OctoML is creating optimized code anywhere, taking the machine learning (ML) model from data scientists’ hands and putting it into a production environment, specifically tuned to have the right performance and requirements for ML.
Five years ago, OctoML started asking: can artificial intelligence and machine learning can be used to automate the process of taking machine learning models into production? The answer, it turns out, is yes.
Open Source
The thriving open source Apache TVM community, built by the OctoML founders, with over 450 global contributors, has been in production at Microsoft, Amazon, and Facebook and is supported by all major hardware vendors.
TVM is the open source unified foundation for automatic optimization and compilation for deep learning for CPUs, GPUs, and machine learning accelerators. TVM bridges the gap as a compiler, improves runtime, and has deep learning for x86, Nvidia/UDS, AMD< ARM, MIPS, RISC-V, and more. TVM reduces the model time to market, and users can build a model once and run it anywhere, cutting capital and operational machine learning costs. TVM is an emerging industry machine learning stack. Alexa ‘wake up’ uses a model optimized with TVM.
OctoML, created in mid-2019, is designed to double down on investing in the process of Apache TVM and build a series of products around it that further democratizes access to high performance and useable ML.
Why is ML so challenging?
Machine learning is very costly, extremely engineering hungry, overly cloud hungry, and acutely chip hungry. The further down the development and deployment pipeline you go, the more costly and hungry machine learning development becomes. Not only that, but the rapidly exploding machine learning ecosystem can make deployment challenging due to vendor lock-in and challenges in different coding languages. Individual ML applications can comprise various programming languages for different components; Python, R, and another language may all sit in one ML pipeline. This language hodge-podge means that error checking, testing, and build tools won’t work across languages.
ML models also lack portability and scalability; enterprises are often locked into platforms and cannot scale to application demand and performance.
Where does Octo ML and the Octomizer fit?
OctoML applies cutting edge AI to make it easier and faster to put machine learning models into production on any hardware. Powered by Apache TVM, OctoML builds on top of the open source, adding fully automated programmatic and web-UI access for immediate use, detailed benchmarking, and optimized support for a wide array of hardware targets via OctoML hardware cost models. OctoML also adds outer-loop automation for packaging against multiple hardware targets simultaneously. Plus, all OctoML users have support provided by the founders of TVM, pretty much 24×7.

The Octomizer, launching officially in 2021, is a TVM-based automated platform for ML operations. It is a further layer of automation on top of TVM that simplifies ML model deployment to point and click. Users can choose the hardware target in a few clicks and decide how that model will be deployed and uploaded. Users can then download an artifact that can deploy on a phone or a server. The Octomizer is designed to compete in performance, productivity, and portability with the hardware vendor-specific solution.
The Octomizer is likely to be much easier to use than TVM, but also, since TVM uses machine learning, it needs data. A broad set of experiments run in-house collects the data fed into TVM to make it do its magic.
Features
Octomizer features device-specific tuning for each hardware platform and leverages tuning data from similar models and similar hardware to optimize operations. It uses data benchmarking so users can check how their models stack up against other common models. Packaging includes TVM C Runtime, C API, Python API, gRPC, and docker images.
The more users use Octomizer, and the more it is certified on more hardware types, the better it gets. Octomizer pro-actively collects models and tunes them based on current and upcoming popular hardware targets in both the cloud and edge, for example, Nvidia, Intel/AMD, x86, AMD GPUs, ARM CPUs, and more.
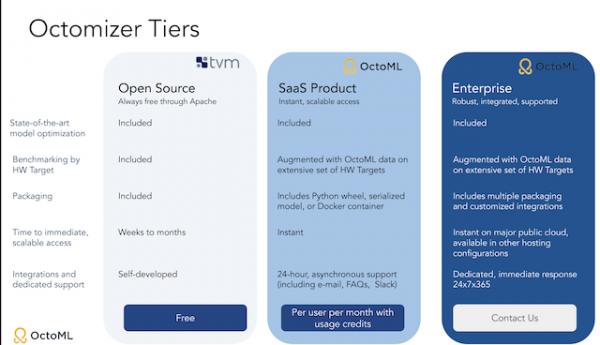
Octomizer has three tiers of use. Which of the three Octomizer tiers to choose from depends on enterprise needs. The free model is open source and features model optimization, benchmarking by hardware target, time to immediate scalable access, integrations, and dedicated support.
The second tier is a SaaS product. It includes model optimization, benchmarking by hardware target automated with OctoML data on an extensive set of hardware targets, packaging that includes Python wheel, serialized model, or Docker container, and 24-hour support across email, FAQs, Slack, and more.
The final tier is for the enterprise. It has the same model optimization as the free and SaaS models and the same benchmarking as the SaaS model. However, it improves on the packaging by including multiple packaging and customized integrations. It also has instant, scalable access on major public cloud and is available in other hosting configurations. For the enterprise model, support is always on hand 24×7, 365, giving you peace of mind.
The Octomizer is currently waitlisted,
Our thoughts
There is a surge of companies working on democratizing AI and making it more accessible to the everyday company that might not have the human and financial resources to develop AI and ML models from scratch using the old ‘everything-hungry’ development deployment models.
The use of open source, the ability to try before you buy, the broad packaging support, and the free Octimizer model make this an attractive option for enterprises exploring the AI and ML ecosystem.