
When measuring the capacity or bandwidth of the your links in the data centre for Layer 2 connections, you often realise that most of your bandwidth is shut down by Spanning Tree. In terms of resiliency and redundancy, this is a valuable feature, but at what cost ? How much bandwidth (and money) is wasted by all of that unused bandwidth ? How much time is spent designing around this limitation and creating overly complex network designs ?
The term Bisectional Bandwidth to describe
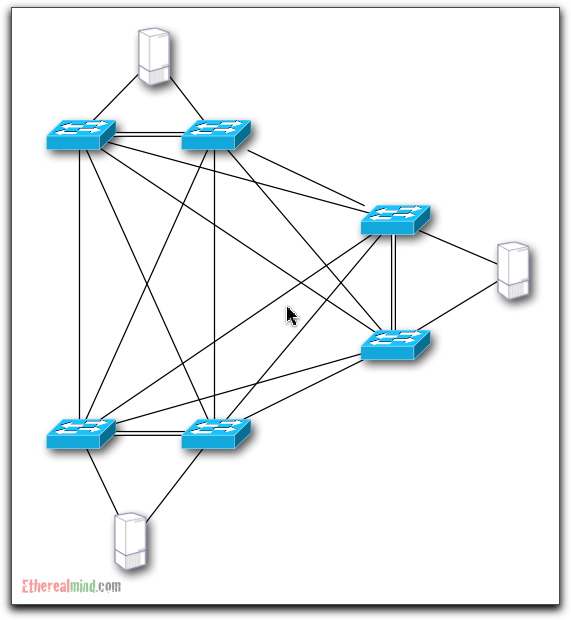
Layer 1: A Example Data Centre Network Core
This diagram shows the physical connections of an overly complicated network core, with three network servers to act as data sinks. It’s not a bad design for a Data Centre full of heavily loaded blade chassis with a couple of ten gigabit ethernet interfaces in each where DRS or a lot of Vmotion is used.
Note this isn’t necessarily a good design, but I’m using it as an example. It’s a possible design for certain use cases such as building a high load “cloud” computing system.
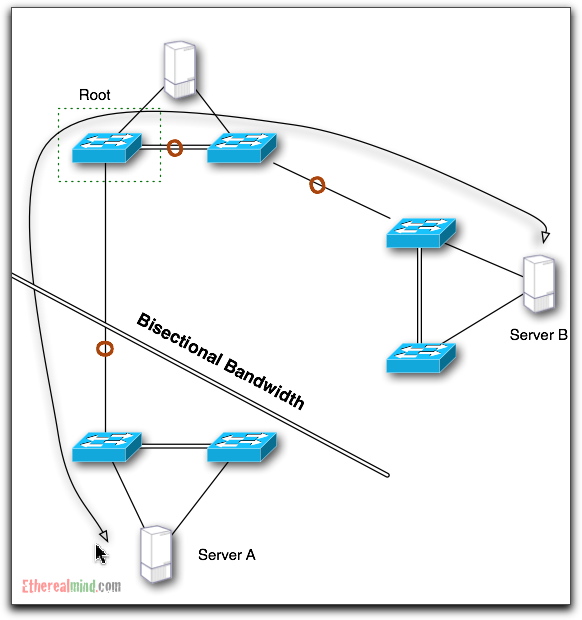
What does this network look like after spanning tree has been established. Lets specify the Root Bridge, and propose that crosses shows links that are disabled for a given Spanning Tree Instance (STI).
Since the number of STP instances depends on whether you are using CST, PVST, or MST. More on TRILL/Rbridges later.
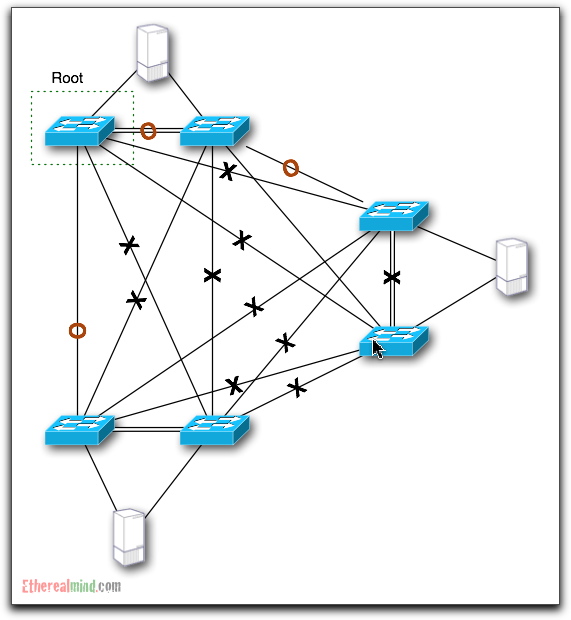
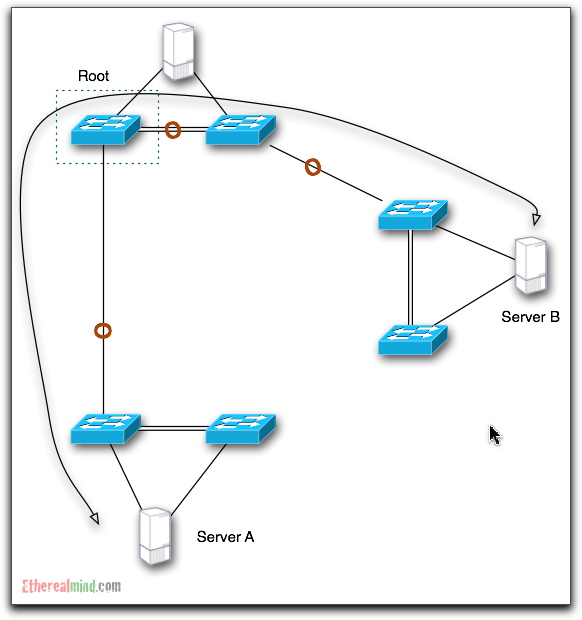
As expected, most of the links across the core are Blocked for a given STI and a Data flow from Server A to Server B is going to flow as shown:
Bisectional Bandwidth
Wehn presenting designs to management and colleagues, I use the term bisectional bandwidth to measure the relative effectiveness of various designs.
Definition – Bisectional Bandwidth
A bisection of a network is a partition into two equally-sized sets of nodes. The sum of the capacities of links between the two partitions is called the bandwidth of the bisection. The bisection bandwidth of a network is the minimum such bandwidth along all possible bisections. Therefore, bisection bandwidth can be thought of as a measure of worst-case network capacity.
Source: Data Center Switch Architecture in the Age of Merchant Silicon (http://cseweb.ucsd.edu/~vahdat/papers/hoti09.pdf) – Note that I do not agree with this paper. A piece of misled student rubbish.
Or this one from Wikipedia:
If the network is segmented into two equal parts, this is the bandwidth between the two parts. Typically, this refers to the worst-case segmentation, but being of equal parts is critical to the definition, as it refers to an actual bisection of the network.
Source: Wikipedia http://en.wikipedia.org/wiki/Bisection_bandwidth
Maximal Bisectional Bandwidth
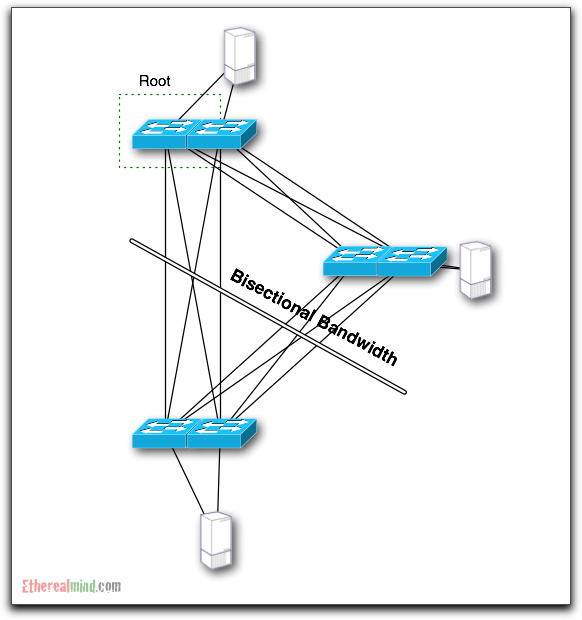
To make into a pictorial format, consider the following
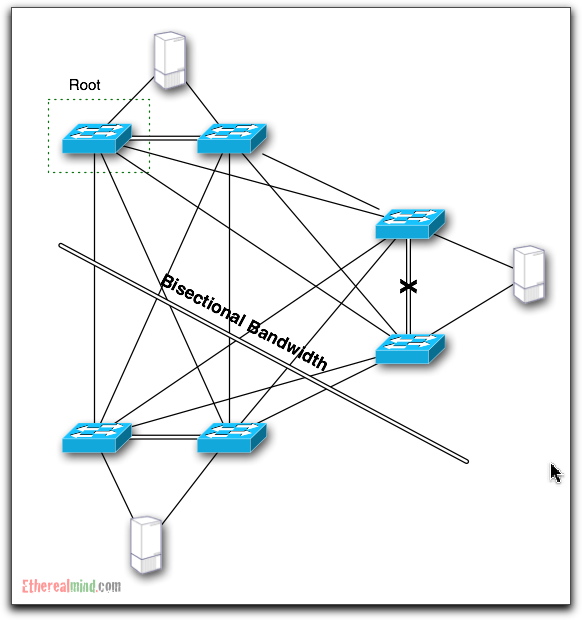
Lets assume that all of links in this example of 1 Gigabit ethernet. The number of links that cross the bisection line is EIGHT 1 Gigabit ports. That means that there is eight gigabits per second of possible bandwidth between the two sections of the network.
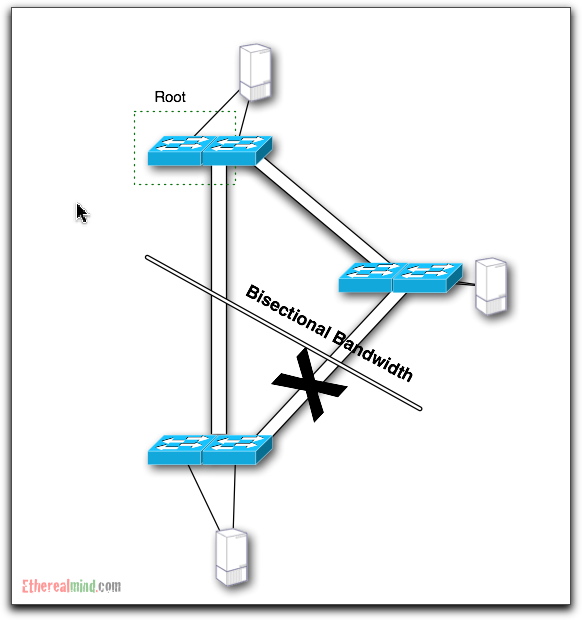
Actual Bisectional Bandwidth
But Spanning Tree has actually blocked all of the available paths from from the lower switches. So the REAL or ACTUAL Bisectional Bandwidth looks like this:
Impact
The impact of Spanning Tree has been to reduce the effective bandwidth between sections of your network from 8 Gbps to 1Gbps thus delivering only 12.5% of capacity in this case and wasting 87.5% of your money. Even of you are using more typical designs, you still lose 50 percent of bandwidth as a best case.
The Impact of Multi-Chassis / MultiPath Technologies on Layer 2
In the last two years, we have seen most of the switching vendors respond to this issue by building software integration between two physical chassis to act as a single logical chassis. Cisco uses the terms VSS on C6500 and vPC on the N7K (or MultiChassis EtherChannel more generally), Nortel uses MultiLink Trunking etc etc, but it all comes down to the same thing.
So now our network looks like this at the physical layer:
But at the logical layer the physical connections are all bonded into a single Ethernet pipe so spanning tree will look something like this:
So now we have four gigabits of effective bandwidth, and four gigabits of unusable badwidth.
MultiChassis is a funky kludge
Ultimately though, MultiChassis technologies are a workaround that have a number of worrying limitations.
The primary limitation is the complexity of the implementation. Getting two switches to synchronise their control planes at very high performance levels is a significant engineering feat. This also leads to bugs, and problems.
The second limitation is that the bandwidth between the two physical chassis must be big enough to act as though both switches were a single switching fabric. And switching fabric are the fastest component in the switch means that interconnects must be large. For a C65K a couple of 10Gb interfaces isn’t too painful and the same bandwidth as a single module in the chassis, but on the N7K, where the backplane connections will grow to (I think) 160Gbps per slot are allocating half a dozen or more 10Gb interfaces is costing real money. The more ports you allocate, the less effective the switch is as delivering useful connections for servers.
I expect to see the vendors announce “fabric interconnects” in the near future. These will be proprietary connections to the switching fabric that allow for very short, very high speed, low latency suitable to connect the silicon fabrics on the chassis backplanes which are co-located in the same or adjacent racks. Once those are released, that’s the sign that TRILL is the next big thing. The vendors will want to squeeze all the money they can out of their existing products before tackling TRILL and the end of Spanning Tree.
Multichassis is a temporary software fix for the underlying Ethernet problem with many paths to the destination. It’s not a technology to bet your long term data centre future on because of its complexity and limited returns.
Note that it is an easy sell and easy to market and so will be very popular.
So, TRILL/Rbridges then
So TRILL (Transparent Redundant Interconnection of Lots of Links – I wrote intro here) is being developed to solve the underlying problem. Lets define the problem:
- Ethernet network are auto learning and ‘auto’ addressing
- Ethernet networks are ‘auto-routing’ since the Source MAC Address is stored into the switching table to specify the return path on a hop by hop basis.
- Loops are not resolved within Ethernet frames and are fatal to the network
TRILL (IETF RFC)uses RBridges protocol to build a Source Based MAC address table using a form of the IS-IS routing protocol. Because we are using a routing protocol we are now able to have knowledge of multiple paths to the destination and then perform load balancing of multiple paths for traffic flows. So for the design proposed, flows have an ANY-ANY orientation that allow for full use of all available bandwidth.
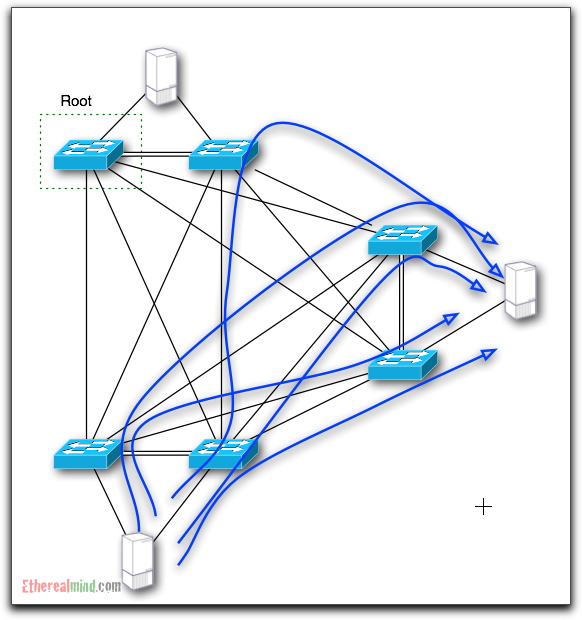
and the LAYER2 Network now matches the Layer 1 network layout.
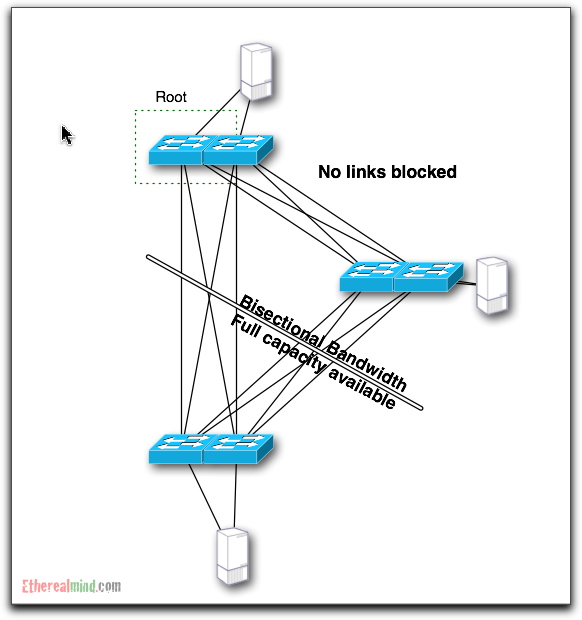
And in this design, the full bisectional bandwidth is available. There is no ‘wasted’ bandwidth, and the network can dynamically route around failures in the underlying system. It is expected that Rbridges can converge in less than 250ms (if I read the data right) and this means effective failover.
The EtherealMind View
I take the view that the current trend to Multichassis logical designs is an attempt by the vendors to extend the useful life of their existing technologies. It’s an effective move since some relatively cheap software development time in an Indian programming company will produce a life extension of existing assets. For example, the Cisco C65K is at the end of its useful life, and the release of the VSS feature is hailed by marketing as an “innovative systems virtualization”. In reality, its a software patch while they rush to finish the Nexus 7000 and extract the last possible profits from the fully depreciated Catalyst 6500 platform.
Of course, it’s not that simple. The IEEE TRILL Working Group hasn’t been moving as fast as we might expect. The RBridges protocol has been stuck in the Editors queue for a while. Given that Brocade and Cisco are named on the current draft it quite possible that corporate interests are knocking heads and causing delays.
Will TRILL actually be used
I’d say yes. Vendors are already briefing their sales engineers on TRILL/Rbridges and this indicates that they have products under development. If they don’t, their competitors do and questions are being asked.
The real question then becomes, WHEN ?
Answer: When people like you and me are ready to replace Spanning Tree and move on .
“I expect to see the vendors announce “fabric interconnects” in the near future. These will be proprietary connections to the switching fabric that allow for very short, very high speed, low latency suitable to connect the silicon fabrics on the chassis backplanes which are co-located in the same or adjacent racks.”
This technology has existed in widely-deployed products for quite some time, in the supercomputing, IP routing, and Ethernet bridging/switching spaces. Your article reads a little like you’ve thought of something novel, but in fact this has been exceedingly common for ten years — even in some Cisco products.