Data is the foundation on which AI models are built, and integration of enterprise data will be the key to generative AI applications. This episode of Utilizing Tech brings Nick Magnuson and Clive Bearman from Qlik to discuss the integration of data and AI with Frederic Van Haren and Stephen Foskett. Enterprises sometimes worry that their data will never be ready for AI or that they will feed models with too much low-quality data, and overcoming this issue is one of the first hurdles. Another application for machine learning is improving data quality, organizing and tagging unstructured data for applications. The concept of curated data is an interesting one, since it promises to elevate the value of enterprise data. But what if a flood of data causes the model to make the wrong connections? If data is to be a product it must be profiled, tagged, and organized, and ML can help make this happen. The trend of generative AI is driving budgets and priorities to make data more useful and organized, but even unstructured data streams can be valuable. The application of large language models to structured data is promising as well, since it enables people to query these data sets even if they lack the background and skills to construct queries.
Generative AI is having its moment under the spotlight. But experts are worried that bad data can take away from its potential. In this episode of the Utilizing AI podcast, co-hosts Stephen Foskett and Frederic Van Haren talk to Nick Magnuson, Head of AI, and Clive Bearman, Director of Product Marketing, at Qlik, about the power and potential of data, and why a clever data strategy is critical to getting the most value out of GenAI.
Data and AI Shares a Symbiotic Relationship
2022 was a steppingstone year for GenAI when OpenAI unveiled ChatGPT. In an instant, the chatbot wooed the crowd with original writing, and in-depth discussions. It’s ability to describe subjects in painstaking details makes AI feel like magic.
An adoption surge has begun, and every big and small company is seen dipping its toes in the AI waters. But it is slowly dawning on enterprises that tools like it can be unreliable. They often veer from the truth, and give back false reponses. To understand why a chatbot that can sense, think and act like a human being, would spew nonsense at times, it’s worth digging into its inner workings.
Tools like ChatGPT are large language models. LLMs are trained on large amounts of data, and millions of parameters. So, to get the most reliable results out of them, data is the differentiating factor.
“The reality with data and AI is they’re interrelated. Data is the foundation on which AI models are built, and it’s important that you have a high degree of integrity, conviction and confidence in the data under which a model is built,” says Magnuson.
The origin of data that is fed into the models is slightly obscure. But if you look at the most prominent algorithms, a bulk of the information comes from the Internet. LLMs like ChatGPT make extensive use of publicly available resources, and process them through neural networks to make interpretations.
Scraping information off of the internet is the obvious thing to do when vast amounts of data are involved, but lack of tuning and overreliance are causing these models to exhibit anomalous behaviors. The models, by themselves, are unable to distinguish between a veritable source and one that is not. As a result, it indiscriminately sources information from both, making the results unreliable.
A Smart Data Strategy
Using the right datasets can cure the confusion, says experts. Structured enterprise data is organizations’ best bet as they have control and stewardship of it. According to a recent Deloitte survey, about 74% companies are experimenting with modernizing their AI data. So we asked, what are the common problems they encounter.
One of the problems that organizations face at the outset is not having the right datasets, said Magnuson. But an even bigger problem is data quality and integrity. “AI models are very unforgiving. If robustness and quality of data is the suspect, you will need to invest in refining that data so that it can be used reliably.”
When it comes to AI, the measure of data quality is not one, but many. “There’s a spectrum of data quality that includes data source, tags, metadata, and more. Different types of data quality techniques and rules apply. It’s many across that entire spectrum,” says Bearman.
Properly tagging, formatting, and structuring the data make it easy to consume for the models. To further enrich it, data warehousing principles can be implemented, advises Bearman.
There are tools available for extracting, processing, and preparing data for LLMs that guarantee the highest level of integrity and quality. These tools optimize the data, making it accurate, consistent and complete with continual refinement.
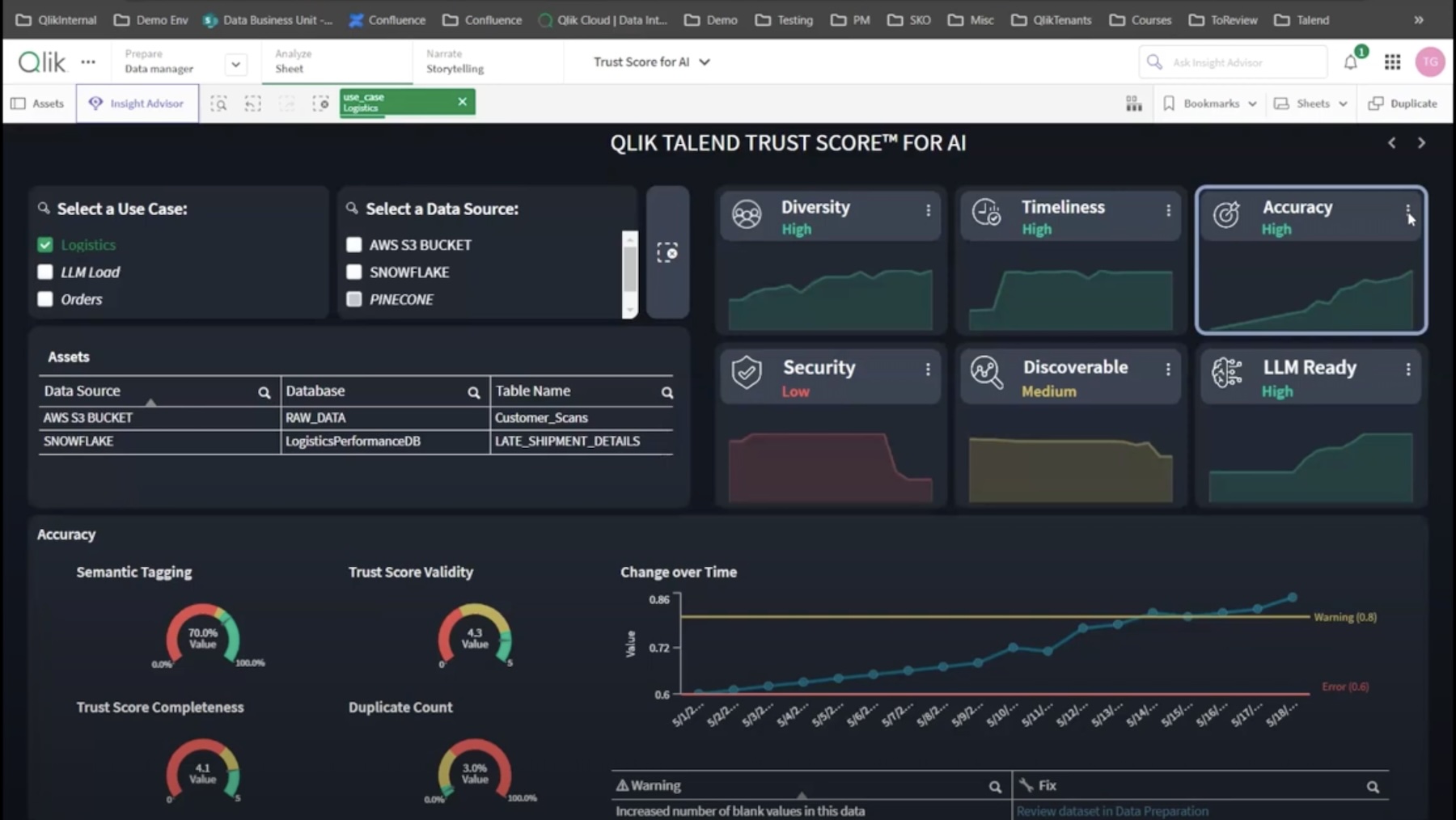
“The trust score is all about knowing where the data came from, who’s accessing it, and so on,” Bearman added.
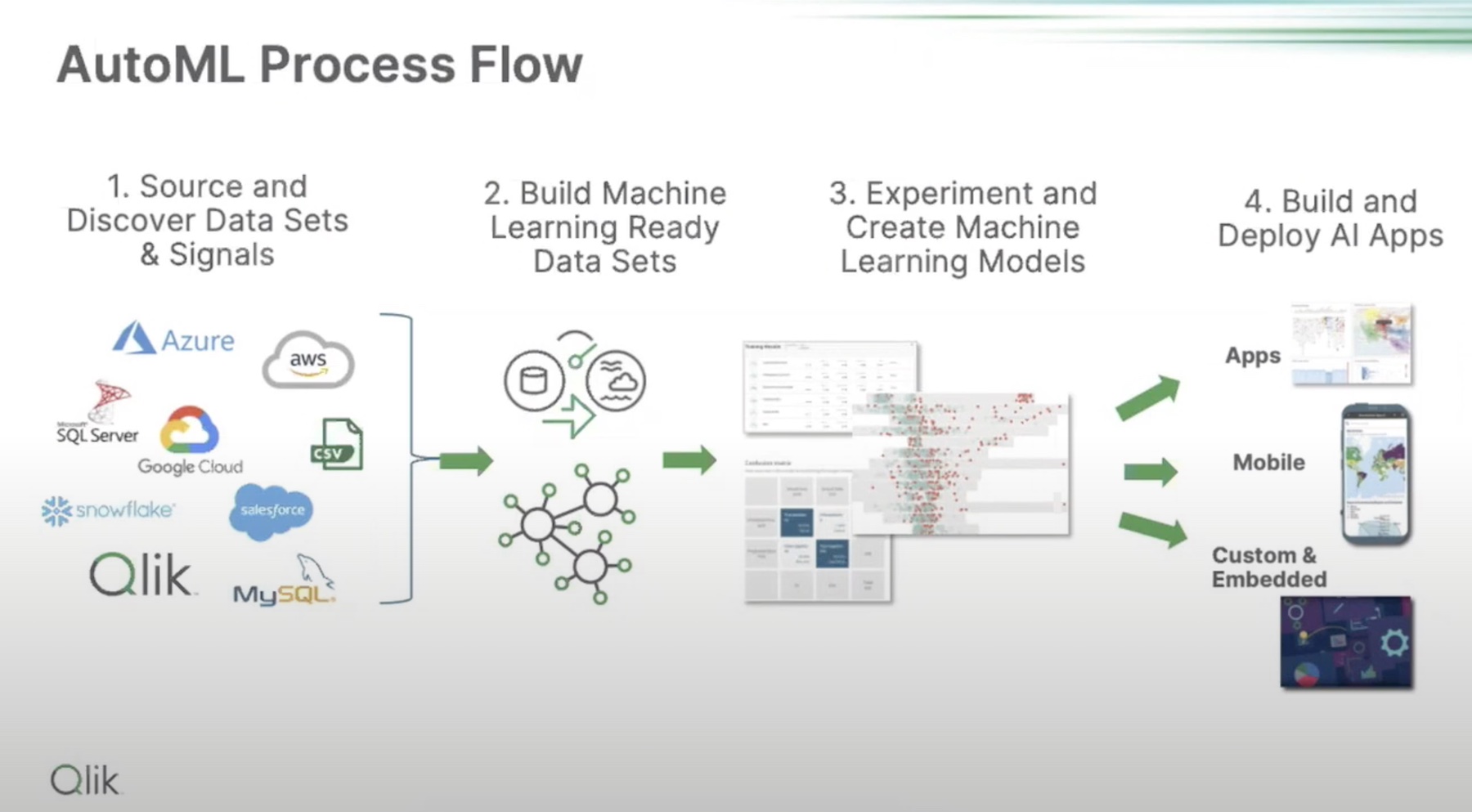
Qlik offers a suite of tools for mapping data lineage and data profiling that can strengthen the data foundation and make GenAI both trusted and trustworthy. Qlik optimizes data in three ways – it makes datasets machine learning ready, enhances their quality, and augments the models with domain specific data.
The Final Piece of the Puzzle
The key to broadening the models’ scope of response is volume and variety. “It is really important to understand that AI excels when there is a variety of inputs. The more variety, the better the veracity. Essentially AI can detect patterns in data that a human cannot. Across a variety of different inputs, it can detect those patterns,” highlights Magnuson.
But pushed too far, a data overload can hurt the models’ accuracy. For example, in case of writing, the models may know the dictionary definitions of words, and can put them together in a variety of ways, but they don’t know how the words relate to each other. Much of that comes at the advanced stages with iterations of training and learning. Dumping too much information too early can put the models in a constant state of confusion.
One needs to mindfully curate the data before plugging it in. “Data needs to be germane to the use case or the intended outcome. There’s an element of curation to ensure that the right data with the right level of quality and integrity is presented. Otherwise, you will have these instances where the AI can’t detect the right pattern to get the right information,” cautions Magnuson.
The kind of data that is used makes the ultimate difference. Before AI, the most sophisticated hedge funds invested in surveys to gather data on buyers’ behavior out from the field. That information is gold for sales strategies.
“Hopefully, people will become astute enough to realize that the AI they use is great, but the data that’s underlined is actually the real medium that has value,” says Magnuson.
Within enterprises, traceability of data sources helps build trust in the tools. “Users are not going to adopt a technology unless they know they can trust it,” says Bearman. With structured data, users have a way to trace back the source and factcheck information.
Wrapping Up
As LLMs get bigger and their capabilities grow, only a mix of structured and unstructured data can satisfy their appetite. But enterprises must set up guardrails from the outset so that potential errors and inaccuracies can be kept in check. This requires a set of tooling that ensures that data is continually refined, and enterprise datasets are organically integrated from time to time. Solutions’ like Qlik’s help train LLMs better by profiling data and mapping out its lineage, pointing to missing pieces, and essentially matching inputs to outcomes to ensure the most plausible and natural response.
Follow the conversation in this episode of the Utilizing AI podcast. Also check out Qlik.com/staige for more information on their technologies, and qlik.com to get a chance to work with the team.
Podcast Information:
- Stephen Foskett is the Publisher of Gestalt IT and Organizer of Tech Field Day, now part of The Futurum Group. Find Stephen’s writing at Gestalt IT and connect with him on LinkedIn or on X/Twitter.
- Frederic Van Haren is the CTO and Founder at HighFens Inc., Consultancy & Services. Connect with Frederic on LinkedIn or on X/Twitter and check out the Highfens website.
- Nick Magnuson is the Head of AI at Qlik. You can connect with Nick on LinkedIn and learn more about Qlik’s AI efforts on Staige on their website.
- Clive Bearman is the Senior Director of Product Marketing at Qlik. You can connect with Clive on LinkedIn or on X/Twitter and learn more about Qlik’s AI efforts on Staige on their website.
Thank you for listening to Utilizing AI, part of the Utilizing Tech podcast series. If you enjoyed this discussion, please subscribe in your favorite podcast application and consider leaving us a rating and a nice review on Apple Podcasts or Spotify. This podcast was brought to you by Gestalt IT, now part of The Futurum Group. For show notes and more episodes, head to our dedicated Utilizing Tech Website or find us on X/Twitter and Mastodon at Utilizing Tech.