More and more companies and organizations are relying on artificial intelligence, and specifically supervised machine learning to build applications smart enough to compete in the 21st century. While this pursuit comes with several potential challenges, one of the biggest may very well be the need for relevant training data that is quickly available and free from bias. Over the past four years, a team from Stanford has created both an open-source project and a commercial platform to meet this challenge; they call it Snorkel.
AI’s Data Problem
What are we even talking about here? With the terms big data, data science, and “data is the new oil” being thrown around the way they are, it feels like data should be the least of our AI application development worries. So, what exactly is AI’s data problem?
To answer this, we first need to get on the same page about some fundamental aspects of machine learning (ML – the specific type of AI we’re discussing here). Let’s tease out the role of data, algorithms, and models in ML. You feed data into an algorithm to train a model. Once trained, your model can be used to make predictions when it encounters new test data. While this is a very simplified explanation of ML, it sets the stage to look at possible constraints.
The basic components here are data, algorithms, models, and of course the infrastructure it all runs on. It turns out that these days, infrastructure is readily available. Yes, you need to pay for it, but it’s there; both physical infrastructures you own and operate and infrastructure as a service that you can access in “the cloud.” Whether you need CPUs, GPUs, TPUs, bandwidth, or storage, it’s all just a few dollars away most of the time. Algorithms are also readily available from linear regression to k-nearest neighbors and from decision trees to deep neural networks. In fact, you can even find pre-trained models based on many of these algorithms, some of them are open-source and free to use.
That leaves the data. And for the best results it can’t be just any data. For the highest accuracy, you really must train with your own data. This data is complex. And it’s often private. Plus, for most ML applications, you need to label your data. This is called supervised learning. Essentially an expert must go through all the data and annotate (label) it in order for the algorithm to be able to train the model properly. In addition to this being a highly manual and laborious process, it is also one that can introduce bias and error.
The Snorkel Project
Snorkel was born from the premise that properly labeled training data is the true bottleneck and the primary determinate of success in an ML application. Specifically, in 2016, the Snorkel team “set out to explore the radical idea that you could bring mathematical and systems structure to the messy and often entirely manual process of training data creation and management, starting by empowering users to programmatically label, build, and manage training data.”
But what exactly is a “programmatic approach” to training data? It’s exactly what you would think it is. How many of us have gotten tired of some repetitive task and eliminated it with a cron job, a shell script, or even something a bit more complex? I’m guessing that a lot of you are raising a hand right now. That. That is a programmatic approach, and it’s exactly what the Snorkel project did for training data.
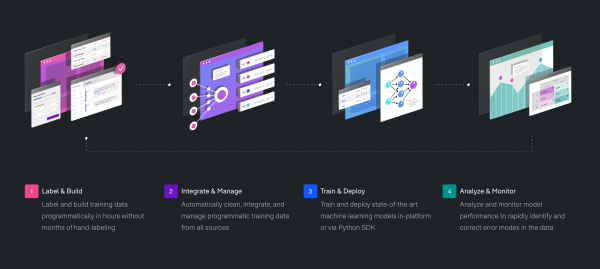
Instead of manually labeling each data point, Snorkel provides a mechanism for users to apply rules and other heuristics to standardize and automate the labeling of training data. This approach is sometimes called weak supervision and in addition to saving time, it makes the process iterative. Just like writing a script to remove some annoying task, when you label data programmatically you get to test and tune your approach – iterating to make it better over time. Just as important and exciting is the privacy implication; when you label data programmatically most training data never needs to be seen by human eyes!
Snorkel Flow
The Snorkel team didn’t stop there though. Over the past four years, they worked with many forward-thinking organizations and AI leaders. Through these interactions, they realized that “the ideas behind Snorkel change not just how you label training data, but so much of the entire lifecycle and pipeline of building, deploying, and managing ML.”
And so, in 2019 they spun the project out of Stanford to pursue the next step. That step was launched out of stealth in mid-2020 as Snorkel Flow, which they call a complete end-to-end ML platform. Snorkel Flow builds on the basic tenet of programmatic labeling of training data and expands the benefits through a polished commercial offering. It expands from the open-source project to not just train the data, but manage the full ML pipeline, including data integration and management, model training and deployment, and the ability to close the loop with monitoring and analysis.
The Bottom Line
It’s obvious that supervised machine learning is here to stay, and that AI application development is a growing need across most, if not eventually all industries and verticals. And it seems just as obvious that manually labeling thousands and thousands of data points to create the needed training data is untenable in the long term. We need a smarter approach, a programmatic approach, and the solutions from the Snorkel AI team appear to fit the bill.



