AI workloads are set to put datacenter networks through the wringer. With their need for ultra-fast throughput and lossless data transfer, this new generation of workloads has caught many enterprises flat-footed. Can Ethernet pass the test?
At the Cloud Field Day event in California, Praful Lalchandani, product lead for AI Data Center at Juniper Networks, answered the question.
Myths and misconceptions about Ethernet have clouded perceptions of common users for a long time. The ascent of AI has added more insult to the injury. The misgivings deepen every day, getting between the technology and its potential takers.
Lalchandani refutes the old assumption that Ethernet cannot compete with InfiniBand in performance.
The AI Network Fabric
A short gist of the AI application development lifecycle will level-set the discussion.
The AI pipeline embodies a highly complex set of processes. At the beginning, data is scraped and assimilated from disparate sources. It goes through rounds of processing during which it is reformatted, broken into chunks, streamlined and made free of biases. When it’s ready to go into the AI model, the training commences.
During training, the model learns to identify patterns in the data. A cluster of GPUs work together to train a job over the course of a few hours to several weeks.
There are two types of AI training – foundational model training where a model is trained from the scratch. Some examples of foundational models are GPT-4, GPT-5, Llama 2 and Llama 3.
To train the weights and biases of an uninitialized model based on selected data, it takes tens of thousands of high-end GPUs. The process costs a scathing amount of time and money.
The other type of training, which is relatively less resource-intensive, and as a result is gaining traction among most adopters, is fine-tuning. This is where a pre-trained model is trained on task-specific datasets to perform specific tasks. It does not require large real estates of compute, but it is still GPU-dependent.
But the real action does not happen until after the training. “The rubber hits the road when the model is packaged into an application, deployed for inference, and it starts to make predictions based on new user inputs,” Lalchandani said.
Like training, inference too happens at different scales. Single-node inferencing involves using a single GPU or alternatively a CPU, and is preferred for less-demanding AI workloads. When the model is too heavy to fit into a single accelerator, multi-node inferencing is performed.
A technique often invoked to improve the quality and accuracy of inference is retrieval augmented generation or RAG. This works on small sets of supplemental data, and requires high-speed access to the storage over a fast network.
The system that powers training and inference unpins the same components – GPU clusters, a dedicated high-performance storage, and the network.
The network combines three separate fabrics – the backend high-speed GPU training network over which GPUs communicate with each other, the middle mile which connects GPUs with storage, and the frontend network that connects the system to the Internet and orchestration platforms.
The key metric for training is job completion time (JCT) and throughput for inference. For both of these, network is an essential enabler. AI workflows thrive on data parallelism. In plain speak, it is a way to perform parallel computation across several compute nodes. The progression of the nodes can be held back by delayed flows and bottlenecks.
An Ethernet Network for AI Datacenters
“While GPUs are the currency for the AI revolution, building even a small cluster of just 8 to 16 nodes can lead to a CAPEX investment of 5 to 10 million dollars,” Lalchandani highlights.
Juniper Networks’ innovations around AI networking are geared at three long-term objectives – to build a network that provides unparalleled performance and unlocks the full potential of AI, is easy to operate, and has lower TCO than any proprietary technology. Their choice of network is Ethernet.
Juniper Networks takes a page out of the playbook of the largest cloud providers to make Ethernet work for AI. Recently Meta published a report about its Ethernet RoCE clusters. According to the report, the performance gained with Ethernet interconnects was equal to InfiniBand.
To test this out in practice, Juniper Networks created the AI Innovation Lab. Inside this lab, real training and inference jobs are run on GPU clusters on an Ethernet network and the time to completion is compared with InfiniBand benchmarks.
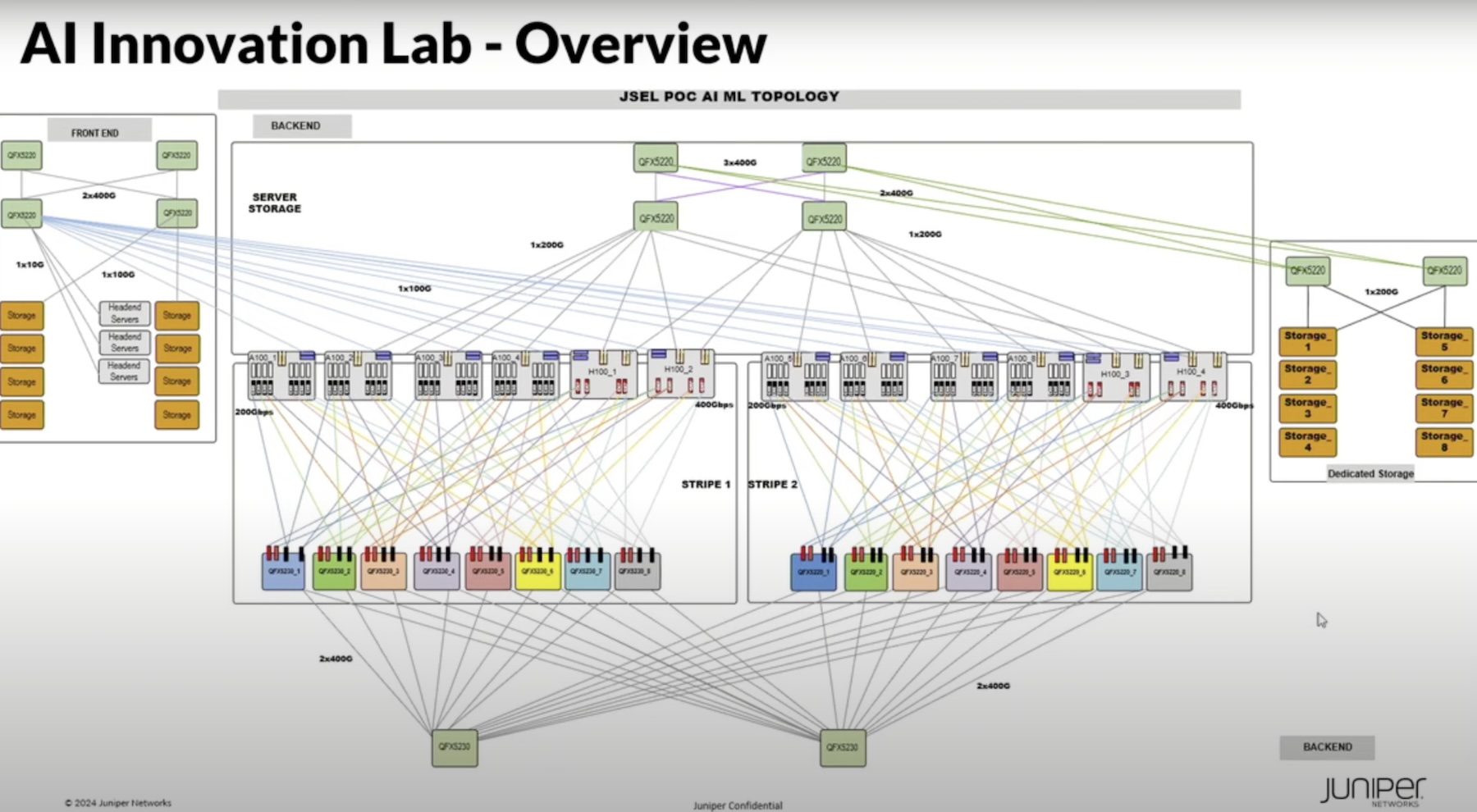
The infrastructure in use comprises 64 A100 GPUs and 32 H100 GPUs, together with a dedicated high-performance WEKA storage system and a shared storage for everything else. The backend GPU network, Lalchandani highlighted, featured a leaf and spine design that connects the A100 servers over a 200G Ethernet fabric, and the H100s over a 400G fabric.
The systems are connected via a rail-optimized topology borrowed from NVIDIA’s SuperPOD design. “The reason for this rail-optimized design,” he explained, “is to minimize the number of hops through your fabric.”
The only thing Juniper Networks has done differently is swap out InfiniBand switches for Ethernet ones.
Busting the Common Myths
Models like Bert-Large, DLRM, Llama2 and GPT-3 were ran on the system, and the results were nothing short of shocking. The JCT achieved on the A100 GPUs for Bert-Large was 2.6 minutes, which according to MLCommons benchmark, is between 2.5 and 3.3 mins on InfiniBand.
For fine-tuning, it was 7.9 mins on the H100s which maybe slightly under InfiniBand, but Juniper Networks is hopeful about the numbers because the test was ran on half the number of GPUs as that of the closest InfiniBand benchmark.
Lalchandani cited an independent research conducted by ACG that shows that over a time horizon of 3 years, InfiniBand’s TCO is 122% greater than Ethernet. A big reason for that is Ethernet is open and GPU-agnostic, and InfiniBand is not.
It is believed that a lossless network is essential for the backend GPU fabric. Again Lalchandani addressed it with evidence-based argument.
“There are some scars from the HPC world where losing a packet was really bad and they have carried those scars into the AI world,” he remarks.
Turns out, packet loss in AI training does not have the same implications as in HPC.
Lalchandani explained that Ethernet does network congestion control differently than InfiniBand. It uses a combination of two techniques – Explicit Congestion Notification or ECN and Priority-based Flow Control or PFC. Together they can create a fully lossless network.
But is it an absolute necessity for AI? To find the answer to that, Juniper Networks initiated model training with either and both features turned on. In the first scenario, packet drops were noticed, and in the latter, there was none. But quite shocking, they evidenced an 8% degradation in performance in the lossless scenario.
“A job doesn’t fail. There’s some retransmissions that can happen,” he said. “Maybe in the HPC world, there was some different behavior but here our job doesn’t fail.”
Juniper AI Lab is open to all customers interested to test out their models confidentially, and for them, it serves as a design lab for architecting AI networks.
“All the best practices and learnings feed into Juniper Apstra so that users can get our learnings from the lab into designs they deploy for AI clusters.”
Wrapping Up
With Ultra Ethernet in the works, Ethernet is poised to lose its meh image, and in the not too distant future, stand shoulder to shoulder with its biggest competitor. Juniper Networks makes a strong business case for Ethernet for AI innovation. Not only is it substantially more cost-effective, and simpler to operate, but with the right network design and architecture, it can be a technology as good as InfiniBand for AI networking, if not better.
For more on this, be sure to watch Juniper Networks’ presentations from the Cloud Field Day event.