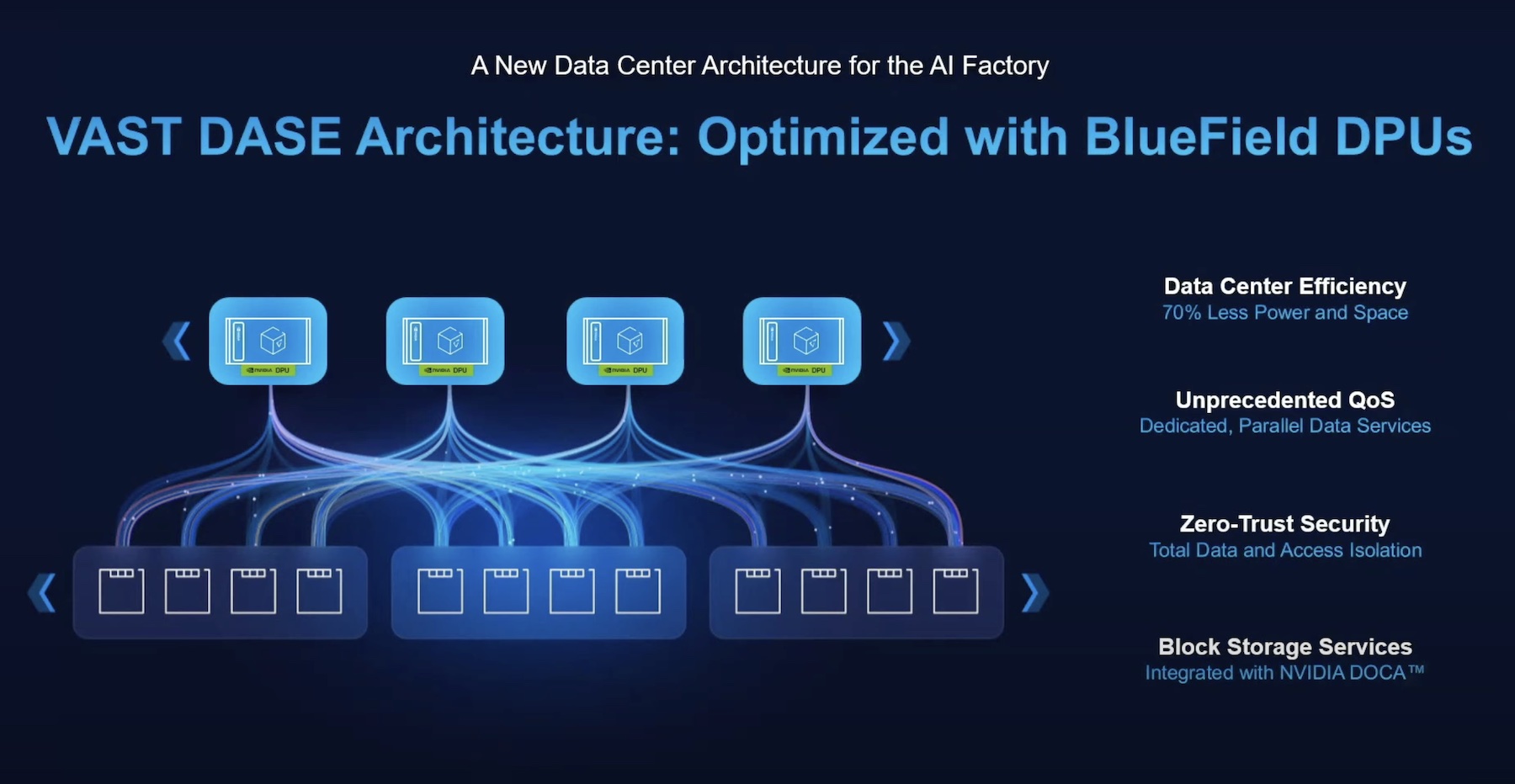
We are at a turning point, as AI has matured from theoretical experimentation to practical application. In this episode of Utilizing Tech, Neeloy Bhattacharyya joins Allyson Klein and Stephen Foskett to discuss how VAST Data’s customers and partners are making practical use of AI. Data is the key to successful AI-powered applications, and VAST Data supports both unstructured and structured data sets. Neeloy emphasizes the interactive nature of AI application development and the flexibility required to support this. He also discusses the need for structured data to support LLMs and the challenges of keeping these up to date and synchronized. One of the biggest issues in deploying AI applications is the complexity inherent in these systems. That’s why it’s heartening to see companies working together to created integrations and standardized platforms to make AI easier to deploy. Collaboration is the key to making AI practical.
Apple Podcasts | Spotify | Overcast | Audio | UtilizingTech.com
Tackling AI Data, with VAST Data
The things AI models are doing are getting exponentially complex. Crunching through troves of raw data and turning out mind-boggling discoveries, the models are doing futuristic work as it were. But now they are moving towards deciphering even subtler nuances in the data.
The differentiating factor is not the model, says Neeloy Bhattacharyya, Director of AI/HPC Solutions Engineering at VAST Data. It is the data itself.
“A lot of AI starts with data. The differentiating factor is not the model, or how you were able to optimize its training time. It really comes down to the data you fed it and what it learned from it.”
This episode of Utilizing AI Podcast shines the spotlight on data, the lifeblood of artificial intelligence. Co-hosts, Stephen Foskett and Allyson Klein, talk to Bhattacharyya about AI workloads and their different characteristics, and the new VAST Data Platform that help enterprises sidestep the data bottleneck, and fully embrace AI.
Input Equals Output in AI
Quality data can train AI models to eventually do the work of experts. But it’s not just the lineage of that data that makes or breaks them. The way data is handled behind the scenes also has a big impact on the intended outcome.
AI models go through a series of steps, that combined, make the AI pipeline. Each workload in this pipeline has its own set of characteristics and requirements. It begins with data preparation. Data is scraped from business databases, publicly available sources, and third-party repositories, and brought into one place.
This data needs to be refined and treated before it goes into the model. The process is not formulaic, says Bhattacharyya. It entails experimenting and free-styling until a proven method is found.
“When it comes to multimodal data – words, sounds, speech, and video – there are millions of ways to prepare it, and the only way you figure out the right way is to experiment – use it to train models, in inference, and see the outputs that you get.”
The models train on this pre-treated corpus of data, learning to identify objects and patterns. Owing to different data provenance standards, restrictions and regulations, enterprises in different parts of the worlds do training differently, but it normally starts with a foundational model.
“You could start with a baseline that’s learned some basics, and then you can fine-tune on top of that,” he says.
The model annotates and infers by analyzing new data points, a process commonly known as AI inference. Inference is a complex problem- it’s not just answering questions, or generating texts. “Inference is very much multimodal – it’s manipulating a video, creating speech, automating operations in business with a level of creativity to it.”
The steps may take place sequentially, but Bhattacharyya reminds that the process is not linear. Setbacks can occur at any point undoing the hard work, without the slightest warning.
“Part of the experimental nature of AI is that you can actually fine-tune a model for the worse, not necessarily for better. You could fine-tune it, change the weights or the hyperparameters, and you could find out that the model that you created was worse than your original model at doing the task that you set out to do.”
One of the challenges that customers face is that the data for AI training lives everywhere in the hybrid environment. “We used to exist in a world where data was all about transactions, and a system of record to store transactions. Then we moved into this analytics world where we’re aggregating data into data lakes and data warehouses and so on.”
This has many benefits, but there are trade-offs as well. “A downside of that evolution is that we’ve unfortunately picked up this behavior that says that you have to move your data into a location first, before you can start to extract value from it.”
AI use cases growing exponentially in enterprises has driven organizations into a spending spree. To tap into the value trapped in data, they are spending extravagant amounts of money on the logistics of moving data location to location.
“For AI, where it’s going to need to be trained on, and interact with the entire corpus of enterprise data, that’s just not practical,” he says.
VAST Data Platform – A One-Stop Solution for Storage and Analytics
Having all the datasets required for AI in one location can save companies a lot of expenditure. That’s why VAST Data created the Vast DataSpace. The VAST DataSpace is a data platform where data can be accessed, organized, and worked on, across hundreds of locations, while defying data gravity.
“What VAST DataSpace enables you to do is to stand up clusters essentially anywhere. It could be at a hyperscale, or a warehouse with a SaaS provider, and all of those entities can participate in a shared global namespace,” Bhattacharyya tells.
From this common layer, data scientists can work with data without having to move it anywhere.
“As your jobs grow, what the platform is able to do is able to shuffle that data around in the background.”
VAST Data recently struck an alliance with Run:ai, a company that does compute orchestration for AI workloads, to design a full-stack offer for AI at scale.
Run:ai schedules and allocates workloads dynamically to resources, enhancing GPU utilization and efficiency. “By folding in and integrating that with the VAST Data Platform, we’re now able to factor data into the equation. Not only are you able to run your workload anywhere and access whatever data you need to access, but for those scenarios where data needs to be moved, Run:ai is able to help us prefetch that data so that by the time the job starts running, the GPU and CPU utilization can be maximized.”
A component of the VAST Data Platform is the VAST DataBase, an exabyte-scale namespace with transactional and analytical capabilities foundational to AI. Residing inside the database is the VAST Catalogue, a metadata index that enables quick search and find.
“Foundationally, the Database and our ability to store tabular data form the basis of the VAST Catalogue. The VAST Catalog is critical from a security and audit standpoint.”
Tabular data consisting of rows and columns of information such as, who’s accessing the data, time of access, type of data being used, are stored in this tabular database. With its capacity to hold the metadata sprawl, the VAST DataBase is a great spot to store inference data that comes with thousands of attributes, for legal, compliance and audit.
The data does not need to be continually aggregated for processing. “With the VAST DataBase, each one of the instances can write to their local instance of the VAST Data Platform, and then just through the nature of our product and the integration between the global namespace and the database, we can now query that data in a unified fashion without once again having to pre-shuffle the data around.”
In another news, the Vast Data Platform, now has an Apache Spark integration. The integration is designed to minimize data movement between platforms and compute, resulting in faster query and real-time analytics.
“Spark is able to now take a look at a complex query, or a complex set of operations, figure out which pieces are computationally intensive, and push those over to the GPU, and pass down the pieces that are data-intensive to the VAST Platform,” explains Bhattacharyya.
Head over to the VAST Data website for more collateral on the VAST Data Platform. Watch the full podcast at Utilizing AI’s website, or check out VAST Data Tech Field Day Showcase at the AI Field Day event, to get in the weeds of the technology.
Podcast Information
Stephen Foskett is the Organizer of the Tech Field Day Event Series, now part of The Futurum Group. Connect with Stephen on LinkedIn or on X/Twitter.
Allyson Klein, Global Marketing and Communications Leader and Founder of The Tech Arena. You can connect with Allyson on Twitter or LinkedIn. Find out more information on the Tech Arena website.
Neeloy Bhattacharyya is the Director of AI/HPC Solutions Engineering at VAST Data. You can connect with Neeloy on LinkedIn and find out more on VAST Data‘s website or their Tech Field Day Showcase videos.
Thank you for listening to Utilizing AI, part of the Utilizing Tech podcast series. If you enjoyed this discussion, please subscribe in your favorite podcast application and consider leaving us a rating and a nice review on Apple Podcasts or Spotify. This podcast was brought to you by Tech Field Day, now part of The Futurum Group. For show notes and more episodes, head to our dedicated Utilizing Tech Website or find us on X/Twitter and Mastodon at Utilizing Tech.
Gestalt IT and Tech Field Day are now part of The Futurum Group.