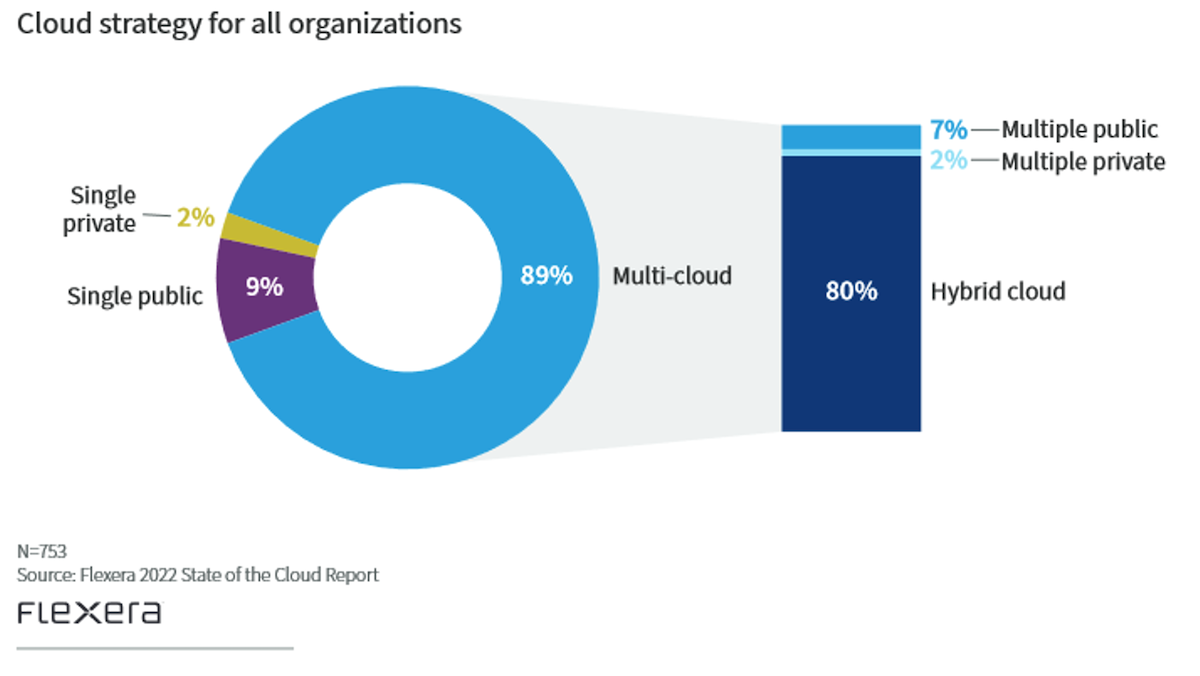
Introduction
Operating in two public cloud environments has always felt like more than double the effort. Each cloud has their own API; some cloud environments share capabilities such as S3 Storage API compatibility; and most cloud environments have unique ways of providing encapsulation for various applications or authentication and authorization. Mapping these from cloud to cloud becomes even more complicated if you are fully bought into the cloud native versions of the applications like Database as a Service (DBaaS) and are leveraging AWS RDS, for example.
Growing up with the Public Cloud
Multi-cloud would be an easier proposition if the cloud had remained strictly Infrastructure-as-a-Service (IaaS). Moving from one cloud environment to another with IaaS would be as simple as lifting and shifting your workloads to a virtual version of your physical server that was hosted in your on-premises datacenter. The truth of the matter is that the cloud has matured to offer optimized and managed versions of various applications such as DBaaS or managed caches at multiple levels such as Redis or Elastic. Compute can now be purchased on demand and even scale to zero if you can fully embrace and refactor your applications to leverage serverless methodologies.
While shifting the complexity of hosting monolithic applications on single servers to cloud native makes some things easier for developers, keeping the data safe is trickier for those who operate the platforms — especially if they are leveraging multi-cloud. Developers and operators benefit from the simplicity of packaging their applications in a common format, such as OCI Containers. When implemented correctly, the deployed containers are typically immutable and the data of the application is serialized to some other service such as a database or object storage bucket.
Here lies the root of the problem. Each cloud provider has internal mechanisms to ensure the durability and services that help backup data, but the providers don’t always make that process transparent (or even accessible) to the end-user of that service. As a best practice, you should leverage the snapshot capabilities that are provided by AWS RDS to keep seven days of backups of your production database. However, if you want to restore that data to another provider, you won’t be able to do it directly. The reality of this situation is that with the shared responsibility model, you are ultimately responsible for your data.
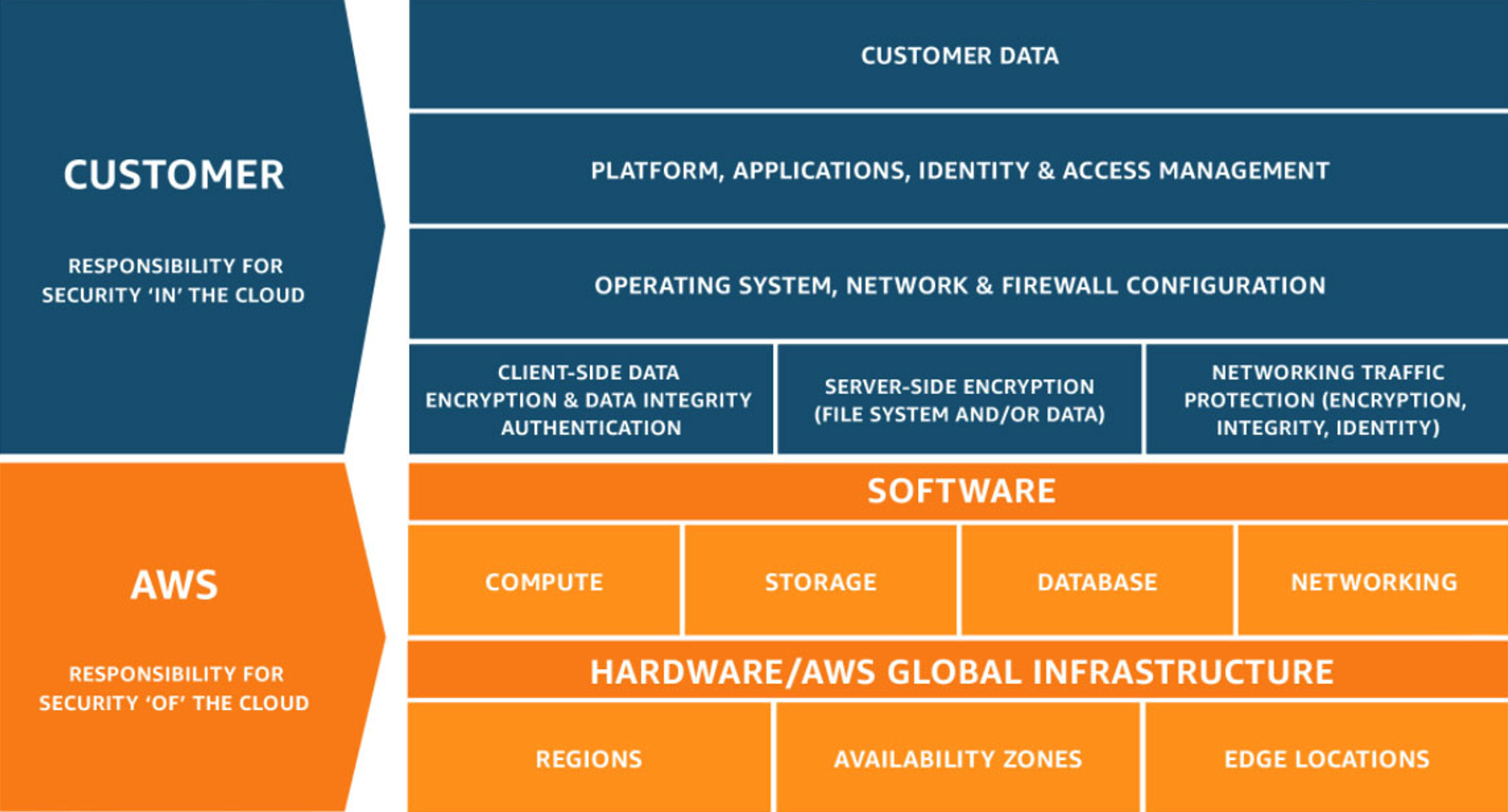
Backup Solutions Will Transform to the Cloud Native World
Let’s use the example of a production application running with an AWS RDS database. If you back up a copy of this data for disaster recovery purposes to another public cloud, you will need to orchestrate the load of one of the AWS provided snapshots into a running RDS instance. Only then can the snapshot be dumped using your database vendors tooling so it can be transferred and stored in a format that can be restored by another DBaaS offering.
While the RDS snapshots are stored in S3 behind the scenes, the direct access to these internal buckets is not available to the operators of the system. Additionally, the backups are not typically in an open format that is readily importable outside of the RDS ecosystem. The RDS service offers an API to export to S3, but this feature is not targeted at disaster recovery as it saves your data in Parquet files on S3. This feature is perfect for big data pipelines, but not so great for recovery to a running backup database.
To solve this problem, one approach is to build fully supported backup modes for each cloud. These backup services will need to speak each cloud’s APIs natively and be the mediator to efficiently move data between them. HYCU is attempting to tackle this problem with a cloud native approach. In fact, HYCU recently shared with me their vision of a cloud native backup tool called Protégé.
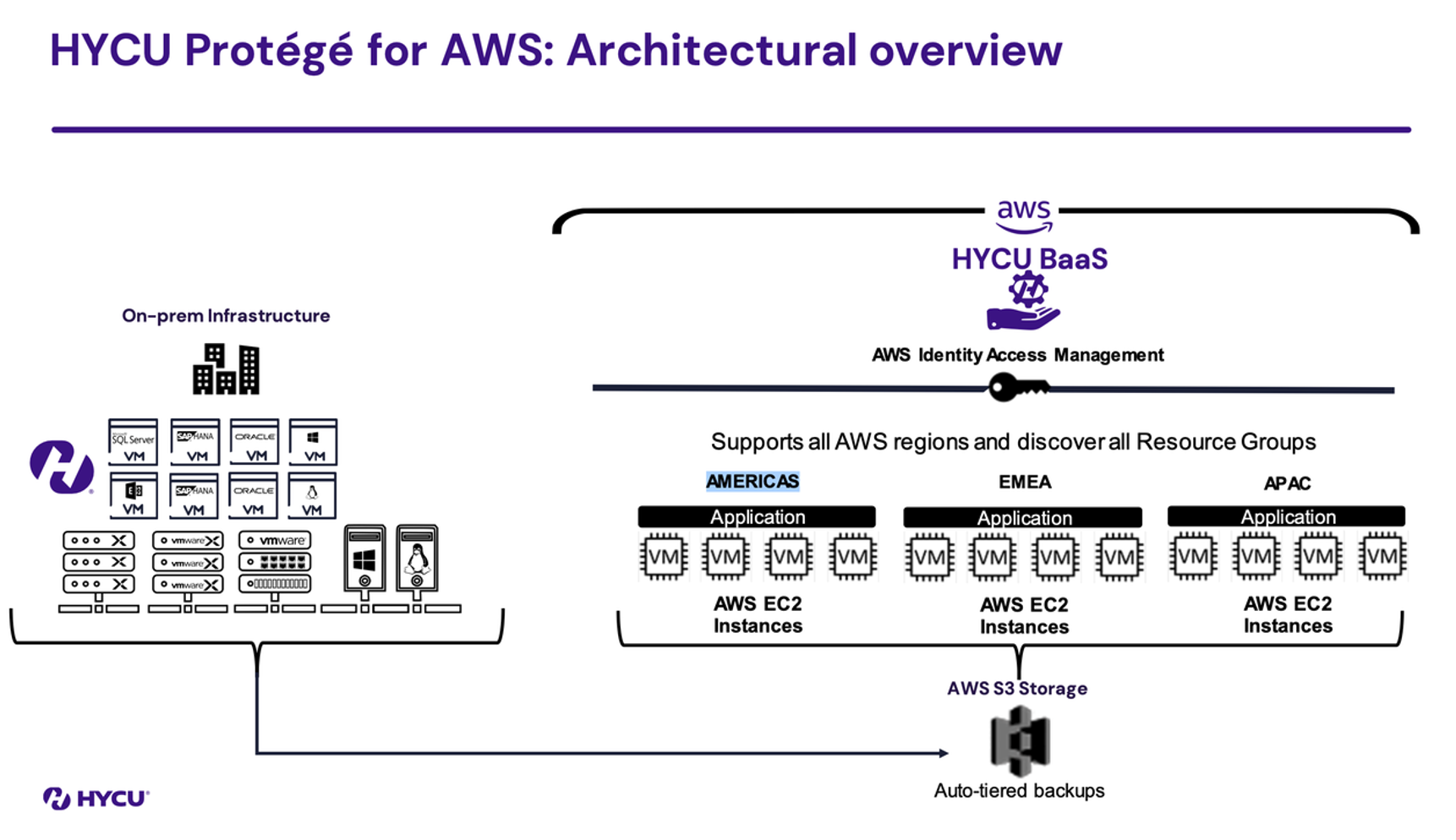
HYCU didn’t just add “cloud” to an existing offering to re-sell it back to the Enterprise. The Protégé approach leverages the same cloud native building blocks that you would leverage when building your application and to backup an application to your destination of choice. One aspect that was particularly ambitious is HYCU’s goal to be purpose-built for every cloud platform. Protégé leverages all the native APIs, while giving the backup operators a unified experience. Your data will benefit from a 100% agentless solution, as Protégé can use the same APIs your application uses to talk to the data, backup and restore it.
This also means that it has the same elasticity that we have come to expect from the public cloud. If your backup operation needs more compute to satisfy a specific SLA window, it can scale up to accommodate that. In parallel, it can take a more economical approach to the resources, if costs are a bigger consideration.
Conclusion
It still feels like the early days in the journey of fully backing up and protecting cloud native services across cloud vendors. The last piece of the puzzle will likely require cloud vendors to allow access to DBaaS snapshots in a way that doesn’t require a full restore to back that data up. This is still not possible today. In some cases, even the Protégé tooling will have to spin up cloud resources to work around these shortcomings. For a true cloud native backup, I think this will be the next stop.
To see the full presentation from HYCU, check out our Showcase page on the Tech Field Day website.