
For years, network engineers busied themselves finding solutions to last-mile problems. But it now appears that committing to a different part of the process would lead to a better result.
In networking, there is a lot of chatter about troubleshooting and user experience, but boring bits like configuration and observability that are pivotal to delivering elevated user experience are often sidetracked. At Tech Field Day Extra at Cisco Live EMEA 2024, Cisco presented a game changing approach known as event-driven automation. Event-driven automation makes a compelling business case by simply taking the manual effort out of network automation and replacing it with predefined automated response.
Human-Driven Automation Is Not Really Automated
Network observability and automation are heavily manual processes where most of the action is done by hand. The usual way of automating configuration through IaC tools like Terraform, or configuration management tools like Ansible, takes operators through a painstaking device-by-device configuration process. Not only is this rigorous, but also excessively laggy, and thereby largely inefficient.
To steer around that, some organizations invest in network controllers. Network controllers serve as the central point of contact for all devices, keeping inventory of everything within the network and their states.
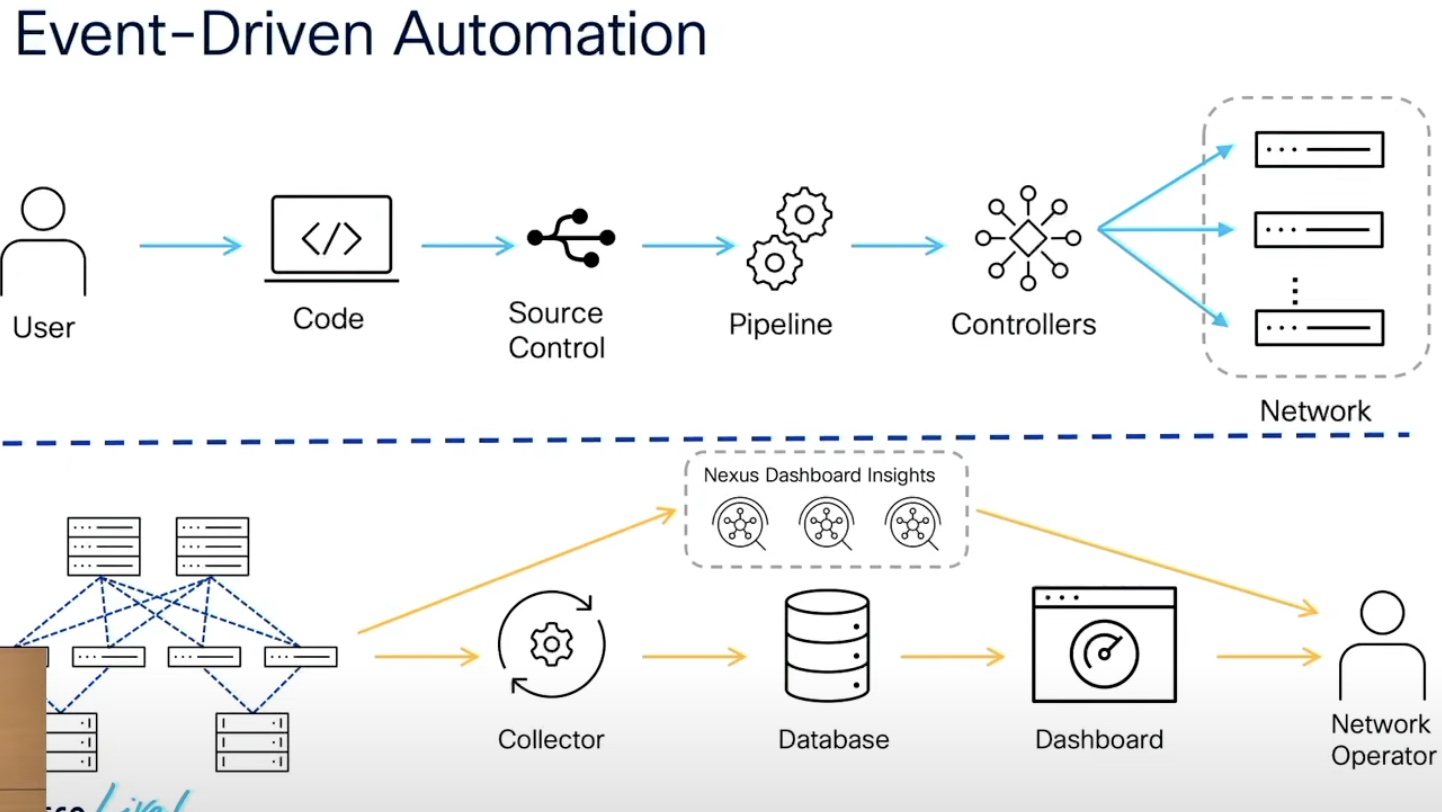
The automation pipeline looks something like this – the collector picks up configuration and state data from the devices. This data is written to a central database. A dashboard, either proprietary or open source, analyzes and visualizes the data. A monitoring tool sits in the network observing the events and generating alerts.
But no matter what the pipeline looks like, it’s always on the operator to do the last leg of investigative work – slicing and dicing the information, triangulating the problem and initiating change in accordance.
“You man the configuration, but you’re building a separate solution to monitor the fabric. Eventually there is no cross between the two,” says Shangxin Du, Technical Marketing Engineer at Cisco.
Taking the Delay and Disruption Out of Automation
What if you wanted these odd steps to happen in a single automated workflow? Event-driven automation breaks the wheel and forges a direct path from discovery to remediation. “Event driven automation tries to stitch these together, basically using whatever data is collected from the collector, and take that feedback to the automation pipeline and help auto-remediate the problem,” Du says.
By doing so, it essentially allows operators to ditch the manual steps of ticket generation, fact gathering and troubleshooting allowing it to happen as one automated action. To put it plainly, it triggers responses automatically to all changing conditions in the environment.
“Event-driven automation is basically how you stitch the two parts of configuration automation and network monitoring together, explains Du. “Essentially it’s trying to use whatever happened in the network to automatically change the network configuration or to remediate or mitigate risks.”
This has two key outcomes, reduced manual work because of fewer repeatable steps, and a shorter mean time to resolution (MTTR). Du points to four key use cases for event-driven automation. GitOps or the process of infrastructure automation benefits greatly from this as it makes managing and responding to events automated in a real sense. No matter where event info comes from, it can be used to integrate and automatically deploy the IaC.
One type of event that is low-risk and repeatable is provisioning new equipment. With event-driven automation, servers and endpoints can be swiftly auto-configured and added to the network without raising a ticket.
Responding to events on auto-pilot can be tricky considering how much the necessary response varies from case to case. Event-driven automation may not be the one-size auto-remediation solution for the most complex cases, but it is versatile enough to trigger the best course of action for a wide range of events that, if anything, helps minimize the risk.
For convoluted events that event-driven automation cannot fix, it collects data from concerned parts of the network or device to assist mitigation. Ticket enrichment helps jumpstart root cause analysis, ultimately accelerating MTTR.
Network Observability and Automation with Cisco
In the presentation, Du covers the pervasive observability and automation capabilities of Cisco NX-OS and ACI, parts of the Nexus datacenter switches. NX-OS supports two kinds of streaming telemetry features – dial-in where operators can dial into the switch and get specific data out of it, and dial-out, to stream raw data out of NX-OS. “Configuration data is fairly easy. You already have that in Ansible playbook or agency. But operational data is runtime data. You can only get it from switch, and no other place,” reminds Du.
The nucleus of the ACI fabric is Application Policy Infrastructure Controller or APIC. APIC is designed to manage configuration and stream operational data for health monitoring and performance optimization. “This is built with API since day one. So you can use REST API to query or you can passively cable query.”
Cisco has developed several Nexus OS-supported Ansible modules and playbooks that can be used to enforce end-to-end automation of change management. For Terraform, it has NX-OS Terraform Provider that can be used to build a Nexus EVPN fabric.
Check out Cisco’s cloud networking presentations or catch the demo from Tech Field Day Extra at Cisco Live EMEA 2024 for a technical dive deep.