
Many organizations are struggling to keep up with the rising costs of public cloud. As enterprise cloud footprints are expanding, more companies are being cautious about their spendings, and are looking for ways to trim cloud costs.
“How efficient are your EKS clusters?” Madhura Maskasky, Co-Founder and VP of Product at Platform9 Systems, asked the audience at the recent Cloud Field Day event.
The Mismatch Between Sizing and Usage
The amount of memory and compute resources provisioned to AWS Elastic Kubernetes Service (EKS) clusters has jumped with the acceleration of digital services, but resource utilization is far from optimum, studies say. In an analysis, Datadog found that 45% of containers use only 30% of the requested memory.
These numbers check out with Platform9’s observation of its own Kubernetes environment, and those of its clients’. “When you gather the average utilization across all of Kubernetes worker nodes and average it over months or a year, it tends to be at most 30%,” Maskasky said.
Overprovisioning is one of the biggest reasons of excess cloud consumption. “30% is very much on the optimistic side. In reality, people pat themselves on the back if they get it above 20%,” she adds.
For organizations, this means a slimmer operation margin and a small profit. Maskasky points to two key issues that directly contribute to cloud cost blowouts. Developers request pod resources that are below the instance capacity, creating unused pockets of resources, a problem internally referred to as bin-package wastage.
Alternatively, when developers set the resource limit higher than normal to avoid performance problems in peak seasons, requirement fluctuations cause resources to sit idle, snowballing the cost.
“What’s surprising is, many times, enterprises measuring their utilization don’t even account for this factor,” says Maskasky.
With inflationary pressures building up on businesses, many enterprises are regularly reviewing their actual usage to understand the financial impacts of underutilization. Good observability is key to exposing sources of overspending in the cloud, and there are visibility apps that provide insights at various granularities. But leaderships face major pushbacks when attempting to adjust resource allocations.
There are two reasons for this. Any changes made to pod requests are likely to cause app SLA conflicts, and developers resist it strongly. Secondly, rightsizing typically involves termination and removal of pods which directly affect application performance.
A subset of autoscaling tools like Karpenter tune application configurations to right-size pods on behalf of the users. “There are a number of side effects around it,” warns Maskasky. “Dynamically reconfiguring application requesting limits requires a part-restart, essentially meaning that app SLAs will be compromised.”
Correcting EKS Cluster Oversizing with Elastic Machine Pool
One way to address this is to spot and target resource wastage intelligently, and auto-eliminate it without starting a churn. “None of the tools that exist today try to attack the compute optimization problem at a layer below, where we think it can be automated and addressed in a unique way. So, we wanted to build something that does not compromise your app SLAs but notices everything,” Maskasky says.
The newly launched Platform9 Elastic Machine Pool or EMP is a compute engine that is designed specifically to address compute utilization issues in Kubernetes environments in the public cloud. EMP optimizes EKS cluster utilization without prompting big changes in application configurations. As a result, the typical pod disruption is averted, and as a bonus, EKS costs are slashed off by almost 50%.
“We like to optimize the allocated and used bucket, and while doing so, we are able to make a big dent on your EKS cost,” she said.
EMP is built on a simple concept. Instead of the regular EKS clusters, EMP creates a host of bare-metal nodes at the AWS bare-metal layer, and deploys elastic virtual machines (EVMs) on top of them. “These EVMs look and feel exactly as your EC2 worker nodes, but they are highly optimized to be better consumers of the resources given to them,” she explained.
The trick is to pack more EVMs on fewer bare-metal nodes based on the usage metrics – a clever way to eliminate bin packing overheads, all the while avoiding making changes to resource requirements. “By doing that, we are betting on the fact that none of the VMs are ever going to use more than 50% of the allocated memory.”
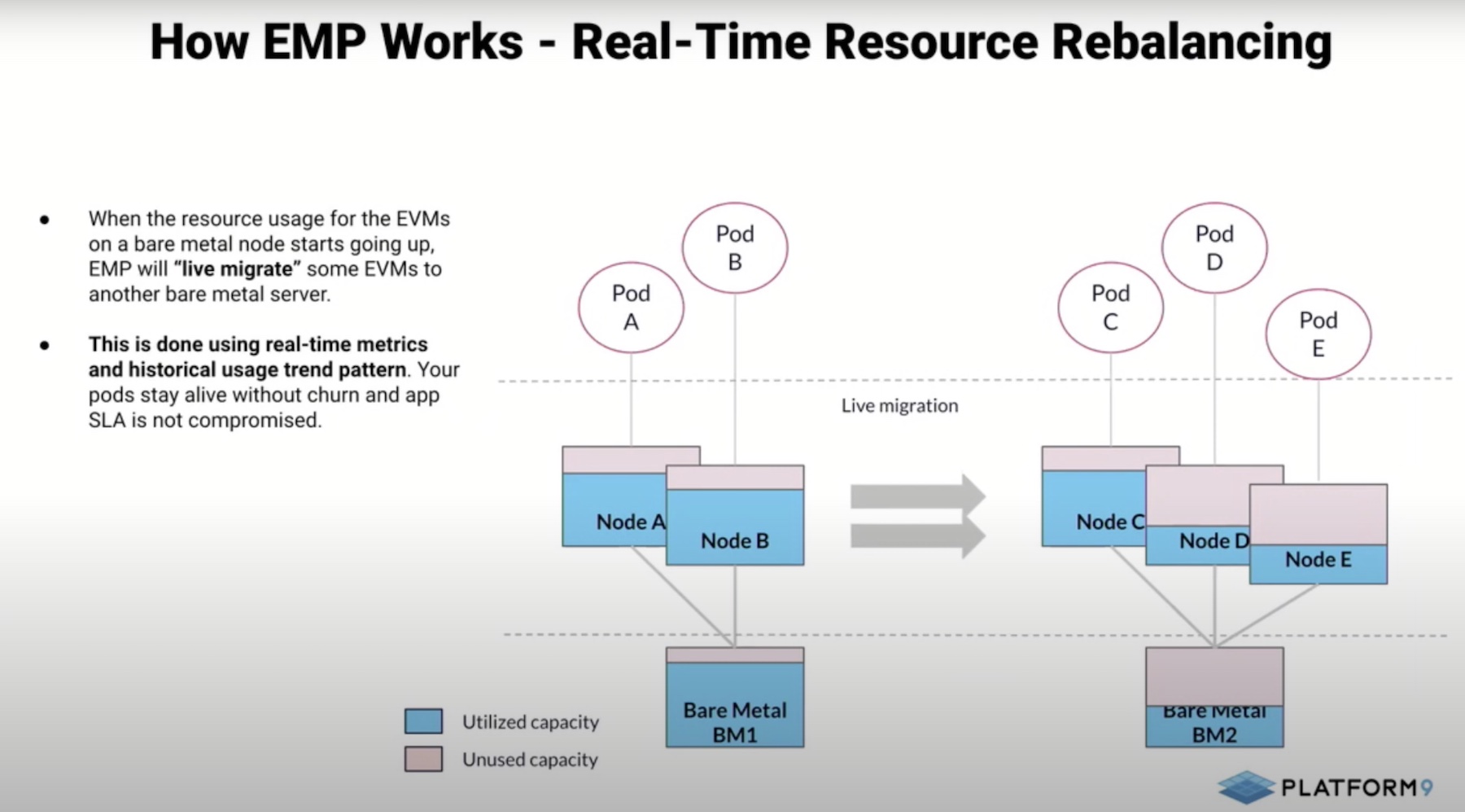
But should the consumption exceed capacity, a second component called the rebalancer kicks off. The work of the rebalancer is to generate actions to ensure that capacity consumption is evenly distributed across the nodes.
It sits in the environment collecting metrics from the nodes and EVMs. “It’s very aware of your application and its resource needs. If the VMs start consuming more memory, pushing the bare-metals’ memory consumption above a certain threshold, it’s going to migrate some of those virtual machines to other bare-metal machines in the pool.”
EMP ensures that resources are reallocated before the VMs reach a crashing point, thus assuring application performance continually.
All of it happens in real-time. “It has live migration capabilities built-in with it, and is able to migrate persistent storage, volume, network connections, IP addresses, and all persistent states,” she says.
The only situation where EMP is not a good fit is for high-frequency trading where applications cannot handle microsecond delays, informs Maskasky.
Today EMP focuses on AWS and EKS only, but there are future plans to expand the tool to other cloud platforms.
To learn more, be sure to check out the Platform9’s deep-dive and demo sessions of Elastic Machine Pool from the recent Cloud Field Day event.