Look at IoT, autonomous driving, or video surveillance, and you’ll quickly see why organizations need to continuously process, analyze and make decisions on data in near-real-time. Fortunately, many technologies like in-memory storage or stream processing can help organizations quickly glean insights from their data. At April’s Tech Field Day event, Hazelcast spotlighted its application platform for delivering in-memory storage, stream processing, and distributed computing for data-intensive workloads on-premises, at the edge, or in the public cloud.
Keeping the Data Flowing
Data fuels applications. With data-intensive workloads like IoT, telemetry, and video surveillance, this is especially true. And, in these workloads, latency and throughput matter. These are not the workloads that an organization would want to run slow on hard disk drives.
Instead, these demanding workloads rely on an assortment of technologies like hardware acceleration cards, solid-state drives, caching tiers, or persistent memory to keep the data flowing. Likewise, if these organizations run data pipelines, they’ve probably abandoned traditional batch processing jobs that could take hours to process and analyze data in near-real-time with stream processing. Faster storage coupled with stream processing can enable organizations to unlock insights from their data faster.
Accelerating Data-Intensive Workloads From the Cloud-Native to Mainframe Systems
At their Tech Field Day appearance, Hazelcast spotlighted its application platform for in-memory storage, stream processing, and distributed computing. Designed for data-intensive workloads, Hazelcast Platform can be deployed on-premises, in the public cloud, or at the edge.
Additionally, Hazelcast can be consumed as a fully managed cloud service. Because Hazelcast acts as a data processing layer, it doesn’t replace an organization’s existing databases or systems of record. Hazelcast can be integrated with a broad spectrum of applications from cloud-native to mainframe. As a self-professed Cloud-First platform, Hazelcast supports Kubernetes and VMware Tanzu and Red Hat OpenShift deployments.
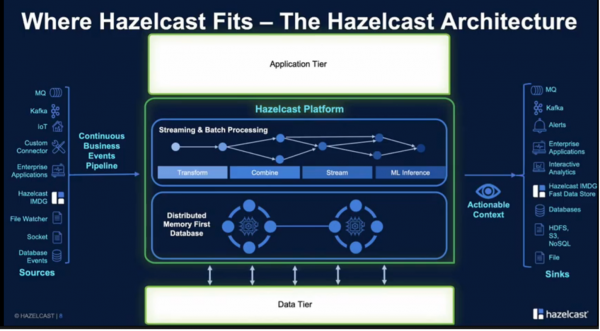
Moving the Data Near the Application Code
Traditionally, in application workloads, database servers and web servers live in separate clusters. Hazelcast shifts this paradigm, however, by moving data alongside the application code. By storing the application code and data within the Hazelcast scalable, distributed computing clusters, applications access data much more quickly since there is no need to traverse the network. Data gets stored locally in an in-memory store.
To leverage Hazelcast, developers typically need to make minor code changes to their applications, like swapping out a java map for a Hazelcast map. Hazelcast is Java-based, but its API supports building applications in languages like Go, C++, Python, and JavaScript. Hazelcast Platform’s embeddable code is lightweight enough to be deployed on edge servers. The lightweight footprint of Hazelcast Platform supported also makes it compatible with microservice deployments. While Hazelcast is open source, Enterprise Edition includes additional features like security framework, disaster recovery, and professional support.
Conclusion
As much as technology continues to evolve, many organizations will still support legacy data systems for the foreseeable future. Hazelcast Platform, a software-based solution, can bridge the gap between these legacy systems and allow organizations to couple this data with cloud-native architectures like microservices. Often this backward compatibility means sacrificing performance. However, Hazelcast Platform is incredibly performant and is heavily used by many industries, including financial institutions and e-commerce sites.
Hazelcast Platform can process in-memory and streaming data requests for a broad spectrum of workloads from cloud-native to mainframe. Additionally, having an application platform that brings operational consistency on-premises, at the edge, or in a public cloud is a great business benefit. To learn more about Hazelcast’s streaming and memory-first application platform, tune into their April Tech Field Day presentation.