
Artificial intelligence has helped large corporations mint billions of dollars of revenue. But one aspect has been overlooked until recently – failures and mistrust.
AI’s trust issues are growing at an alarming rate. Surveys indicate that many models lack the solid foundation for making accurate predictions.
But the problem is not that one model is superior than the other. It is the developers’ inability to anticipate and control how the models will and won’t work that has led to confidence gaps in the users.
Qlik took notice. Sharad Kumar, regional head of Data Integration & Quality introduced a new framework – the Qlik Trust Score for AI – at the Tech Field Day Experience at Qlik Connect 2024 aimed at improving trustworthiness in models.
Trust and Transparency in AI Starts with Data
The key to trustworthy AI is data readiness. The trusted data foundation for AI stands on three legs – AI-ready data pipelines, improved data quality and AI-augmented outcomes. Together, they provide a dependable basis for inference for the models.
Qlik utilizes traditional ML with GenAI capabilities to accelerate and automate a lot of the data engineering capabilities on its platform. So to ensure that the AI systems that underpin the solution are fair, reliable and trustworthy, it extends the Trust Score for AI feature inside Talend Cloud to build a stand-alone capability called the Qlik Trust Score for AI.
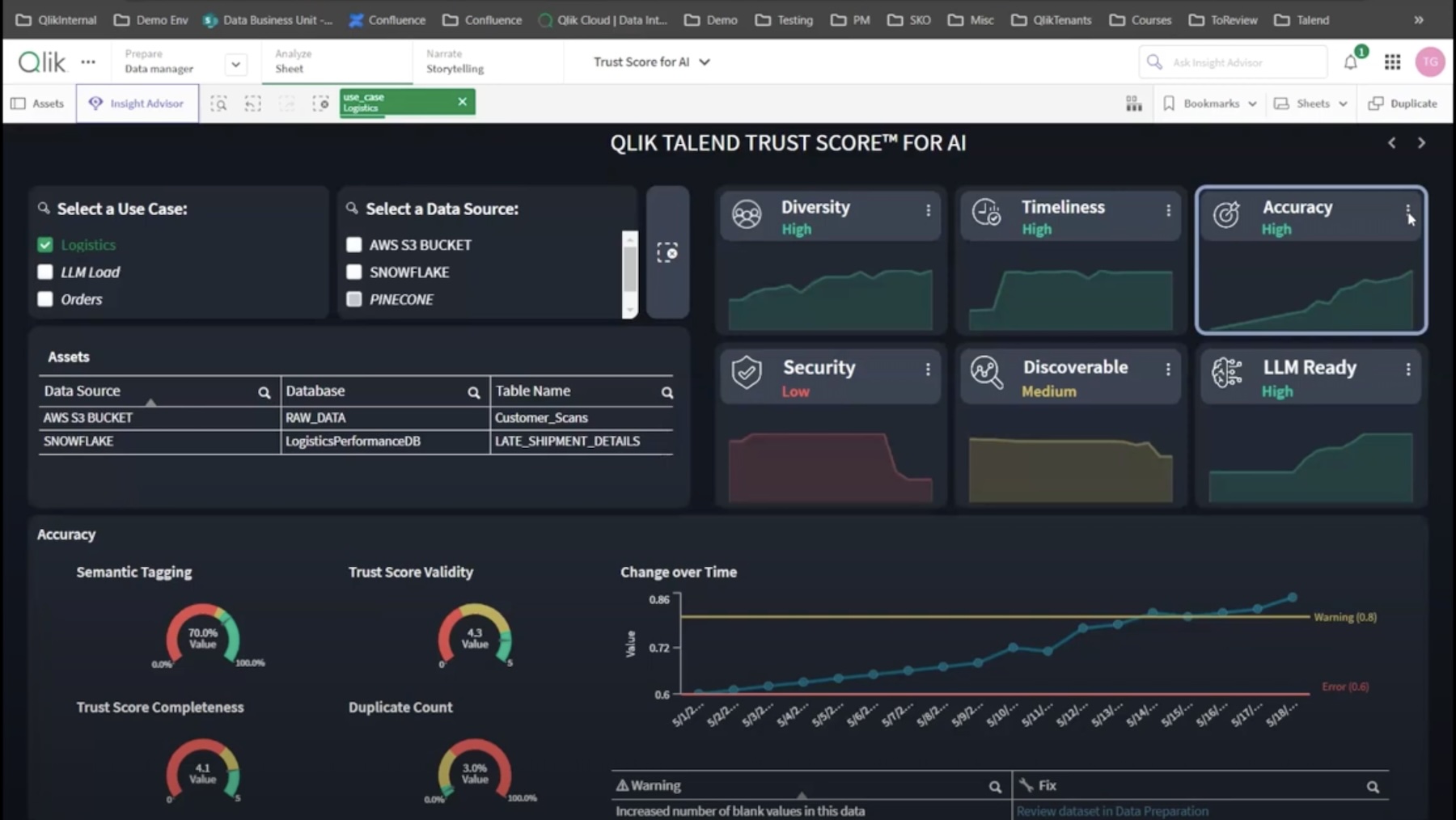
The system is aimed at measuring the trustworthiness of AI at data level. Qlik Trust Score looks at datasets and score them based on the overall data quality.
The scoring system is based on a winning set of dimensions, namely, data diversity, security, timeliness, accuracy and discoverability. The individual scores reflect the overall AI-readiness of the datasets in question.
Sharad explained that siloed data tends to produce biased results. For a model to have high trustworthiness, it must be trained on a diverse corpus. “You must make sure your data has all the different patterns and nuances that are applicable to the problem. So it has to be wide to be diverse.”
Only accurate data yields accurate results. Routinely, the data fed into the AI models has to go through quality checks for accuracy levels.
All sensitive information in the data must be surfaced from get-go, Sharad emphasized. Things like personally identifiable information (PII), financial details, and proprietary information, must be flagged and mapped to a protective tier and layered with additional security before data is shoveled into the model.
An AI-ready dataset is easily consumable by AI systems, and fully discoverable by the IT personas using it.
Data that is rich in metadata and business semantics is the best data to use, says Kumar. It is then that “business users and data scientists can find, understand and know the right context to use in the model.”
A System to Measure Trustworthiness
The Qlik Trust Score for AI is available with the new Qlik Talend Cloud. The dashboard displays the said metrics and the LLM-readiness of datasets in one view. Administrators can individually select assets like data sources, databases and table names, to see how they score in the framework.
Clicking on the metrics takes them to a detailed view of each dimension. Tim Garrod, head of Cloud Data Transformation & CDC, showed an example of the subset used to analyze data accuracy. They included semantics tagging, trust score validity, trust score completeness and duplicate count.
Trust Score for AI rates assets as high, medium or low. Anything that is marked low is accompanied by AI-generated recommendations for how to improve it.
The scores are based off of customers’ own unique environments. It is not specific to one regulatory body or geographical location, said Garrod, and as a result are very different for every environment.
The framework is fully customizable and offers users complete control over what metrics to focus on. “We can extend the trust score and the framework to fit with the customers’ explicit requirements and datasets. So if you’ve a dataset in Kafka or in S3 or an API, we can plug that into whatever you need to, and then drive it into this framework,” Garrod said.
Many regulatory bodies have mandated data locality to ensure data protection. Qlik complies to geographical data clauses by having a fleet of remote engines. These engines allow users to deploy jobs locally in any region. “You can deploy as many of these engines to as many geographical places as you need,” he said.
To help organizations achieve the trust and transparency required for AI models to reach their full potential, Qlik also introduced Qlik Data Products. These are reusable data assets curated to address specific business use cases. The data products form the foundation for AI models and recommendation systems to yield reliable results.
These productized datasets are available in the Qlik data product marketplace where they can be searched and found easily. Users can request access to particular data products, ask for enhancements, build trust in them, view other users using them, and ultimately use them for their intended use cases.
For more, be sure to check out Qlik’s presentations on the Qlik Trust Score for AI from the Tech Field Day Experience at Qlik Connect 2024.