Disaster Recovery (DR) is a topic that has been top of mind for most Enterprise IT professional for years. Being able to ensure data and applications are available to the business in the face of a major event such as fire, flood, extended power loss, etc. is a priority for business continuity in a 24×7 world. For the longest time this was handled by building a secondary data center or colocating in a third party data center and replicating data by means of either a hardware solution such as storage replication or a software solution.
The problem with this approach is that it can nearly double costs for IT departments that now need to buy twice as much hardware and secure additional space apart from their primary datacenter. Born out of these costs concerns is an interest in using cloud services as a DR target rather than being responsible for a secondary site and hardware. Let’s face it, Disaster Recovery doesn’t really add value to the business in a direct way and the focus of the modern enterprise IT organization is to become a partner to the business and help drive innovation. Wouldn’t it be nice if you could replicate your data and workloads to AWS or Azure and in the event of a disaster spin up what is needed in the cloud platform’s native format, thus eliminating the care and feeding of secondary infrastructure?
Cloud as a DR target?
In fact there are products that provide such functionality today, but they are by and large an incomplete solutions. When planning a DR solution, the failover process is typically the highest priority, however the capability to failback when a primary datacenter returns is of almost equal importance for most customers. This is the scenario in which many of the solutions that allow failover to public cloud fall short. The capability to failback from the public cloud provider’s native format to the customer’s workload format in their own data center is often limited, if it even exists.
Alternatively, many DR solutions providers also have a service provider program. Rather than a customer either replicating to their own secondary data center or a public cloud, many independent service providers are able to offer replication and disaster recovery services in their own multi-tenant cloud. In most cases, these clouds will have the same workload format (i.e. VMware) as the customer’s own data center, thus making failover and failback a far easier and more automated process.
Yet another DR target that has caught the interest of many an enterprise lately is VMware Cloud on AWS. Many customers who like the idea of leveraging a large public cloud for their DR strategy also love the fact that there is a service that can act as target without the need for refactoring their existing applications. VMware even has a service available for this already that will be very familiar to existing customers, but it comes with one major caveat.
In order to order leverage VMware Cloud on AWS as a DR target, customers need an active SDDC in the service to replicate to, and failover on, in the event of a disaster. This can get expensive very quickly, totaling over $140,000 per year. If a customer intends to spin up a VMware Cloud on AWS SDDC for the sole purpose of failover, they are likely to abandon the idea quickly due to cost alone. Vendors that are creating DR solutions that leverage VMware Cloud on AWS without the need to run a persistent SDDC are very enticing options for customers.
JetStream Software’s Take
One such vendor who’s Disaster Recovery product supports VMware Cloud on AWS is JetStream Software. Billing themselves as a cross cloud data management solution, JetStream has products that help customers both migrate and protect their VMware based workloads. JetStream Migrate was announced in 2018 as a product that would simplify migration from one VMware environment to another be they the customer’s own private cloud or a service provider’s multi-tenant cloud. New in 2019 though is JetStream DR.
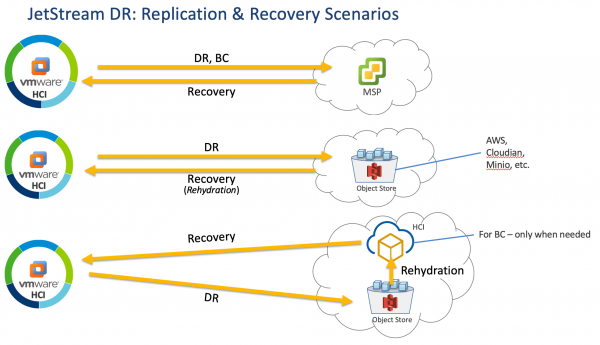
JetStream DR customers have multiple options for application protection and recovery including independent service providers, S3 compatible storage, and recovery from S3 to VMware Cloud on AWS.
Using VMware’s API for I/O filtering (VAIO), JetStream DR is able to provide near synchronous DR with a Recovery Point Objective (RPO) of seconds and a Recovery Time Objective (RTO) of minutes. This can provide the typical DR architecture that is familiar to most enterprise IT organizations by replication between VMware environments, but can also replicate to S3 compatible storage. When used alone, S3 compatible storage can be used to recover applications to the data center when it has recovered. In the case of replication to Amazon’s own S3 storage, this provides the option for the customer to recover to a VMware Cloud on AWS SDDC in the same region.
In this scenario, there is a notable amount of time added to the recovery procedure due to the need to spin up the VMware Cloud on AWS SDDC only after disaster has been declared. This process takes approximately 90 minutes and must be taken into account as part of the organization’s DR plan. As mentioned previously, failback is an important part of a DR plan as well. By leveraging VMware Cloud on AWS, JetStream customers can utilize long distance vMotion to recover applications on premises when the primary datacenter is available again. This recoverability can be further enhanced by use of VMware HCX when applicable.
Ken’s Conclusion
Finding a balance between availability and cost has been a constant struggle for IT Architects designing Disaster Recovery solutions for years. Leveraging the cloud is an attractive option that has piqued the interest of many enterprise organizations recently, particularly when it comes to independent service providers who can run the same infrastructure stack that is running on the customer’s premises. Interest in cloud DR was accelerated when VMware announced VMware Cloud on AWS, but was quickly dashed when the realization dawned on people that a persistent VMware Cloud on AWS SDDC would likely be required to leverage this offering as a DR target. Waiting until a disaster is declared to spin up an SDDC and begin incurring costs is a novel approach. While it may increase recovery time somewhat, for many enterprises this is an acceptable compromise to make in their DR strategy.