
Getting computer data sprawl under control has been one of the top struggles of organizations since data explosion shot up usage and skyrocketed tech spending. But researchers seem to have found a resolution that could end the data problem once and for all. The answer, they said, was in nature all along.
Vast Pools of Data, A Drop in the Ocean
When viewed in terms of storage media capacity, there is always more data than one can afford to save. But in nature, even all of the world’s digital information amounts to just a smidgen. In a study, a team of scientists have discovered a storage medium that can accommodate vast pools of information without the tiniest possibility of ever running out of space – DNA.
Our DNA packs billions of gigabytes of complex genetic information, that remains preserved for generations, even after life. In the experiment, the team attempted to encode computer data into strands of DNA to test its capacity. They were able to fit information worth an entire library inside one milligram of DNA molecule. An even bigger surprise, there was still plenty of room to spare.
Now think, if so much data could be made to fit inside just a molecule of DNA, what other possibilities do we have.
Researchers say that DNA is not only revolutionary in its ability to store data, but it is also capable of saving data for centuries without risks of perishing.
“Our DNA stores millions and trillions of bits of data within it,” said Dave Landsman, Co-Founder, and Board Member of SNIA (Storage Networking Industry Association) and DNA Data Storage Alliance – the body that is behind the development of DNA data storage, at the recent Storage Field Day event in California where SNIA introduced the technology. “Just the density of DNA and scale is incredible,” he added
DNA Data Storage Alliance
The DNA Data Storage Alliance, a SNIA Technology affiliate, was formed in October 2020 by four Goliaths from biotechnology and tech, namely, Illumina, Twist Bioscience, Microsoft and Western Digital. Their mission is to create an interoperable storage system using DNA as the standard medium.
Their initial goal was to raise awareness about this emerging technology, and its potential to preserve the long trail of digital footprints. But as opportunities to turn this into a commercially viable solution emerge, the board will come up with specifications and standards to absorb it in the existing ecosystem.
Information Overload is Crippling Modern Corporations
At the event, Landsman, and Daniel Chadash, Co-Founder of DNA Data Storage Alliance, and a current associate of Twist Bioscience, blew the lid off of the science behind this bleeding edge technology.
Why DNA, one may wonder. What can offer better space efficiency than our DNA? The answer, if there was any, is unknown at this point.
“If you want to get to bit size and just the density that you need to do zeta-scale storage, something like DNA can get you down into the one-by-one nanometer range where magnetic media is just not going to get,” declared Landsman.
Information overload in a corporate scenario leads to many dead ends – low data visibility, elevated security risks, data governance issues and so on. Disappointingly, there aren’t many archive storage mediums till date to support the pressures of cold data proliferation. Even with those that are there, media longevity is limited to 10 years at most, putting data at risk of loss.
There is a visible gap between supply and demand. On top of that, sustainability issues have taken centerstage putting pressure on vendors to build energy-efficient mediums that lower carbon emissions.
“We’re digitizing everything at great rates, and nobody wants to throw data away. It’s getting more and more expensive. We need an adjunct to a new storage that can be very high density, and very low power.”
But doesn’t tape already provide bulk storage and long-term retention at a pocket-friendly price?
Archival storage at zettabyte scale involves fixity checks and refreshes for long-term preservation. “People are getting to the point where if they have a huge tape library, by the time they’re done filling it up, they have to start refreshing it. Then, by the time they’re done refreshing it, they have to refresh it again,” noted Landsman.
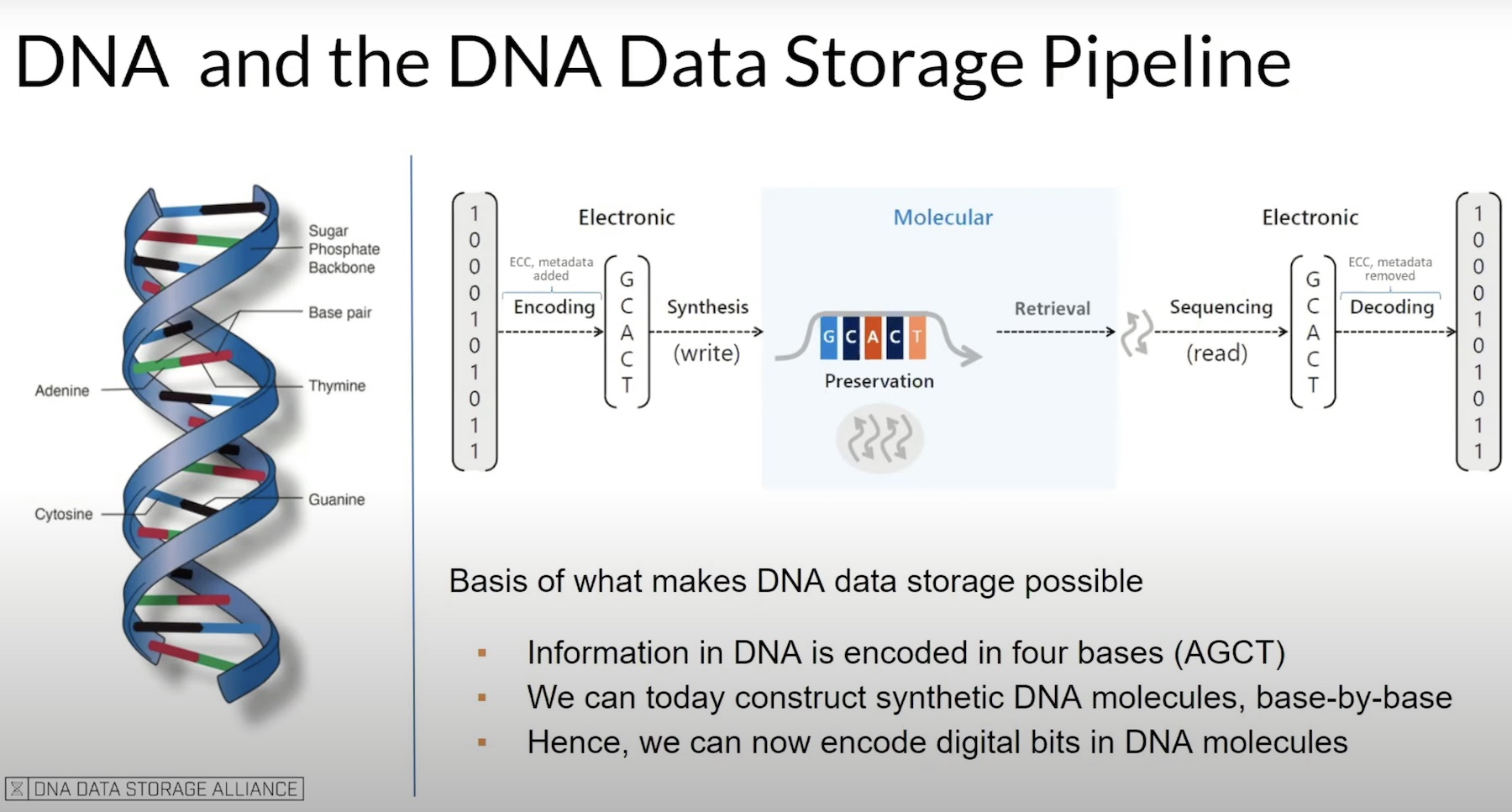
DNA Data Storage
Instead of continuing the work on inventing greater capacity storage solutions, scientists found the vein of effectiveness in DNA, the component that is common in all living beings, and most abundant in nature.
So how do you write computer data into a DNA strand? The same way it is done in computers, using a chip. Only in this case, it’s a special kind of chip that can incubate DNA molecules.
Conceptually, storing data in DNA is fairly straightforward. It involves two core components –base by base synthesis of DNA molecules, and a compatible coding system.
This is a 2D microchip that is divided into tiny blocks or an array of electrochemical reactors. Inside each of these reactors, DNA strands are chemically synthesized. The strands can grow up to the length of 150 to 200 letters in each block.
“This chip can synthesize 30 to 32 million synthesis sites per centimeter square. Commercially we need to scale a lot more than that, but that is how we’re going to scale,” Landsman informed.
Packeting and routing of data follow the general principles of computing. “The transport layer of DNA has very similar functions in concept to what goes on in electrical channel, although they’re all done in the software codec.”
One key difference is that where storage media saves data in 0s and 1s, DNA stores it in alphabets A, C, G and T. So to encode a digital file into a DNA fragment, it needs to be converted to this four-letter format. While reading, this is converted back to the digital format recognizable to the computer, a process called sequencing.
After the DNA fragments are created, they are washed into a tube and amplified to create more copies before they are purified and packaged in the chips based on their capacity.
“A very important factor in scaling is that it is limited by the array pitch and the chip size. We cannot just make a chip the size of a table. Right now, from how it looks, we need to make enough DNA in each of those small sizes, in order to practically store it. So it looks like one terabyte a chip is the practical limit,” Chadash highlighted.
However, the process faces one major roadblock. Oxygen degrades DNA, and that can perish data. Chadash clarified that hermetically packaging the strands can lead to a much longer shelf life. “If we hermetically seal it, we get to 38,000 years at room temperature which is quite amazing to any other storage technology.”
Chadash reminds that DNA maybe dense, but packing too much data into one strand can lead to complications in the future. “We cannot store zettabytes in one capsule, that would be very hard to manage. You want to be able to split it and move it around, take it between different systems, different sequencers and readers inside the data center.”
That’s where the arrays are helpful in splitting up data into separate containers, storing at a density of 100 TB per array.
Data is resurrected through sequencing. Currently, a single run of a sequencer goes between 12 hours to 36 or 48 hours. “Some groups are working on it to develop higher capacity sequencers and faster ones, and the cost is declining.”
Takeaways
The greatest advantage of this technology is the staggering raw storage capacity of DNA. Although molecular in size, in less than of picogram of DNA, you can save petabytes of digital information. “If you took DNA bits and filled the volume of an LTO-9 tape case, it would hold two exabytes or over 115,000 tapes worth of data. It’s a quantum leap from existing storage,” said Landsman.
Studies have shown that saving data in this new way can prolong its longevity by a wide measure. The recent recovery of DNA information from fossilized remains of animals from prehistoric age, points to how long DNA can preserve information. By contrast, the longest running storage medias can safely store data up to only a decade or so.
DNA data storage crosses other boxes too. For example, it has zero migration costs, no expense for data at rest and cheap to make copies, making it a budget-friendly alternative in several respects. “The TCO is quite compelling,” assures Landsman.
Sustainability is a big yes with DNA data storage. Although the current synthesis techniques use caustic chemicals, a new study has shown that enzymatic synthesis using aqueous-based solutions can yield better results, and is most eco-friendly.
As for immutability, DNA is format immutable. “The molecule of DNA will always be able to be read. The reading and writing technology may change around it, but the fundamental molecular format will always be able to be read,” he says.
So is this technology ready to market yet? It may be closer to hitting the shelves now than it was ten years ago when it first came out, but it may still be some years before companies can replace their servers with this stuff. However, scientists are working at a frantic pace maturing the technology every day, and knocking off the costs to make it a reality in the observable future.
For more on this, be sure to check out SNIA’s presentation on DNA Data Storage, and other exciting stuff, from the recent Storage Field Day event.