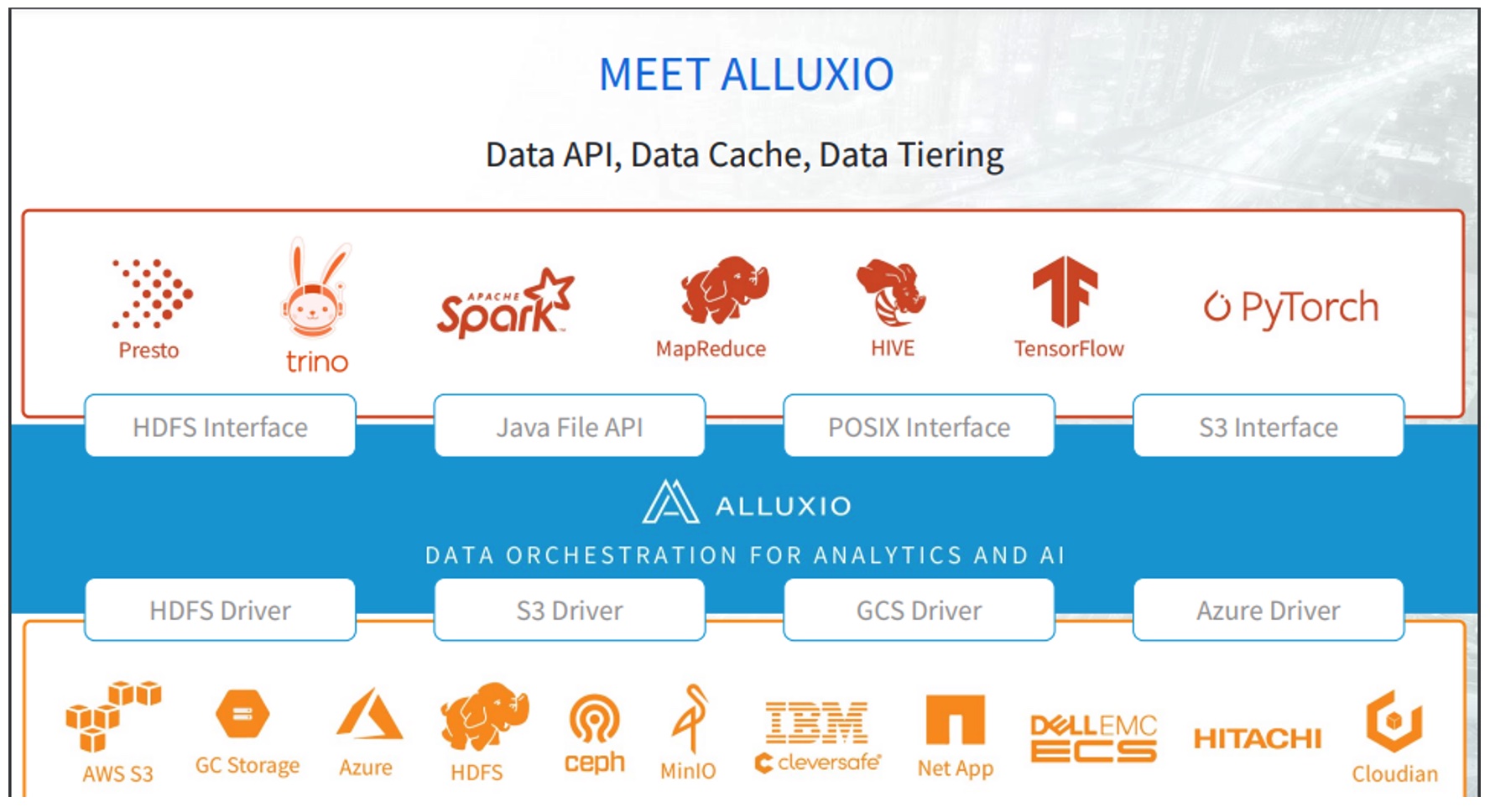
In the decentralized and disparate world of hybrid multi-cloud, data orchestration can often be a challenge, especially when it comes to demanding computes like Machine Learning and Deep Learning. Making data management and orchestration for analytics and AI across platforms simpler and more seamless, Alluxio adds some new interesting capabilities to the Alluxio Data Orchestration Platform. Alluxio Version 2.7 came out in November last year and is in use across industries.
Just recently, we had the opportunity to talk with Jan Liband, Head of Marketing and Adit Madan, Senior Product Manager of Alluxio about their new enhanced Alluxio 2.7 and how it serves to iron out the complexities involved with orchestrating data for AI/ML and big data workloads.
Difficulties with Hybrid Multi-Cloud Management
Cloud services often do not fit together like pieces of a puzzle and companies living in a hybrid multi-cloud environment know this. Every day they meet with a fresh set of challenges in the form of performance inconsistences, accessibility issues, computational limitations and sundry on top of the overarching problem of identifying the right data to train the ML models.
Alluxio: From Dorm Room to the IT Space
Alluxio was born in 2014 in the UC Berkley AMPLab where it’s founder and now CEO Haoyuan Li was a Ph.D candidate. Early on it was project Tachyon which was a virtual distributed file system. A year later in 2015, the company was commercialized and rebranded as Alluxio. Its Open-Source platform was established the same year. Today it’s a freemium business with a free to all open source version and an enterprise edition.
Last year was momentous for Alluxio with several new announcements made on the operational side. In 2021, Alluxio announced a new funding of $50 million from a leading investment firm together with other existing investors like a16z and Volcanics Ventures. Also, the company opened a new office in Beijing, China as a way of expanding its operations in Asia-Pacific.
Late in 2021, the company packed new features into its data orchestration software and officially launched the Version 2.7.
Alluxio Version 2.7, a Significant Development towards Efficient Data Management and Orchestration
How Alluxio aims to mitigate the pain points associated with the lift and shift and orchestration of data and data-driven apps in big data analytics, ML and AI across hybrid and multi-cloud environments is interesting.
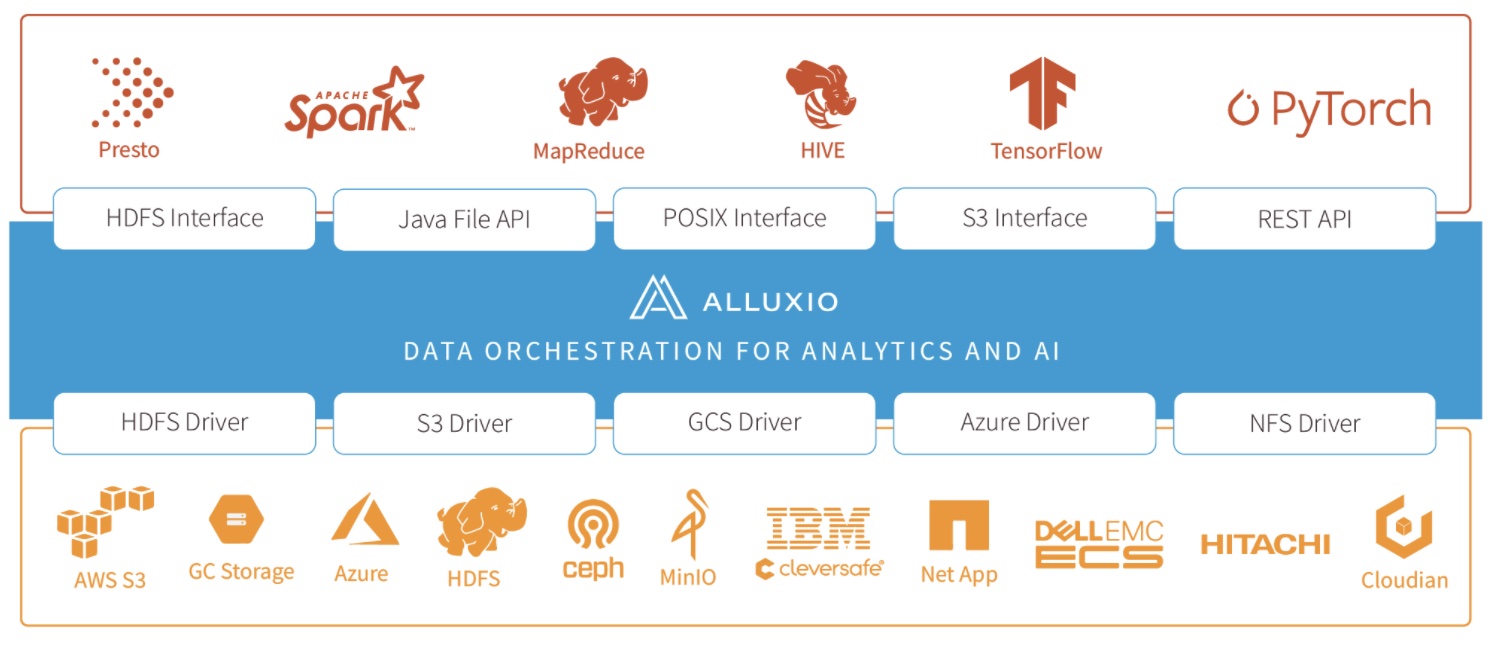
About 6 years old now, the product Alluxio is designed as an in-between layer between compute frameworks and cloud storage platforms. A deployed software, it is used both in bare-metal and containerized Kubernetes environments on multi-cloud and on-premises. Residing close to compute frameworks like Presto and Spark, it is a ubiquitous data access interface that unifies heterogenous storage systems. Through Alluxio, analytics and AI can be performed without needing to move data between environments. While sitting on top of one cluster it can enable access to data in different clusters.
Powered with new capabilities, Alluxio 2.7 increases the input/output efficiency for ML trainings to 5 times making trainings low-cost. As a data access layer for large scale analytics, the new version can be deployed between private data centers and public cloud so that you can exploit the resources on the cloud while keeping data local.
The Version 2.7 is designed to include apps in Deep Learning and Machine Learning spaces. With it, loading of data in the clusters and training of the ML models happen in tandem. In the way of enhancing its data management capabilities, Alluxio includes shadow caching in the CPU with the new version which enables dynamic workload processing on Presto-based BI/Analytics clusters.
Alluxio Version 2.7 is more Kuberentes native than the original Alluxio platform. To make that happen, Alluxio embraced two K8s principles, namely Container Storage Interface and the Kubernetes operator. With the help of the former, API access is made easier without the use of CSI drivers. After being worked on for some time, the enterprise support for it has been released recently. Simultaneously, the operator provides on-demand downscaling depending on what data’s not being accessed.
In Conclusion
Moving AI/ML workloads across platforms entails complexities and challenges that frankly organizations can do without. With Alluxio virtualizing the process, users have one less thing to worry about and when that comes with the extra benefit of agile movement of applications, Alluxio becomes an essential strategy to cope with the challenges that hybrid multi-cloud presents. A platform like it that has uses through multiple points of the data pipeline is an excellent addition to any infrastructure.
Thanks again to Adit Madan and Jan Liband for speaking with us and Beth Winkowski for setting up the meeting. For more exclusive coverages like this one, keeping reading here at gestaltit.com.