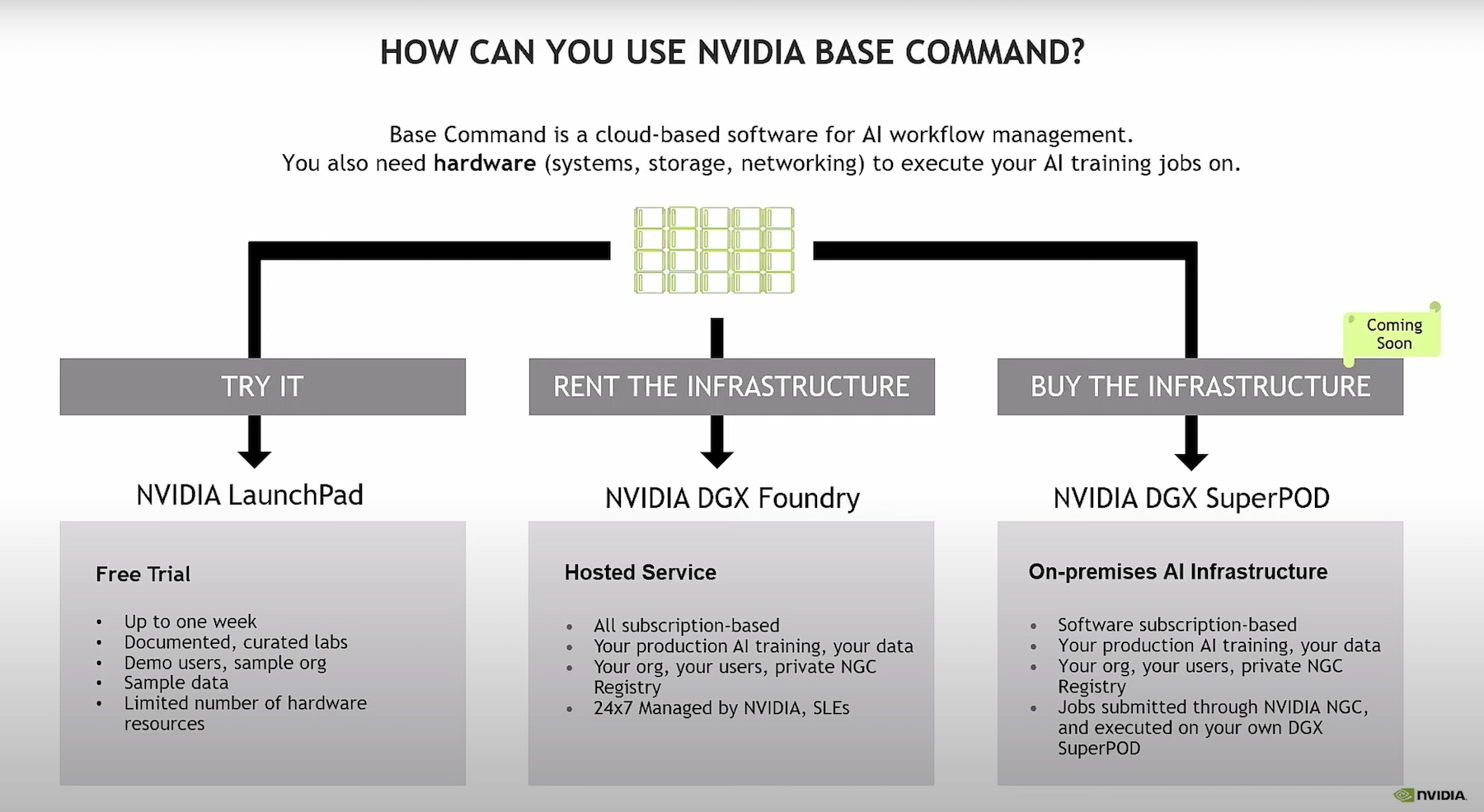
Openness, it seems, is “in the air.” While the Liqid folks were over at OCP, I was over at the Open Networking Summit (ONS), where I (primarily) attended the Linux Foundation (Networking), or LF(N), board meeting. What was interesting at this year’s summit is just how little the focus of open network is on bare metal routers and switches, and how much of the focus is on server-based and overlay networking. The last mile, as it were, in the data center is becoming ever more important. This just shows the question hanging over the network has not changed much in the last twenty years: how much intelligence will be pushed into the network, and how much in the host?
End-To-End
The original researchers and engineers who put the Internet together sometimes (though not always) worked by the end-to-end principle, which argued that the network should be transparent to the host or the application. The concept of hosts and applications have become must more diffuse in the years since these original researchers and engineers did their work, but the discussion around end-to-end has reverberated since then. Today, the discussion carries on in how much, and what kind of, role the host itself takes in pushing packets.

Composable systems, like Liqid’s, take this one step farther, by using the PCI bus as a network between components. The PCI bus effectively becomes an edge network connecting components, which then connects to the “larger network” through a pool of Network Interface Cards (NICs), perhaps using a standard set of NIC drivers, or perhaps using DPDK to allow applications running on the composed system to push packets directly to, and pull packets directly from, NIC cards shared over the PCI core. These composable systems expose the inner workings of the host as a network, much like a disaggregated design removes chassis routers and switches, replacing them with smaller, more exchangeable devices on the network side.
The result is, perhaps, a different sort of end-to-end design. A design based around disaggregated systems, based on open networking standards, and built out of smaller devices connected into a greater whole. Each part is replaceable, and the communications between the different pieces are more transparent to the system operator. There are two different kinds of networks connected here, one optimized for connecting the components of compute into a “host,” the second optimized for connecting “hosts” to one another through a high-speed fabric. Each can be scaled independently using different kinds of technologies.
Approaching Applications
Applications will need to be rebuilt to take advantage of such systems—starting with the entire concept of mobility itself. First, applications will be able to take advantage of the hardware interfaces in such a system to increase performance and reduce processing load. For instance, the recently released ScyllaDB communicates directly from a single core to the NIC using DPDK to improve the handling of packets between the database and the network and uses a single thread per core to improve overall performance. Applications designed on these lines would be able to scale much more quickly, and more flexibly, on a composable system.
Finally, mobility will need to move from the traditional layer 2/layer 3 boundary towards the service level. The application world is strongly focused on layer 2 mobility, which is neither efficient nor fast, and drives far too much complexity into network systems. The composable model works with the container revolution to move the focus from the virtual server to the application, and then from the application to the service. Don’t underestimate the power of this kind of shift.
Make sure you check out Liqid’s major announcements from Nvidia GTC and the Open Compute Summit, including the general availability of the Liqid Composable platform.