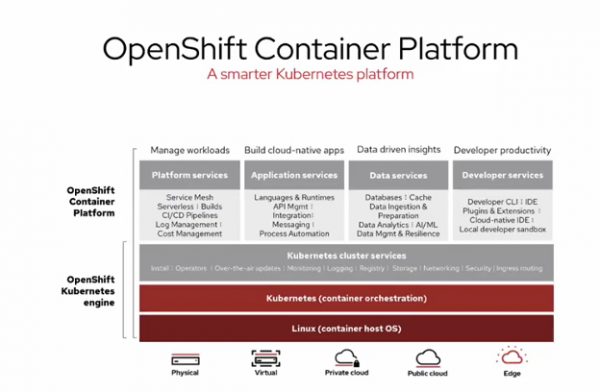
As organizations modernize their applications, some of these workloads might skip the public cloud and move straight to the edge. Putting compute close to the data can significantly improve performance time, and with some applications, that means the difference between success and failure. Red Hat’s OpenShift Container Platform, though, has multiple configurations that allow it to run Kubernetes not just at the edge but as-a-service in the public cloud and on-premises.
Workloads Move to the Edge
All workloads moving to a Public Cloud is an idea that has yet to come to fruition. The truth is hybrid and on-premises are viable alternatives for places to run applications. Increasingly, workloads are moving to the edge. By moving compute closer to the data, applications can eliminate some of the latency that might come from extra hops to the Public Cloud. In applications like self-driving cars that generate a lot of data, compute at the edge enables the AI/ML algorithms to make real-time decisions from all sensor data. Increasingly, other AI/ML workloads end up at the edge.
Many of the same considerations that apply to public and hybrid cloud also apply to the edge. As organizations diversify where their workloads run, operational consistency still matters. Without a centralized solution, organizations risk each edge server becoming a silo with a slew of management burdens. The operational complexity of siloed edge computing can negate the performance and potential cost savings of hosting workloads at the edge. The market is ripe for solutions that can simplify and bring central management to disparate environments.
OpenShift Everywhere, Including the Edge
At Tech Field Day 22, Red Hat featured the OpenShift Container Platform and the myriad of supported environments, focusing on the edge. Private cloud, public cloud, physical infrastructure, virtual infrastructure, and the edge all can run OpenShift. OpenShift at the edge hadn’t been previously presented at a Field Day event until this Tech Field Day. Red Hat defines the edge as the infrastructure edge and also the last-mile edge server or gateway.
Edge Computing with OpenShift
One of the primary drivers of edge deployments at the edge is Artificial Intelligence (AI). Industries embracing AI at the edge include automotive, manufacturing, retail, health-science, energy, and public sector. To help streamline and normalize deployment, Red Hat created a GitHub repository with Solution Blueprints that contain codes that codify infrastructure, documentation, and other resources. One of the initial Solution Blueprints for Edge Deployments focused on AI/ML. To learn more about Red Hat Solution Blueprints, visit GitHub.
Currently, there are three edge compute configurations for OpenShift. A new offering (expected in 2021) is the single node edge servers. These servers are best for disconnected or low connectivity and bandwidth environments. Remote worker nodes for space-constrained locations are represented by remote nodes. And a three-node deployment provides high-availability.
Red Hat Advanced Cluster Management (ACM) can unify and simplify the management of any OpenShift deployment, including those at the edge. ACM connects to an agent running on the nodes and serves policy. Offline nodes can check in when they gain connectivity. The central management of ACM brings the ability to manage the fleet across disparate edges.
Conclusion
Operational consistency is a key part of any cloud-native architecture. Red Hat has been on a quest to create a more easily consumable Kubernetes platform and operational consistency helps make this happen. Red Hat brought OpenShift Container Platform support to the edge in the form of three new deployment models, and these models make it easier to run AI/ML at the edge.
To learn more about OpenShift Container Platform, check out Red Hat’s presentation from Tech Field Day 22.



