
Policy-driven automation, self service provisioning, and global accessibility are tenets of cloud-like consumption of datacenter resources. I’ve talked in the past about VMware private clouds. VMware private clouds start with Virtual Volumes, where policies are baked into the storage capabilities. NSX, VMware’s flavor of software-defined networking, uses policies to define interconnection between clients, as well as firewall protection. vRealize Suite provides the self-service console and operational management to build a cloud-like environment. But the real key to cloud consumption is the capability to have multiple, disparate consumers using the same resources.
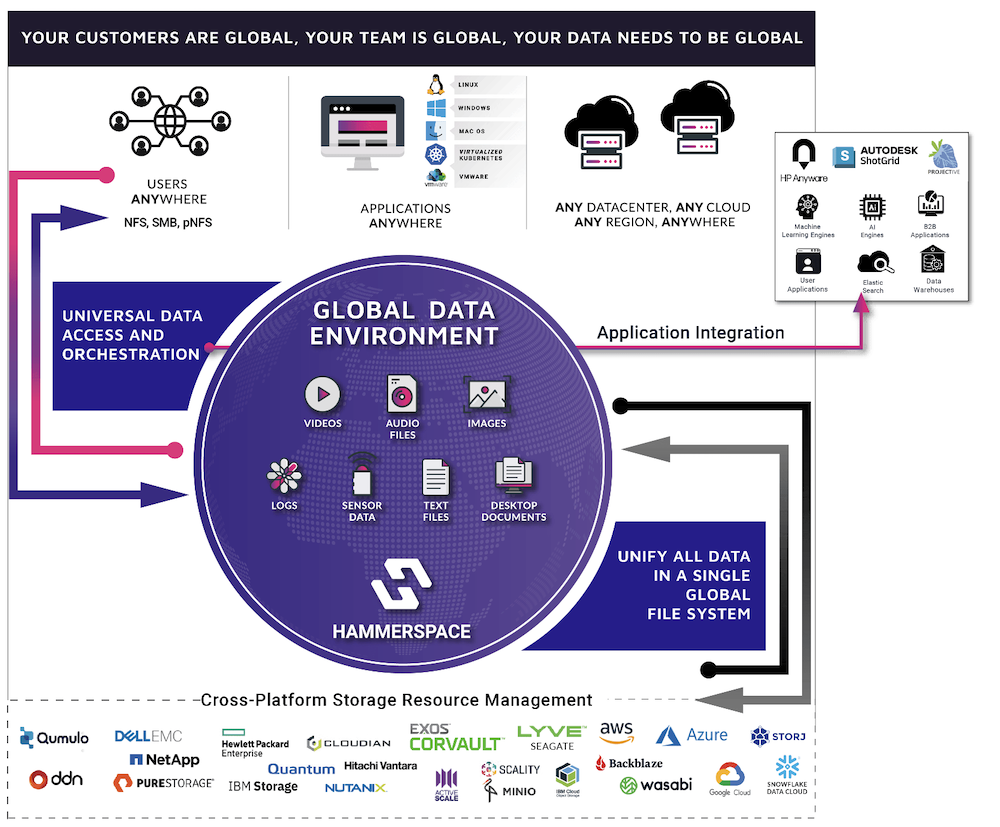
Hammerspace software enables enterprises to create a Global Data Environment, building on a parallel global file system that provides universal access to all underlying data on any storage type or location. The Hammerspace file system is a global metadata control layer that bridges all underlying storage sources—whether local, SAN or cloud and from any vendor. Data from all sources is presented to users, applications, and data utilities via NFS, SMB/CIFS or Kubernetes Container Storage Interface in a single, consistent global name space. This ability to bridge the storage layer means Hammerspace can automate a complete set of data services, including various types of protection, encryption, space savings and tiering globally across storage silos and locations.
I’ve described the Global Data Environment in “Electronic Design Automation with Hammerspace Global Data Environment” and the Hammerspace data sheet covers much more of the details.
Cloud Services Everywhere
Let’s talk about how Hammerspace provides cloud-like consumption of storage resources. One of the most powerful aspects of Hammerspace is the objective-based policies. These are service-level objectives that define and automate how the data is used and stored. They drive many aspects of the data services. Such objectives are essentially business rules triggered by metadata variables that define replication or snapshot intervals of a dataset. They can also define access and protection characteristics of a dataset, for example caching and RAID types for the underlying data. This would also include access, read-write, and consistency requirements of the dataset, which can span multiple storage silos, sites, cloud providers, and regions.
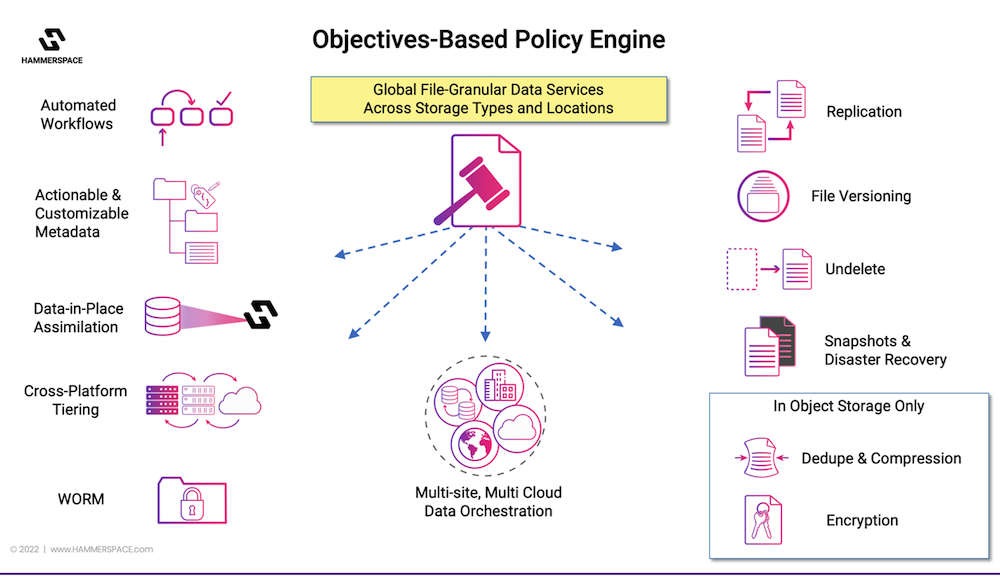
One of the keys to objective-based policies is the ability to stage (or even pre-stage) a dataset without any need to explicitly copy it. A dataset might have a policy applied stating that it is to be staged, or be tiered to a specific type of storage depending on how that data is being used. For example, if it is to be used by a high-performance compute (HPC) cluster, the dataset would be staged to a fast location, local to the HPC. If the data is to be used in a cloud space, like AWS or Azure, a policy would specify to burst it to cloud.
Hammerspace is a parallel global file system, meaning all of the projects ongoing at any given time can all share the same namespace and resources. This is extremely valuable when expensive resources, such as cloud computing or licensed software, are used for relatively short periods of time. This means that cloud-based resources can be rapidly provisioned, and just as rapidly torn down to save cloud costs without needing to migrate entire datasets. The file system spans on-prem and cloud resources, enabling this flexibility. This also makes possible running multiple projects in parallel, since it is much faster to spin up and down cloud instances for the performance requirements of a particular job run than to re-tool fixed infrastructure.
In addition, Hammerspace provides a complete open API for every capability of their Global Data Environment. This allows consumers to easily extend their own workflows, scripts, and even applications directly into Hammerspace to create and manipulate datasets, perform any of the data services, and apply and change policies applied to the data.
The combination of global policy-driven automation by distributed users and applications plus the ability to programmatically interact with a Hammerspace give you the full set of features for cloud-like automation and self-service provisioning capabilities for a variety of projects.
Applying Hammerspace to EDA
We can apply this consumption model to Electronic Design Automation (EDA). Chip manufacturers use a complex multi-step process to convert concepts to silicon. There are almost always a variety of products at various stages of the process. That means a lot of resources are in play for various tasks in parallel.
The first step in the design is to write the code to do the simulation. This is usually done by a developer or a team of developers working on their own workstations. Their source code control base easily fits on a small local NAS device shared among the developers. With Hammerspace, all of the file metadata associated with the project is already part of the file system, even as the file instances move through workflow stages across different storage types. Each product can have its own dataset in the global Hammerspace.

Once the code is unit tested by the developers, it needs to be synthesized into electronic logic code and simulated. The base code of the developers is converted to a new synthesized code, then simulations test correctness, viability and timing considerations. This is a very intensive, iterative operation, normally requiring HPC systems and very fast datasets. Hammerspace can be configured so that custom metadata or user action can trigger a policy to stage and tier the synthesized code into fast storage in the HPC datacenter. This kind of data placement is a background operation, completely transparent to users and applications. Because these resources, both the processing and the software, are quite expensive, it makes sense to be able to spin up a new job as soon as another one is finished. A single Hammerspace file system spanning these disparate locations means there is no need to import the code to the resources. It will already be accessible in the same namespace as the previous project.
Because the nature of the work is iterative, it is overseen by a job control program. This job control program uses the Hammerspace APIs (via Python or Ansible Playbook) to create snapshots or iterative replicas to perform further simulations.
An EDA shop might not have the HPC resources to run multiple simulations and verifications at the same time. Simultaneous to the simulation, verification runs can be happening on cloud-based resources. The synthesized code uses Hammerspace policies to burst to cloud. Since the namespace is the same, there is no need to do a complete copy. Both operations see the same data, even if they are in different tiers. Those same cloud resources can then be applied to any of the other various projects that are ongoing, ensuring hyperscaler bills aren’t piling up for idle resources.
Parallelization speeds up the process. Because synthesis, simulation, and verification also require costly, licensed tools, the decreased time can also provide significant cost savings for such tools, as well as for cloud infrastructure costs.
Finally, a chip fab uses the synthesized data set to produce chip masks and test datasets to produce the final product. These can all be delivered serially in rapid succession as well, because there’s no need to pre-copy large datasets around.

Hammerspace Global Data Environment gives you the parallelization, policy-driven automation and self-service capabilities to handle any task, even Electronic Design Automation.
Learn more about Hammerspace products.