
A massive gap exists between the new world of DevOps and traditional enterprise IT. DevOps is predicated on rapid, iterative deployment, whereas enterprise IT typically works on a traditional waterfall process. Changes are made in massive batches and the underlying infrastructure is inflexible and heterogeneous. The new wave of DevOps in IT doesn’t want to care about infrastructure, look no further than the term “Serverless” to get a sense of this attitude. When it comes to storage, there’s also a deeper issue at play. While compute and networking find it relatively simple to adapt using advancements like virtualization and software-defined overlays, the kind of flexibility demanded by microservices and the latest software development approaches actively rejects traditional data storage concepts.
Traditional storage has struggled to keep up. Widespread adoption of the cloud has dragged many of us out of our traditional datacenters, squinting into the bright light of world with unlimited compute, networking, and storage. We are now tasked with providing support for the full stack across both our on-premises environments and public cloud deployments. We need truly integrated data management that spans clouds and traditional enterprise data centers.
The DevOps Mindset
Applications are increasingly being developed with a unified development and operations approach known as DevOps. The key to this concept is a focus on rapid development, testing, and deployment through automation and monitoring of software solutions. Although the concept has been adopted in various ways, most DevOps practitioners focus on an integrated process and a set of tools beginning with coding or planning, and proceeding through packaging, release, configuration, and monitoring. The goal is to create an iterative feedback loop that cycles into the next planned sprint.
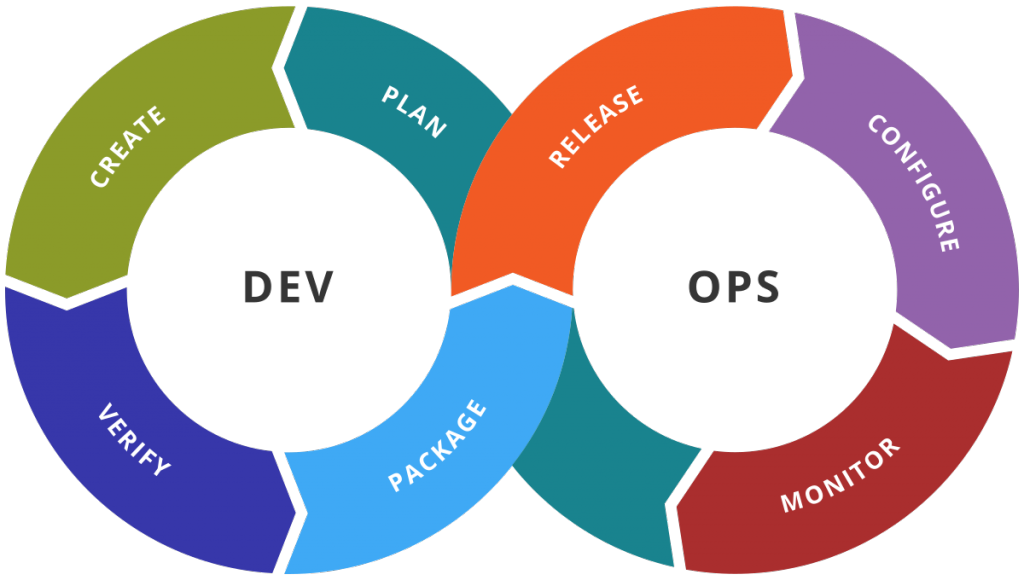
The process is most often codified in a Continuous Integration and Delivery pipeline. Each stage of the pipeline can be considered a gate that includes some set of automated and manual processes. The ultimate goal is creating a release that has been tested and validated. Ideally, each stage in the pipeline is as automated as possible. As such, all of the steps in the DevOps toolchain will require software access to manage and implement changes.
This mindset breaks down the traditional walls between applications and infrastructure that has been de rigueur in enterprise IT for many years. It also challenges the intrinsic separation of elements of infrastructure administration found in most enterprise IT shops: Application, database, compute, network, and storage. If infrastructure is code, as DevOps practitioners would like, it must be unified, standardized, and managed through APIs rather than by separate specialist teams. That is not to say that there is no place for specialization in a DevOps team, rather each member is expected to have deep knowledge in a few key areas, with enough generalized knowledge of adjacent areas to understand the points of integration.
Just as DevOps has been on the rise, so has virtualization and the commoditization of enterprise infrastructure. Virtualization solutions standardize all hardware as a means of achieving portability and flexibility of infrastructure. Rather than installing an application, operating system, or drivers on special-purpose hardware, virtual environments create a pool of resources that appear, from the operating system up, to be identical. This has come at the same time as enterprise hardware has standardized on commodity x86 CPUs with similar capabilities across various types of servers. Instead of speaking about servers at the physical level, we now tend to abstract the underlying levels into a pool of compute that can be leveraged by a higher level object, whether that is a virtual machine, container, or serverless function.
The network has started to follow the same path of virtualization and commoditization. Just as compute infrastructure created an abstraction layer for operating systems, networking has used technologies like VLANs to create separation between the physical layout of a network and the logical segmentation of that network. With the introduction of software-defined networking, especially VXLAN and NSX, a further layer of abstraction has been added so that overlay virtual networks can function independent of the underlay networks, including access to the layer 2 (MAC address) and layer 3 (IP addressing) portions of the network stack.
Traditional datacenter storage has become standardized on a handful of protocols. Essentially, there is block or file based storage, with the more recent entry of object-based storage. Network attached storage would typically use NFS; storage area networks would either use iSCSI or fiber-channel. When one needs to provide storage to a host, it would be in the form of a LUN or remote file system. There are points of differentiation between the various storage array vendors and newer products like vSAN or Storage Spaces Direct. But boiled down to essentials, they are all using the same protocols and standards to provide storage to compute resources.
This level of standardization, virtualization, and commoditization also came to storage with similar results. Today, most traditional enterprise IT shops prefer API access to manage specialized devices and look for integrated management platforms. As systems are increasingly managed the same way, their unique elements begin to fade in significance. Commodity hardware and “software-defined” infrastructure are more attractive when management is prized over all else.
Virtualization, commoditization, and DevOps are colliding in today’s enterprise. Developers were traditionally not as involved with infrastructure, and today have a multitude of options to consume infrastructure as a service without needing to understand the underlying mechanisms. Infrastructure is simply a means to an end: Running an application. And many applications now run on cloud platforms, locally or remotely, that abstract away all hardware concepts. In many ways, DevOps needs to be the sherpa navigating the development team through the unfamiliar territory of infrastructure.
DevOps to Multi-Cloud
One could say that DevOps is infrastructure-agnostic or even infrastructure-antagonistic. After all, specialized infrastructure, whether compute, storage, or network, just makes the job of application deployment more difficult. Traditional datacenters were built in an organic fashion over time. Often they do not represent a single vision or guiding principle in their design and components. In the same way that Conway’s law predicates that a company’s software development will mirror their organizational structure; the traditional silos between various teams in the datacenter have led to non-standard, highly heterogeneous environments that represent the organization that created it. Rigid separations, and bespoke environments are anathema to the DevOps practitioner. As applications move to the cloud, DevOps has attempted to sever links to the traditional IT stack.
What does DevOps want? Limitless infrastructure, flexibility, and integration is the ultimate goal. Software should be developed without being tied to “what’s on the floor”, as is the case when it runs in the cloud. Not only does the DevOps practitioner not need to care about the physical hardware in a cloud datacenter, they have no access to that layer of the infrastructure anyway.[1] Public cloud providers like AWS and Microsoft Azure provide a standard interface for allocating resources and controlling the lifecycle of those resources. This public facing API enables those in DevOps to easily automate tasks that would have traditionally been manual multi-step processes in their on-premises datacenters. Imagine provisioning a petabyte of storage for a big data project in a traditional datacenter. Assuming that there is an array capable of serving up that quantity of storage, the process of provisioning the storage would require the involvement of at least a storage administrator, a virtualization admin, and possibly a network administrator. In the cloud, petabytes are just an API call away. Massive scale and redundancy is not a complicated, multi-departmental operation, it’s a budget line item. The available scale of resources is limited only by the depth of an organization’s wallet. The principles of DevOps and public cloud line up so perfectly that DevOps is often synonymous with cloud platforms and services.
The common next step for many DevOps teams is to make the leap to multi-cloud. After all, why should applications be tied to a single cloud provider? Their quest to deploy applications rapidly to any environment includes being able to deploy to multiple public clouds. It seems counterproductive to abandon the traditional datacenter only to be locked into another provider.
But multi-cloud faces the same challenges of traditional infrastructure. Different cloud platforms and providers have different capabilities, APIs, and solution offerings. The difficulty and cost of maintaining the same application against more that one public cloud provider may outweigh the potential benefits. Add in the possibility of maintaining that same application across the private datacenter with multiple public clouds and it’s enough to make a DevOps person throw their hands up in disgust (or kick off a deployment pipeline that automates their disgust via an API call). Rather than giving up, stalwart DevOps practitioners forge ahead looking for ways to deploy against multiple cloud platforms.
The Problem of Storage
In this quest for ultimate flexibility, a hard barrier looms upon the horizon. Storage simply does not lend itself to the flexibility demanded by DevOps and cloud platforms. Moving data takes time. This introduces latency and the need for asynchronous approaches. Management and protection of data is critical for every enterprise application. This is compounded by a general lack of knowledge of storage concepts, even among seasoned application developers.
Modern enterprise storage systems combine high performance, flexibility, and features on a core of absolute data integrity. This is the prime directive for storage: Data can never be lost. This is one reason that storage systems have evolved slower than many other IT infrastructure elements. Before a storage solution can be trusted, it must be proved to be completely reliable.
Data is the new oil. Data is the new bacon. We’ve probably all heard some variation of this phrase. And while it’s popularity might seem like a bunch of marketing fluff, it does speak to the reality for enterprise IT. For the large majority of industries, data is the thing that drives business decisions, brings in revenue, and keeps them in compliance. Data loss or corruption is not like a missed packet in the network or a crashed operating system. Data loss has the potential to be an existential threat to business viability. Storage administrators are thus rightly concerned about data durability in an environment, and much less concerned with exploring hot new trends in IT. If containers are disco, storage is Tchaikovsky.
As storage has become more commoditized, storage vendors have struggled with ways to differentiate their products and solutions. Storage reliability is not the primary selling factor for many solutions today. Most new storage devices are positioned in terms of performance, specialized integrations, or advanced data management features. This is what separated successful storage solutions from the pack for decades. Whether or not storage administrators and IT practitioners actually wanted all this diversity and specialization, they were pushed into it by the vendor landscape that was constantly searching for a way to make their array stand out from the competition. This resulted in a large number of non-standard, proprietary features in storage arrays that made them more difficult to manage between different generations of hardware from the same vendor, let alone trying to manage solutions from multiple vendors.
Rather than doubling down on all this specialization, cloud storage has been simplified dramatically. Following the lead of Amazon Web Services EBS and S3, most cloud platforms offer two basic storage services: Simplified block storage and distributed object storage. The former is typically stripped of all features and capabilities. In what would seem heretical to storage administrators, these cloud block storage solutions may not even be required to be reliable. The assumption is that data durability will be provided at the application layer, instead of by the storage platform.
More recently, the public cloud vendors have been moving to provide file-based storage that is similar to NAS in nature, such as EFS from Amazon Web Services or Azure File Storage from Microsoft Azure. These solutions are a step in the right direction, but many traditional enterprise applications that use file-based storage expect additional NFS or SMB functionality that is not available in these solutions. Organizations looking to move their workloads to the cloud are instead required to provision file-based storage through Infrastructure as a Service, backing those VMs with block based storage and installing traditional NAS stacks on top of them. This is not just inefficient, it is also costly and not in line with the ethos of using Platform as a Service wherever possible in the public cloud.
The challenge has been how to bring enterprise storage to cloud in a way that is truly “cloudy”. Most old-fashioned NAS or distributed file solutions can function in the cloud but are not really integrated with the management and deployment capabilities touted by cloud providers. And those that truly are “cloudy” are often not integrated with traditional data center storage.
Data in Different Clouds
What does a multi-cloud DevOps world want from storage? First of all, it must be truly “cloud first” in that it integrates completely with all other elements of the cloud platform. The whole point of using Platform as a Service is to abstract away the underlying infrastructure and simply consume the service through an API. It also must function similarly regardless of location, on-premises or at various cloud providers. And it must offer push button data services that support enterprise applications, including geo-synchronization, automated backups, and point-in-time recovery.
This is an elusive offering, and has proven exceedingly hard for conventional storage companies to develop. There have been a number of approaches, each with the attendant pros and cons.
Stretch Your Datacenter
Many would be happy with a physical connection between enterprise and cloud, providing storage from the datacenter to the workloads in the cloud. This is not cloud storage, just storage adjacent to the cloud. It doesn’t address the “as a service” purchasing model familiar in the cloud. Additionally, one can only imagine how well a storage solution would perform when being consumed over a WAN connection. The volume of data being generated combined with a requirement of low-latency access makes this solution a non-starter for most modern applications.
Build it on IaaS
Some storage vendors have decided to offer their existing enterprise storage solution in the cloud by using the Infrastructure as a Service offerings from each public cloud. This essentially creates their storage array on virtual machines. While functional, this doesn’t bring anything new to the table. The same functionality that existed on the storage array in the datacenter now exists in the cloud. Additionally, the storage vendor does not have low level access to the hardware driving the virtual machines, so some of the secret sauce that exists in their physical arrays cannot be implemented in the cloud. The larger problem is that such a solution is not integrated natively with the rest of the cloud stack. And it does not add the features a DevOps admin would want, like programmatic access and automated deployment.
Build a Storage Abstraction
It is tempting to approach multi-cloud storage with a virtualization or management platform layer on top of disparate “local” storage solutions. Integrating storage solutions becomes difficult as each service could have substantially different underlying capabilities or characteristics. Although most simple block storage is similar, performance can vary widely. And even with similar offerings, certain characteristics (capacity points, performance levels, etc) can be quite different. These issues become exacerbated when looking at the wider offerings with object storage. Not only do these vary but they offer a bewildering array of different capabilities. The only way to make this solution moderately functional is to start with the lowest common denominator of functionality from each cloud vendor. While that LCD may be perfect for a small handful of solutions, chances are that most DevOps practitioners would not want to sacrifice all the additional functionality in each storage offering for the marginally simplified deployment model.
Multi-cloud storage also presents many challenges for data management.. How do you move data between various block or object storage platforms without downloading it and transiting it across captive networks? How do you verify that data is secure and unchanged across platforms? Quality data management requires similar storage on both sides, but this is not possible in many cases.
Addressing the Multi-Cloud Challenge
We heard about this challenge during NetApp’s Cloud Field Day 3 presentation. With the acquisition of GreenQloud, the company attained an interesting multi-cloud storage integration solution. But as important as the technology was the personnel GreenQloud brought. As related during the presentation, maintaining a “cloud-first” approach requires an almost “pirate” approach by this group. They must continually push forward with a cloud focus to retain the advantages that attracted NetApp to them in the first place.
Cloud-first is a mantra heard all too often from corporate talking points. Hearing a company talking about going cloud-first is almost table stakes at this point. Eiki Hrafnsson, Technical Director Cloud Data Services, was quick to point out this skepticism in his talk. He acknowledged that too often, cloud-first is more of a buzzword than an actual approach to the design of new solutions. And so he defined what was meant by cloud-first, including:
- Made for automation
- Consistent functionality across environments
- Usage based billing
- Integrated with public cloud services
- Guaranteed performance and availability
This cloud-first approach certainly seems to line up nicely with the wishlist of a DevOps practitioner. And that shouldn’t be surprising, as GreenQloud was a public cloud provider prior to being acquired by NetApp. The solutions that they created were based on providing services to their clients, and were shaped by the feedback of those clients. Add in the fact that Eiki is a developer himself, and it’s not shocking that his approach exemplifies what a modern DevOps team would be looking for.
There is a big hurdle to overcome with a cloud-first solution from a third-party vendor like NetApp. The solution has to get the buy-in and integration from the public cloud vendors to appear as a native solution, rather than an add-on service. NetApp has been able to achieve that buy-in and deploy “Cloud Volume” storage offerings in both Google Cloud Platform and Microsoft Azure, connecting it with the various technologies included in their Data Fabric concept. The addition of the GreenQloud storage management layer brings true integration to these cloud platforms with a “cloud-first” approach.
Creating a multi-cloud storage solution that actually provides additional value without sacrificing functionality is no mean feat. The Cloud Volumes solution doesn’t fall into the pitfall of only providing the lowest common denominator of functionality. Instead, it appears that NetApp has created a solution that has improved functionality, and improved performance over the native storage constructs in the major public cloud vendors. This type of overlay solution is similar to what already happened with container orchestration engines in the public cloud. AWS and Microsoft Azure both initially had their own container management platform, ECS and ACS, respectively. As Kubernetes rose to prominence, both vendors created a container service based entirely on using Kubernetes, EKS and AKS. If an organization wants to deploy containers with a DevOps approach then Kubernetes now becomes the common platform to deploy solutions against, regardless of the environment being targeted. Ideally, NetApp’s Cloud Volumes can perform a similar function for cloud storage, becoming the platform upon which storage is provisioned regardless of the environment. That may seem like a long shot, but on the other hand, Kubernetes has only existed for four years. Technology moves fast, and this is the first storage solution that seems to move the needle forward for the multi-cloud storage challenge.
Stephen Foskett contributed to this article.
[1] For those who are pedantically inclined, bare metal servers do indeed exist in the cloud. I have found that they are not an appropriate solution for the vast majority of workloads.