AI training is a uniquely data-hungry application, and it requires a special data pipeline to keep expensive GPUs fed. This episode of Utilizing Tech focuses on the data platform for machine learning, featuring Molly Presley of Hammerspace along with Frederic Van Haren and Stephen Foskett. Nothing is worse than idle hardware, especially when it comes to expensive GPUs intended for ML training. Performance is important, but parallel access and access to multiple systems is just as important. Building an AI training environment requires identifying and eliminating bottlenecks at every layer, but many systems are simply not capable of scaling to the extent required by the largest GPU clusters. But a data pipeline goes way beyond storage: Training requires checkpoints, metadata, and access to different data points. And different models have unique requirements as well. Ultimately, AI applications require a flexible data pipeline not just high-performance storage.
A Smart Data Pipeline for the Complex Demands of AI/ML Computing with Hammerspace
As enterprises pursue their AI ambitions, they have a big problem on their hands. For the first time, the realities of the undertaking have started to show themselves. Artificial intelligence is a very complex technology. It is quirky and brittle, and there is much to learn before one can make a go of it. Disappointingly, our understanding thus far is shallow, and just scratching the surface.
In this episode of Utilizing AI Podcast brought to you by Tech Field Day, part of The Futurum Group, hosts Stephen Foskett and Frederic Van Haren, peek under hood and point to a flaw hiding in plain sight in the architecture. Traditional scale-out network-attached storage (NAS), and the data pipeline that we have relied on so far, were never meant to support AI and ML computing.
Molly Presley, Head of Global Marketing for Hammerspace, joins the discussion and talks about a smart data pipeline that the data-hungry applications of AI really need.
Inside the Data Pipeline
A data pipeline is the vehicle that takes data to the GPUs for processing. Its efficiency is directly correlated to the efficiency of the model. The faster it is able to deliver the data, the faster the GPUs can get to work. A prompt and optimal distribution is critical for high I/O workloads like AI and ML as they depend on parallel processing and low-latency data access.
But the traditional NAS architecture is not meant to do GPU computing at scale. Delivering parallel file systems and HPC-level performance that are required to keep the GPUs fully utilized for maximum leverage, is a very hard problem for it to solve. Its strength is elastic capacity, and at its level of performance, it tends to get sluggish as the data volume increases.
There are deeper problems cascading from this. The lack of performance leads to a scant distribution of load to the processors. Without all the GPUs working at full capacity, and many sitting idle because the data never got to them, resource utilization takes a hit while cost spirals upward.
Conventional wisdom in IT is to upgrade when necessary, but there is cost attached to that. “A lot of the customers want to use the storage they already have because they don’t have a budget to go buy a new storage or a new network for AI. There is a lot of considerations just on the economies.,” says Presley. “Then they have preferred storage and preferred vendors. Coming in with a new system isn’t a necessity to them,” she adds.
Also, is a better storage the answer? “To build an AI data environment and know that you’re going to be able to check point, stream the files, do the training, and always keep those GPUs fed is a lot more complex. There’s a lot more involved – the workload attributes, the utilization of the infrastructure, the storage systems. In the end, storage isn’t the solution to keeping GPUs busy. It’s just a necessary place to put the zeros and ones, so to speak,” replies Presley.
Hyperscale NAS for Best Performance and Linear Scalability
Hammerspace works at the hardware layer of these environments, providing a smarter, more nimble architecture. This architecture is purpose-built to do the much-needed optimizations around resource utilization so that performance bottlenecks are never an issue. “In these environments, a lot of GPUs are put to work, and Hammerspace sits next to those GPUs feeding them the data,” says Presley.
Hammerspace Hyperscale NAS is designed to support the faster data cycles of AI/ML computing. Presley explained how the architecture works under the hood.
In distributed environments, data lives across multiple platforms and regions. The most frustrating chore is to obtain datasets from these disparate locations and to do that in a timely way.
“Organizations are trying to figure out if they have to make sure their data is local to their model, or do they have to build their entire environment and datacenter, if they need to move everything to the cloud, or is there a middle ground?”
There are incredible advantages of bringing data to compute, as opposed to taking compute to data. The energy footprint is lower, and cost savings is significant.
An efficient data pipeline plumbs data into all available GPUs, and bursts the surplus into the cloud. “That’s the sweet spot where Hammerspace sits”.
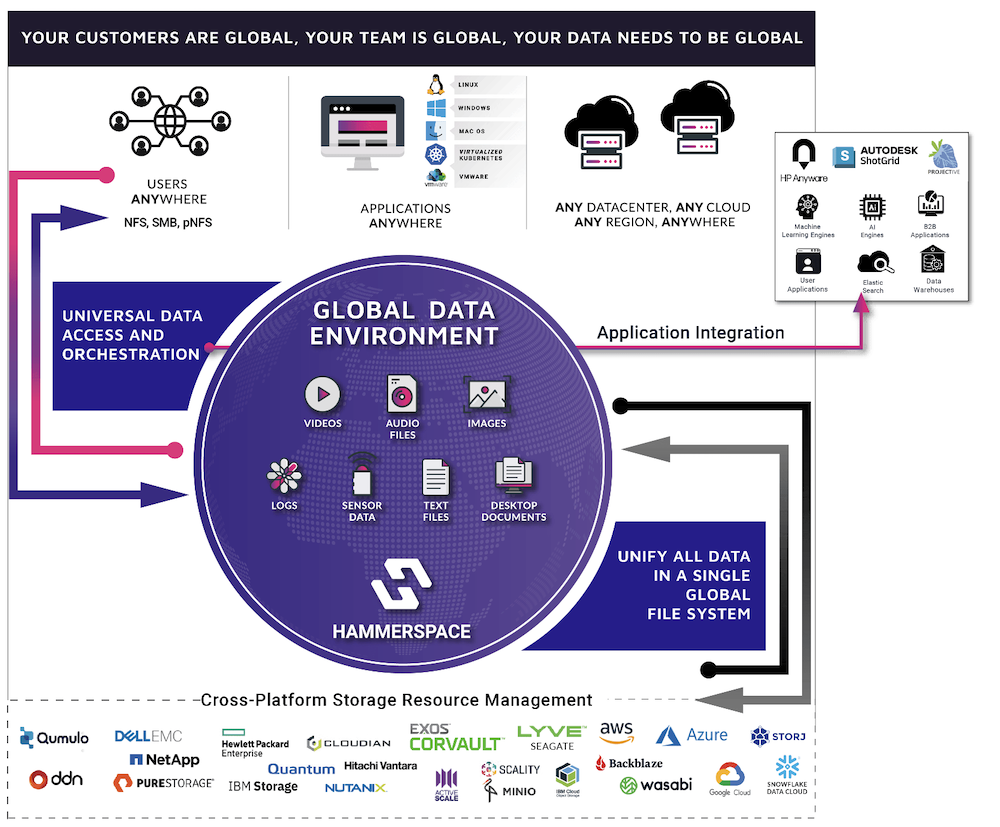
Hammerspace is best defined by its tagline – “Data in motion”. Their goal is to serve up data through a single source of truth. This single source of truth is a universal file system that spans all compute and storage environments, from where data is distributed across the GPUs.
Hyperscale NAS tackles the problem of coalescing data from disparate sources with parallel file systems. “Often there’s a lot of different data sources – different storage systems, localities, things like that. The other piece Hammerspace addresses is ingesting those different data sources into a single file system so the AI models are working with a single dataset even though it may be residing in different storage systems.”
None of this requires a brand-new storage. Hyperscale NAS orchestrates a data pipeline on top of the existing storage system listing the pressures of orchestration off of the storage systems. This pipeline delivers consistent performance across all classes of workloads. The outcome is, hardware that are not designed for GPU computing now have a high-performance data path that delivers data directly to the GPUs.
Presley refers to customer cases to explain how Hyperscale NAS worked for them. Not only were they able to overcome the problem of GPUs sitting idle in the environment, the applications could write data the same way as before because it’s standard enterprise NAS that complies to all data security requirements, she tells.
These success stories “really emphasize that you need to have an optimized data environment for feeding the GPUs and that’s really what Hammerspace does.”
With help of a process called metadata assimilation, Hyperscale NAS consolidates the metadata from all existing storage systems in the environment. Irrespective of the storage system or the volume of data, this assimilation takes only a few minutes. “You’re now working with our metadata and you’re instantly accessing and using that environment.”
This means you even can leave the files where they are, and not move them around unless required. And even if you do, it is done via out-of-band so that the applications are not affected by it. The apps are connected to the metadata the whole time.
“It’s just a different way of thinking about architecting the data pipelines, and data and file systems where the storage system doesn’t own the data. Instead, it’s orchestrated and placed in whatever location or next to whichever computer application needs it,” says Presley.
Wrapping Up
The Hammerspace framework connects everything, letting data flow freely between storage and compute environments with a resiliency that meets the high demands of AI/ML workloads. With linear scalability built into it, Hyperscale NAS can scale up to thousands of nodes while keeping performance steady. Safe to say that AI data pipeline is a solved problem now.
Go to Hammerspace’s website for more resources on this. Watch Hammerspace’s presentation at the AI Field Day event for a deep-dive of the technology. For more such interesting conversations, keep listening to the Utilizing AI podcast. Read more on Hammerspace’s presentation at AI Field Day from The Futurum Group’s Alastair Cooke on their website.
Podcast Information
- Stephen Foskett is the Publisher of Gestalt IT and Organizer of Tech Field Day, now part of The Futurum Group. Find Stephen’s writing at Gestalt IT and connect with him on LinkedIn or on X/Twitter.
- Frederic Van Haren is the CTO and Founder at HighFens Inc., Consultancy & Services. Connect with Frederic on LinkedIn or on X/Twitter and check out the HighFens website.
- Molly Presley, Head of Global Marketing at Hammerspace. Connect with Molly on LinkedIn or learn more on the Hammerspace website.
Gestalt IT and Tech Field Day are now part of The Futurum Group.