High Performance Computing (HPC) workloads are becoming increasingly popular among many organizations. Across the life sciences sector, HPC environments are commonplace, and have their own unique requirements and challenges.
HPC Requires Parallel File Systems
HPC systems require high-performance storage capable of delivering high IOPS, high throughput and low latency under sustained conditions.
But compared to more traditional workloads, HPC introduces the concept of parallelism, where computational tasks are sliced and massively distributed within an HPC cluster, which can comprise of hundreds or thousands of compute nodes. All the nodes participating in a cluster are bound together with a fast, dedicated network interconnect (at least 100 GbE), and computational operations can be performed either on CPUs or GPUs.
HPC clusters require a robust storage subsystem capable of sustaining a massive amount of parallel I/O operations while delivering peak performance, otherwise storage becomes a bottleneck. This is where a parallel file system makes all the difference with traditional storage platforms which cannot handle this scale and level of parallel I/O.
The Data Staging Challenge
Another caveat with traditional HPC implementations is the way data flows in and out of the HPC cluster. Organizations store their primary datasets on file systems not optimized for parallel access and have a dedicated “scratch space” on the HPC cluster, a parallel file system which is used for temporary computational operations.
Production file systems and scratch space are usually from different vendors, due to the different storage requirements of both environments: HPC requires parallel access and performance, leading science teams to adopt non-standard storage, sometimes even from open-source projects which, while allowing for tuning, remain complex to install and maintain.
In these setups, data needs to be pre-staged from production file systems to scratch space, which requires a certain amount of time based on the dataset location and size. Once the data is pre-staged and processed, the resulting output needs to be moved back to production storage.
There are several inefficiencies that can very rapidly become a penalizing factor in terms of cost and agility: pre-staging times add up for each new dataset to be processed, data needs to be moved back and forth, scratch space is often limited and needs to be purged to make space for new datasets. In case of re-runs after some time, data may need to be pre-staged once again.
Solving HPC Challenges with Hammerspace
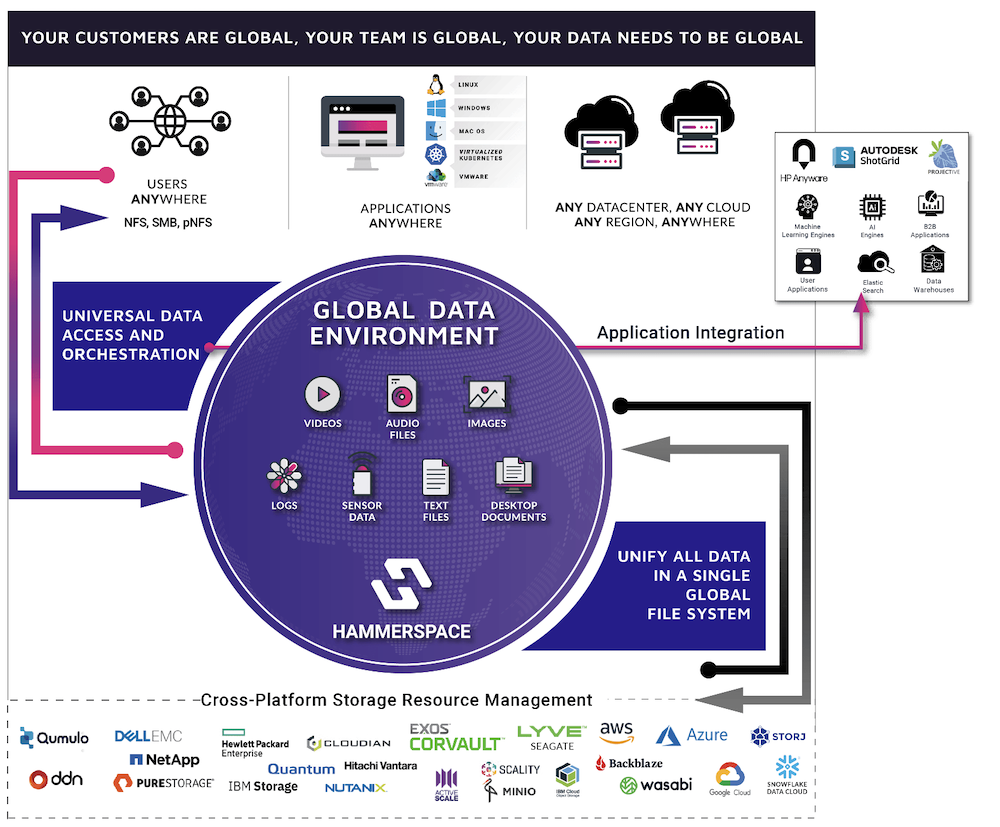
Hammerspace proposes an innovative approach that helps meet HPC storage needs: Hammerspace Global Data Environment, a software-defined global filesystem that spans across any data center, any cloud, and any region and can aggregate the existing data on any legacy storage system into a single, shared global namespace.
Organizations can deploy Hammerspace on bare metal enterprise-grade servers or on virtual machines as well as in the cloud. All those nodes create a single, transparent namespace which eliminates underlying complexity and presents a unified view of the data, regardless of where it is located, with comprehensive cross-location replication policies. Furthermore, the solution supports different media types, allowing different workloads and datasets to converge in a single Global Data Environment. This provides the flexibility of placing data on the most appropriate storage tier, without management hassles, and while ensuring the best $/GB profile.
Hammerspace addresses both parallel file system requirements and data staging challenges:
- Parallel file systems: not only does Hammerspace implement a parallel file system, but it also supports pNFS 4.2. This allows direct interconnect between a client and the storage, and most importantly, also enables GPU-based workloads to access the filesystem.
- Data staging: datasets can be cloned, and HPC jobs can be run directly against the clone, leaving the data source untouched. Furthermore, the single namespace and ability to support parallel workloads eliminates redundant data movement activities while ensuring data can be served to users, traditional applications, as well as HPC clients requiring parallel filesystem access.
The solution provides NFS and SMB access to applications and remote users, regardless of their location. It also supports containerized environments through a Kubernetes CSI plugin.
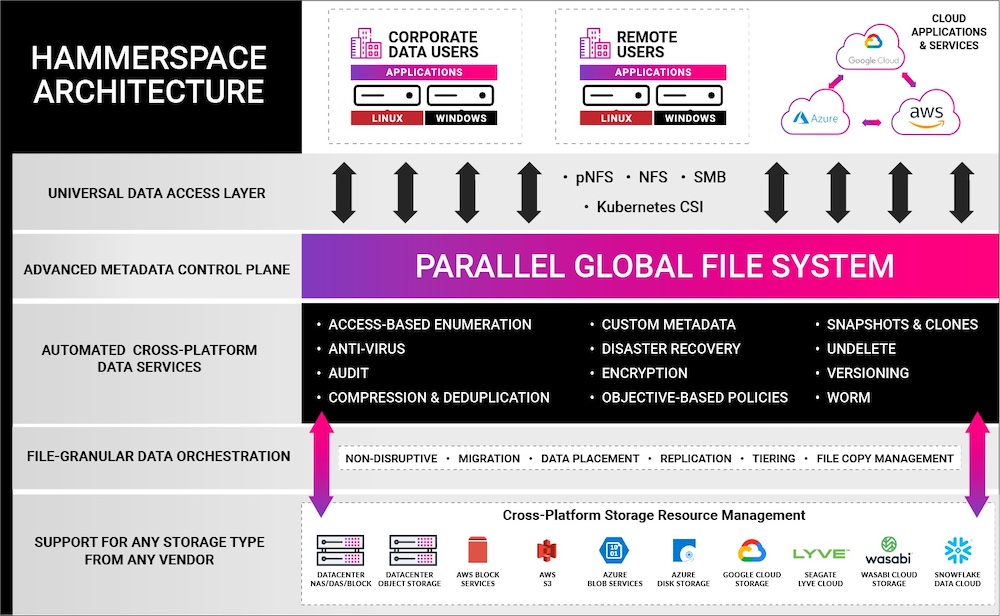
Hammerspace also delivers a rich set of data services including anti-virus protection, undelete and file versioning, snapshots & clones, compression, deduplication, tiering and immutable file shares. It also embeds multiple security features including encryption, external KMS server support, role-based access control and Active Directory support.
Conclusion
Hammerspace offers a unique perspective capable of delivering outstanding business value when supporting HPC workloads thanks to its enterprise-grade, distributed scale-out file storage solution. The solution is highly efficient and cost-effective, it can be deployed globally, on any server, any location, and any cloud, without performance compromises.
Hammerspace helps reduce the complexity, not only from an infrastructure perspective, but also from a workflow standpoint, as demonstrated earlier with HPC challenges related to data staging. In addition, organizations can make changes under the hood, without affecting what users or applications see, and thereby, breaking no dependencies.
Finally, it allows organizations to use a single global filesystem capable of addressing high-performance use cases as well as more commonplace requirements.