
AI’s complex workloads require extreme computing, the kind that only the fastest accelerators are known to provide. It is little surprise that GPUs (Graphics Processing Units) have emerged as the holy grail of compute as AI gains ground. But exorbitant pricing and scarce access, not to mention heavy power consumption and cooling requirements, raise barriers for enterprise adoption.
What if IT shops truly didn’t need these silicon beasts for the bulk of their AI works?
An Affordable Alternative for AI Workloads below 20B Parameters
Intel has closely followed the GPU trend over the past few years. To gauge the depth of need of GPUs for AI workloads, the teams have run a series of trials, and they’ve arrived at an interesting conclusion. Based on their findings, CPUs can accommodate almost all AI workloads, with the exception of the insanely intense ones.
For example, the most intense large language model (LLM)-based AI workloads, like Meta’s LLAMA2, typically fluctuate within the range of 7 and 30 billion.
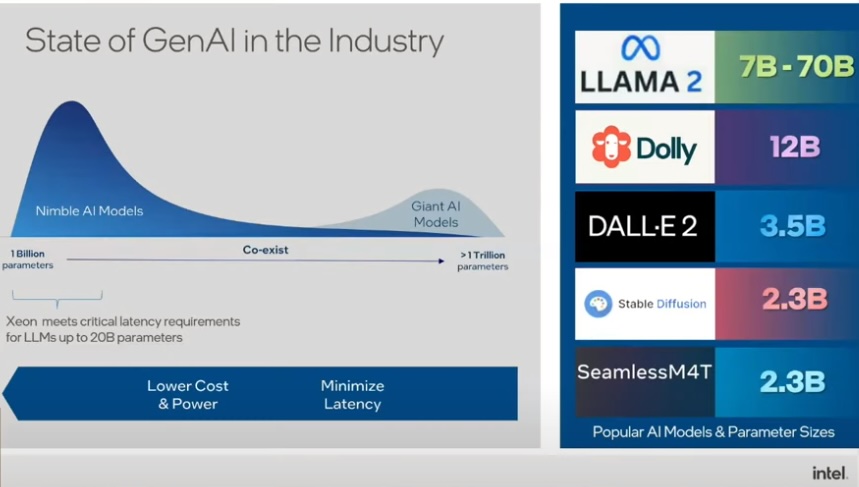
Intel found that a majority of AI workloads remain below 20 billion parameters. The Xeon chipsets meet almost all latency requirements for the general-purpose workloads in that category. There is rarely the need to leverage the massive acceleration of the GPU technology for these AI workloads, Intel says.
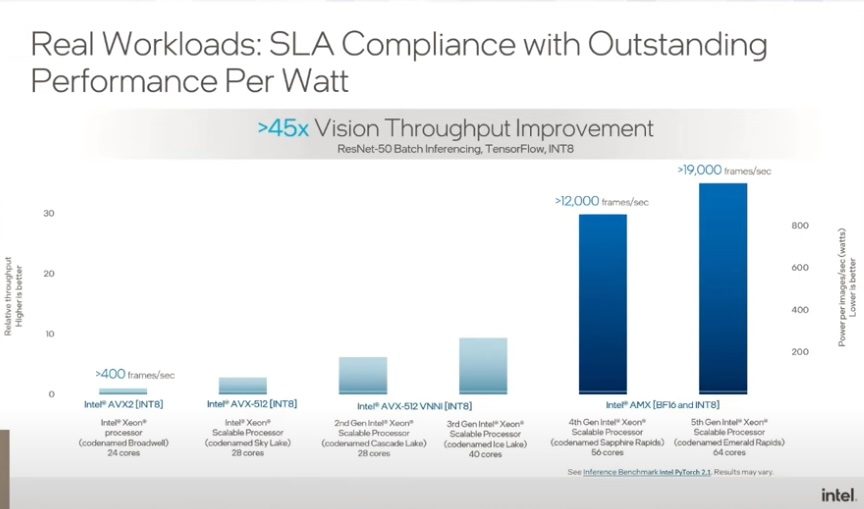
Intel shared benchmarks from real-world scenarios to back this up. In one example of an inference-heavy AI implementation, a customer used Intel Xeon CPUs to perform extremely rapid image processing. The Xeon CPU family was able to scale from a not-insignificant scanning speed of 400 frames per second (fps) using 24 AVX2 CPUs, to over 19,000 fps using 64 cores of their AMX-powered Emerald Rapids processors.
The test results revealed that the newest AMX chipsets engineered with power efficiency kept the 64-core configuration’s energy consumption even with the 24 AVX2.
Another real-world use case Intel shared is of a customer adding speech translation and real-time transcription services to an existing video conferencing offering. Intel engineers put together a solution with just a few additional servers using Intel CPUs.
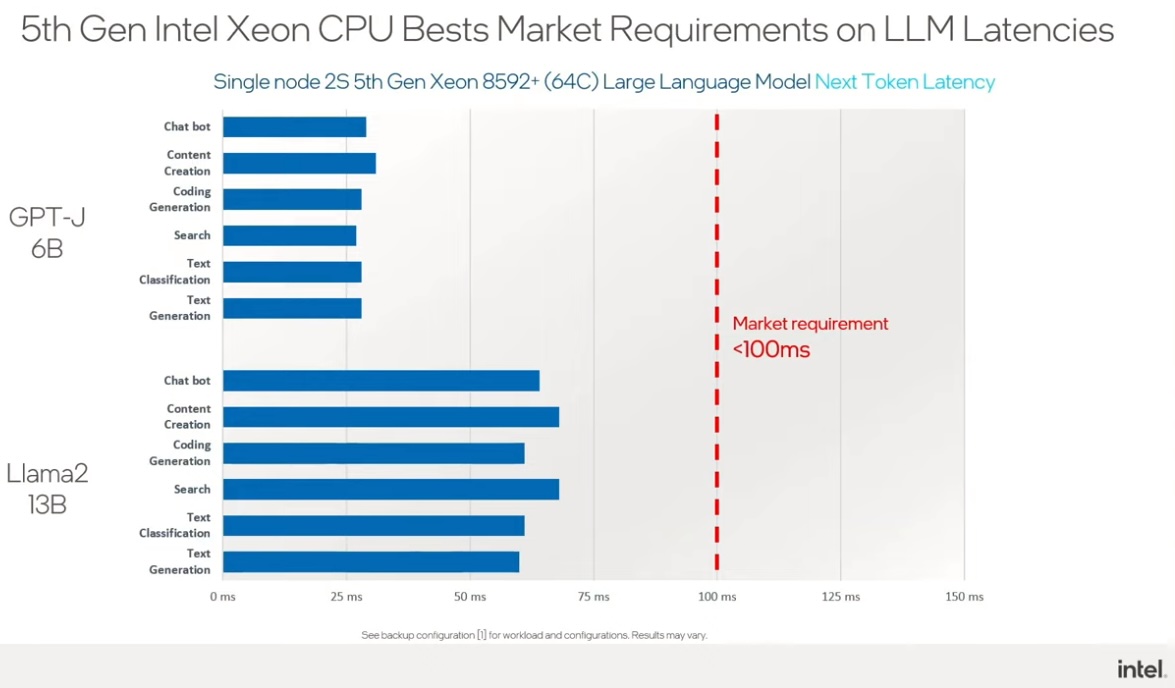
This configuration was particularly interesting because it had to deal with two different AI workloads. Imagine translating the phrase “Pleased to meet you, sir!” to Spanish. The latency for the first word returned in the sequence – “Mucho” – tends to be compute-bound because the AI model needs to find exactly the right word. However, retrieving each of the next words that would be returned in the phrase may also depend on contexts, like the formality of the greeting (e.g. ?Mucho gusto! versus ?Mucho gusto, a sus ordenes!) and tends to be a memory-bound operation.
Intel’s hardware solutions work well for complex AI workloads like the above. Intel has heavily invested in native software support for OSS solutions for data analytics, like Pandas, NumPy, and Apache Spark. Likewise, their commitment to support popular machine learning and deep learning toolsets like PyTorch, TensorFlow, and AutoML (Figure 4) go a long way to extend support to the userbase.
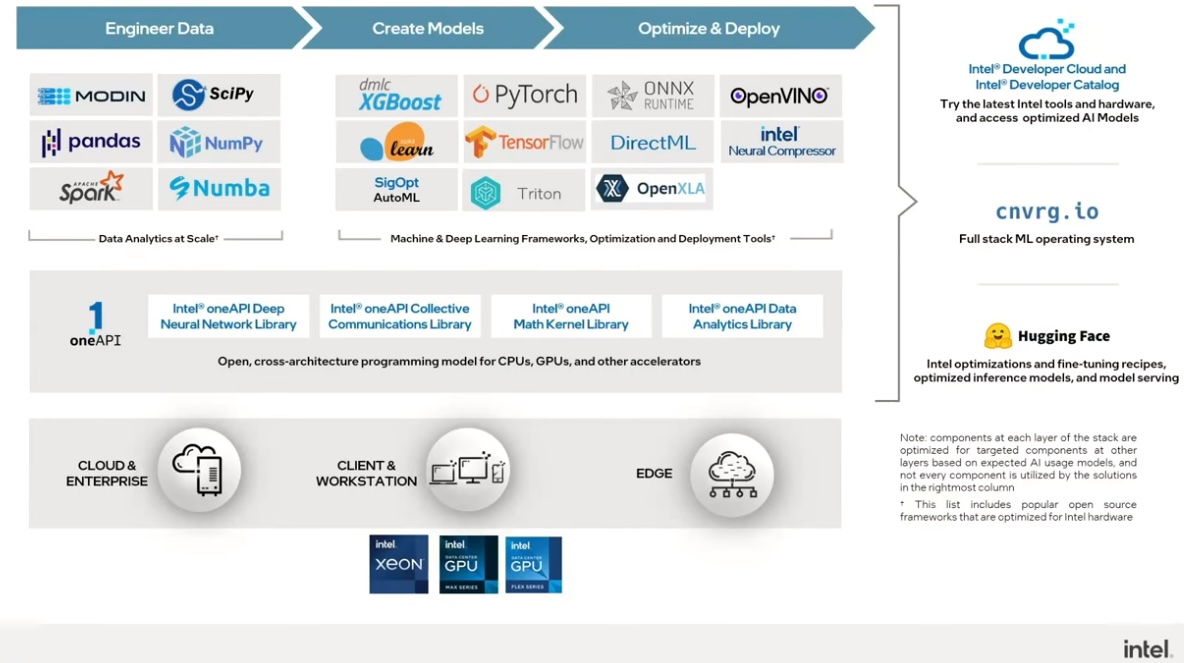
To GPU, Or Not To GPU?
Intel positions its current array of Xeon CPU chipsets for organizations that are grappling with the pressures of providing adequate compute power for AI workloads. Only the most intense AI workloads – specifically, those north of 20 billion parameters – require GPU-level computing power. For everything below that, Intel’s offerings appear to fill the bill. Additionally, their deep support for software compatible with common analytics, machine learning, and deep learning requirements, make their hardware a compelling choice.
Be sure to check out Intel’s presentations on CPUs for AI workloads from the recent AI Field Day event to get a technical deep-dive.