Whenever you see a new technology one of the key questions you should always ask yourself is “does this technology fix an actual problem?” It’s a good question and one that I must thank a colleague who shared it with me a few years ago. I’ve used it as a good initial test for any new technology since.
As always, Tech Field Day events present a whole range of interesting technologies. Some are evolutions from exiting vendors and some new technologies that raise that very question “do you solve a problem?”
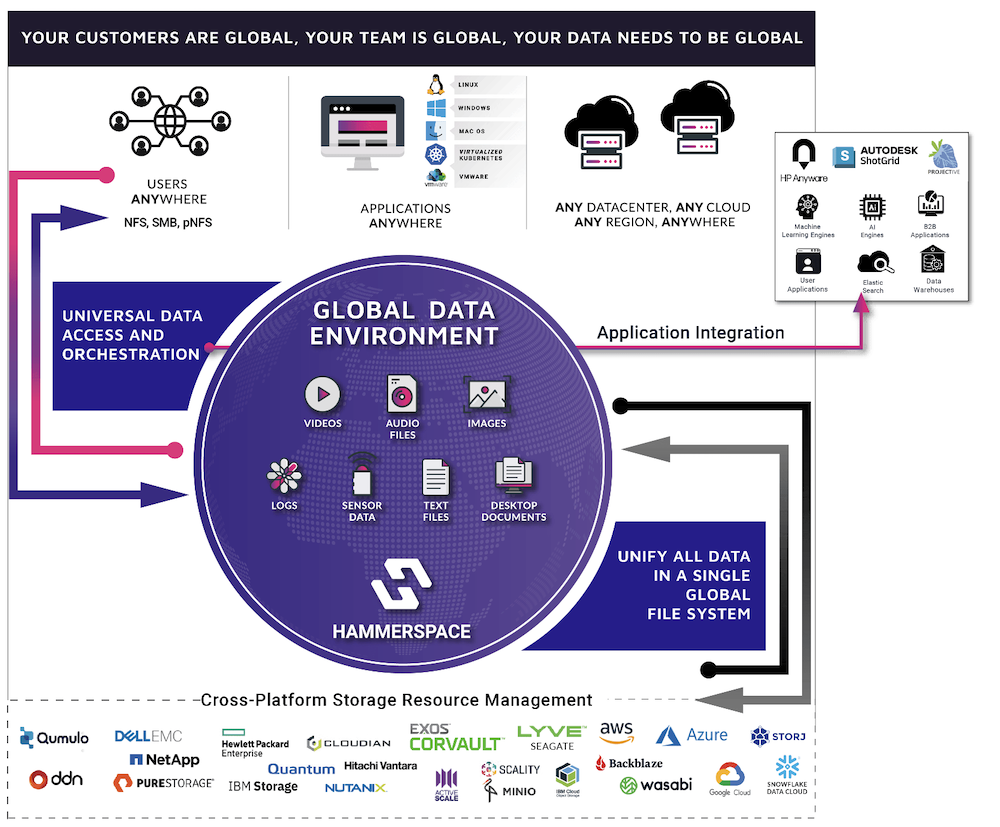
One of the continuing problems that is faced by many enterprises across the globe, almost regardless of size and business sector, is the sharing of data across multiple, geographically separated locations. The problems with moving data around, especially when the files are large, are well known. We know data has “gravity”, we need to deal with issues such as file locks, maintaining an authoritative copy of the data, and of course it is critical that we maintain the security and compliance of any data we move around these multiple locations.
The challenge of moving data around has been an issue for most of us through our IT lives and it is only going to get to be more of a problem as our datasets and reliance on our data continues to grow.
There are already numerous approaches to solving this problem: Caching, centralized storage with a “copy” housed on a remote site, native tools like Windows DFS, and of course we could always manually move files around. All are approaches for dealing with this problem, but they all come with challenges. Often issues such as global file locks, inefficiency, or the need to migrate your data to a 3rd party appliance, are all considerations and areas of compromise.

Douglas Fallstrom and David Flynn introduce Hammerspace at Tech Field Day
At Tech Field Day 17, another potential solution to this problem was presented with Douglas Fallstrom and David Flynn of Hammerspace, providing an introduction to their approach to this challenge. As we’ve established, they certainly passed the first test, what Hammerspace are looking to solve is an issue. But how does their approach differ from the number of solutions that already exist to this problem?
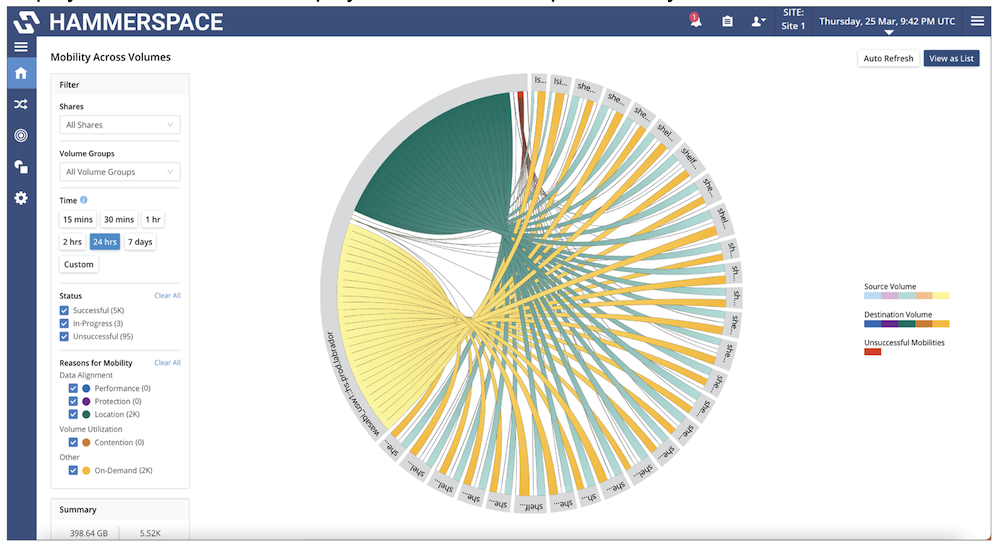
The crux of the solution is the use of metadata. It is these small fragments of information that contain the building blocks of file data, but by using these small building blocks, Hammerspace is creating and populating their geographically distributed namespace with these small information filled fragments and then using those fragments to recreate an “image” of data in any location. The important part here, is that they are not pulling full files between each “endpoint” in the namespace, just the metadata, the only time a full file is required to be moved or copied to a location is when it is needed.
There is still a level of delay when initially moving that file, but this, in my opinion, is balanced by the efficiency of moving metadata alone. There is also the point that the file data can be pre-populated by allowing Hammerspace to copy data ahead of time based on data policies such as access telemetry.
This metadata approach certainly seems to provide some key benefits:
First, in terms of deployment one of the bug-bears that comes with some solutions to this problem is the need to move your data to a new location. However, the Hammerspace namespace is created without the need to disrupt your current storage platform, with no need to move data to an alternate location or appliance, as the namespace is recreating the file view based on metadata pulled from the source storage location. This is a major plus and removes issues I’ve seen with other approaches where such a move breaks other data management tools, having a severe impact on an organization and forces them to compromise their data management capabilities to successfully share data.
 A secondary benefit is the use of metadata allows the namespace to be hugely flexible and, although not unique, the ability for Hammerspace to take data originally presented in one format and re-present it in another dependent on the endpoint protocol demands. Imagine data originally presented via SMB, to be presented to a Linux machine in a remote location via NFS, without any need for transformation, a very powerful feature.
A secondary benefit is the use of metadata allows the namespace to be hugely flexible and, although not unique, the ability for Hammerspace to take data originally presented in one format and re-present it in another dependent on the endpoint protocol demands. Imagine data originally presented via SMB, to be presented to a Linux machine in a remote location via NFS, without any need for transformation, a very powerful feature.
Of course as with any kind of solution there are always shortcomings and compromises to be made. Currently there are some minor areas of complexity ,dependent on how you want to deploy and use Hammerspace. These include issues around geo-concurrent bi-directional writes of data to original locations (last writer wins), as well as some potential challenges around handling file locking (conflict resolution with file versioning approach vs. file locking). But it seems these can be overcome by ensuring you understand the complexities of the solution and build the handling of such issues into your design choice.
There is also the real-world implementation. I’d like to see how the solution in reality handles the performance of moving large files. Replicating metadata is one thing, however the real file needs to appear in a location eventually.
That said, Hammerspace are certainly looking to address a real IT problem and one that is not going away any time soon. Are they the answer to all sharing files over distance? Not for everyone. There are already a selection of solutions dealing with this problem. However they do have an interesting approach to the problem and certainly worthy of further investigation.