silicon built and integrated quickly enough you might have it ready to go in two or three years. Which is an eternity in the IT world. Don’t believe me? Four years ago when someone said “containers”, they were probably talking about Docker and not Kubernetes. In that time, a technology has asserted itself as the dominant force in the marketplace. If you had to build an ASIC to support containers you might have bet on the wrong horse if you started building it in 2017.
Intel Inside The Network
The revolution in networking came when Intel embraced the Data Plane Development Kit (DPDK). This meant that you no longer needed to build your own ASIC to do networking. Instead, you could build a software module to do it for you on Intel x86 CPUs. OpenFlow might have started the software-defined networking (SDN) movement, but DPDK made it work for everyone. After DPDK normalized using Intel chips in devices, the explosion of feature-rich hardware was everywhere. That’s because the real work was being done in the software of the device.
DPDK helped people innovate with their code instead of their architectures. It meant portable performance across a variety of platforms. If it ran Intel x86 you could run your code on it. The way that Intel shifted focus to building CPUs with more and more spare cores also helped networking companies because you could count on having some spare capacity sitting around to help you when you needed it.
DPDK wasn’t without concerns though. Firstly, even with the massive horsepower behind the Intel chips it still wasn’t quite as fast as a dedicated ASIC. That was an easily-solved problem because the things that needed dedicated speed like that were things that already had ASICs designed for them. We could use x86 and DPDK until we needed something with more performance that needed to be built. The other big issue came from overloading the main system CPU with all that extra work. An ASIC does one thing really fast. If there is an issue in the system CPU, it doesn’t really affect the ASIC. However, if the x86 CPU is handling both networking performance and other system-related things, a problem with either will bring down the whole thing quickly. Anyone that’s ever seen a device move into process switching packets knows how quickly an overloaded CPU can reduce the system to an absolute crawl.
ARMed and RISCy
Intel isn’t the only chip on the block though. RISC-based CPU architecture is super popular now with the ARM processor architecture. The less-complex chipsets aren’t designed to do the heavy lifting of something like Intel’s CISC setup but what they do well they do very fast. They’re also less expensive because they are easier to make. Software has to do a bit more in a RISC-based system because of the lack of complexity in the CPU but that’s just fine in a world driven more and more by software anyway. Given that DPDK is an open-source project that can be ported across architectures, you can see the advantage of using something that is cheaper. But how do you get around the issues with a main CPU being overwhelmed by lots of I/O? After all, if Intel has an issue with it with their big chips, would ARM face the same issues?
If this argument sounds at all familiar it’s because we’ve faced it in the past. Instead of networking performance, though, it came out of the world of graphics performance. Once the need for high-speed graphics grew too big for the CPUs of the time, companies started creating cards with dedicated CPUs to handle that specific kind of issue. Today almost every computer has a dedicated graphics processing unit (GPU) to drive the display of information. Systems built for gaming have massive GPUs. And, as time has gone on, the dedicated resources in those GPUs have been adapted to serve other purposes, such as accelerating artificial intelligence (AI) and machine learning (ML) workloads.
NVIDIA Moves Into Networking

NVIDIA is no stranger to the GPU market. They’ve been there since the beginning. I can remember running NVIDIA boards in my computers in the 90s. As the power and need for GPUs have grown, NVIDIA has grown with it. They developed CUDA as an architecture to allow programmers to harness the power of the GPU for non-graphics things. They’ve started developing GPUs purpose-built to accelerate AI/ML workloads. They know how to offload processing from the main system CPU into a dedicated unit and how to make that hardware sing.
It should be no surprise that NVIDIA has its sights set on more than just making bigger and better graphics cards. With their acquisition of Mellanox last year they’ve proven that they have their eye on a bigger prize. That would be in the form of data processing units (DPUs). The market for this technology is going to explode in the coming year.
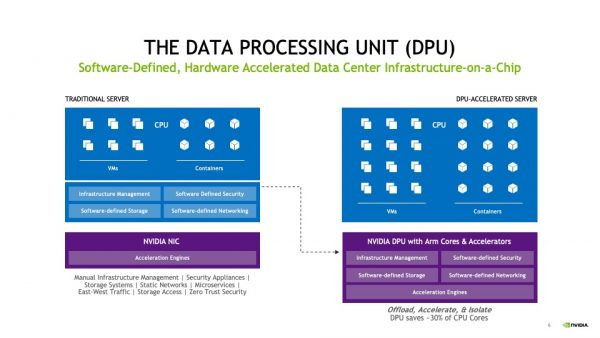
What is a DPU? In essence, it’s a GPU but built for system I/O. Where the graphics processing unit offloaded the math needed to draw pretty pictures, the DPU does the heavy lifting for the networking and storage I/O for the system. With most enterprise data being stored on remote disks the need to move data on and off the system is growing quickly. Since that I/O looks almost the same to the system whether it’s a storage packet headed for a SAN or a networking packet going to the Internet finding a solution to accelerate them both would be a boon to people looking to solve the performance issues of software networking and bottlenecks at the main system CPU.
DPUs work by grabbing I/O and processing it on a separate system. In the case of NVIDIA DPUs, that’s the Bluefield architecture. It runs ARM cores to accelerate networking and storage performance. Now, when the system needs to send networking traffic somewhere it doesn’t need to interrupt the main CPU to get it done. The program knows there is a DPU and it sends the traffic over there to be processed. The DPU does the math and sends it where it needs to go without tying up the expensive main CPU with the work.

The great thing about having a DPU-based architecture is that you don’t have to worry about overwhelming the main CPU when you want to do some serious networking. When you know you’re building for a DPU-based system, you can count on having dedicated resources in place to handle I/O. Especially with storage traffic, it’s critical that nothing interrupts the transactions. If you lose data before it’s written to disk, you’ve lost it for good. If the system CPU has issues you’re going to have a bad day. The DPU will keep chugging along and take care of it all for you.
But why NVIDIA? What makes them more special than any of the other companies touting their own DPU architectures? Remember how I said they’ve been at the forefront of the GPU transformation? That experience is handy when it comes to building architecture for the next revolution. CUDA is the gold standard for programming GPUs for workloads. NVIDIA has adapted that to networking, security, and storage with DOCA – Datacenter on a Chip Architecture. DOCA allows you to leverage the kinds of talent you already have for GPU acceleration and apply it to do similar things with DPUs. There is a bit of a learning curve but it’s not as steep as you might think.
NVIDIA also supports DPDK with their Bluefield DPUs as well. This means you can get things up and running quickly without the need to refactor everything today. Once your teams are up and running with DPUs you can take the time to implement DOCA and squeeze even more performance out of your workloads. You also gain security from CPU threats like Meltdown and SPECTER, since DPUs isolate the workloads away from the vulnerable CPU and into a place you have more control over. You gain fast performance and extra security from emerging hardware-based threats.
Bringing It All Together
The future of networking is offload. We’ve spent the past few years building flexible architectures that are software-based and run on general-purpose CPUs. The market dominance of Intel meant that they were the incumbent when it came to running networking workloads on commodity hardware. However, the increasing needs for performance and worry about running all that I/O through a single processor means that it’s time to break out those functions into a separate processor system. GPUs showed us how important it is to have dedicated hardware for functions. They also showed us how powerful those dedicated systems could be. It’s hard to imagine buying any computer system today without some kind of GPU installed. DPUs are starting that journey today. Soon we will be excited at the prospect of increased networking performance and building our workloads to take advantage of the horsepower at our fingertips. NVIDIA has already led the GPU revolution. The power and capabilities of Bluefield have them ready to lead the next as well.
For more information about NVIDIA and their Bluefield DPU solutions, make sure to check out http://NVIDIA.com or head right to their DPU overview.



