Modern applications are hungry for bandwidth. Almost all issues in the data center can be solved by adding capacity in the network to allow packets to be delivered quickly. That’s true for almost every traditional application that we’ve developed over the last decade.
However, new applications require more than just ample bandwidth. All the gigabits per second in the world won’t matter if the data latency is too high. Workloads like artificial intelligence (AI), machine learning (ML), and high performance computing (HPC) need fast performance but also need consistent data access in real time to be able to feed the engines that are doing the analysis. Disruption in the delivery of that data can cause workloads to take longer to execute and job schedules to back up at the point of processing. When you consider how expensive these specialized systems are you quickly realize how much money you can waste by having systems sitting idle due to a lack of low latency performance.
Another key factor in these workloads is that the data path for packets is server-to-server instead of network-to-network. The traditional three-tier architecture that we were all taught in our entry level networking classes may encompass the majority of traffic bound for the cloud but AI and ML workloads talk to other servers almost exclusively. This East-West traffic flow means that our optimizations for getting packets out of the network quickly don’t work well. Even more modern architectures like leaf/spine create points of failure and scalability limitations.
Rocksteady with Rockport
Rockport Networks is looking to change all this with a different method of interconnection. I received a briefing from their CTO, Matthew Williams, which went into detail about how their building a different kind of network for the reality of latency-sensitive workloads like AI and ML.
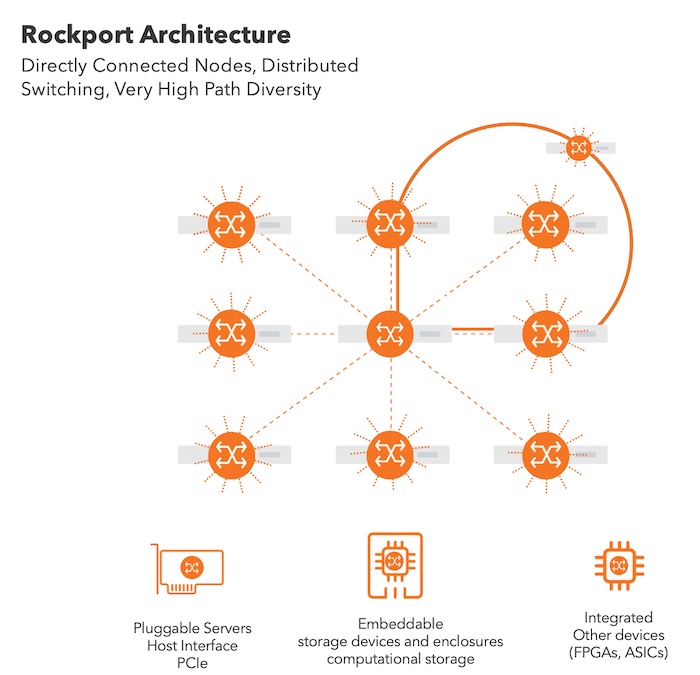
The first big shift is that there are no switches in the network. That’s likely to create a record scratching kind of moment for the traditional network engineer. How can you connect systems together without some kind of device in the middle that tells everything where to go? How will you learn pathways without intelligence to direct those packets and frames?
Rockport can work without switches because they don’t need them. Instead, they connect the servers directly to each other. The host uses a 300Gbps fabric network interface card (NIC) with some extra pieces compared to the Ethernet card in your average PC or server. There’s an FPGA on-board that runs the Rockport Network Operating System, called rNOS.
The Rockport NIC looks just like an Ethernet interface to the host OS. When packets are sent out of the server the NIC uses ARP to find the MAC address of the destination. Sounds pretty standard compared to Ethernet. However, rNOS does something different. Rather than use large frame sizes like some vendors looking to reduce latency, Rockport actually fragments the packets into smaller segments for faster transport. These fragmented packets, called FLITs, are 160 bytes or smaller. They fly over the wire to get to their destination with a minimum of effort. rNOS appends a header to the FLIT that sends it to the right destination, which is then stripped away as the FLITs are reassembled into a larger packet.
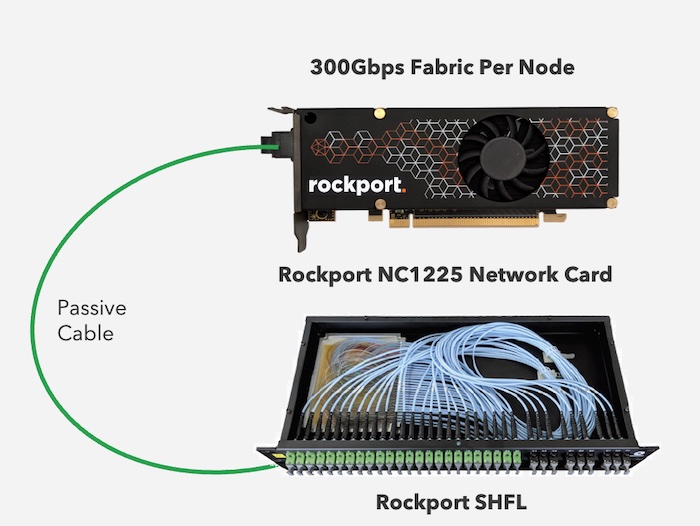
Each Rockport NIC has twelve 25Gbps connections. Each NIC is connected to the other NICs in a partial mesh. These interconnections happen because of another device that Rockport uses as an aggregator. This is the SHFL, pronounced “shuffle”. It’s a passive optical aggregation device that is absolutely not an optical switch. Instead, it takes the optical connections from the NICs and connects them together with an MPD-24 fiber optic cable. There are also spare connections on the SHFL to allow other SHFLs to be connected to increase the number of nodes connected to each other in this partial mesh. Rockport says they can connect up to 1,500 nodes together with the use of SHFLs. There is also a gateway that serves as a bridge between the Rockport switchless network and a more traditional switched Ethernet network, such as one that would serve as an exit point for traffic bound for another server farm or the cloud.
Bringing It All Together
If all of this looks or sounds familiar you’re on the same track I was on. Matthew told me this is very similar to the way that a fibre channel storage network operates, only with server-to-server network data instead of storage data being sent around. By using an SPF algorithm to find the best path to reach another node the system has direct addressing information about where things need to be sent. The system also ensures low latency by checking to make sure the path is ready before sending. This kind of assurance means FLITs don’t get lost in transit and require retransmissions. The same setup makes a lot of sense for data that stays local within the server farm and needs speed and low latency over reachability outside of the cluster. It’s a new way to look at an old problem facing new applications.
If you’d like to learn more about Rockport Networks and their switchless architecture, make sure you check out their website at https://rockportnetworks.com.