Looking back at my old Docker article from 2016 I realized that a lot has changed in the container/orchestrator space in the last 4 years. In recent conversations with folks, I have also realized that there are still some misconceptions around containers, so let’s talk!
What Are Containers?
No, not THIS kind of container…

In order to explain what a container is, we need to quickly review our history lessons.
A Brief History of IT:
Back in the bad old days (pre-virtualization), if a developer wanted to make an app, the business would need to go out and BUY A PHYSICAL SERVER (gasp!) on which you would then run that app. This server would need:
- Placement in a datacenter
- Provided power
- Provisioned on the network
- Operating system put on it
- OS Patching
- General maintenance
In short, 3+ months before the developer could even start to put his idea into motion on hardware.
Then VMware came along, and we could then provision multiple virtual machines (VMs) inside of one physical machine. This was revolutionary and drove down provisioning times from months to days (if not shorter with the right kind of automation in place). But the VM still needed:
- Network Provisioning
- OS Installation
- OS Patching
- General Maintenance
The OS layer consumes a portion of the potential resources on any one piece of hardware. These are resources that the application is not using… and when you run multiple operating systems on one box, that portion dedicated to the OS gets bigger and bigger…
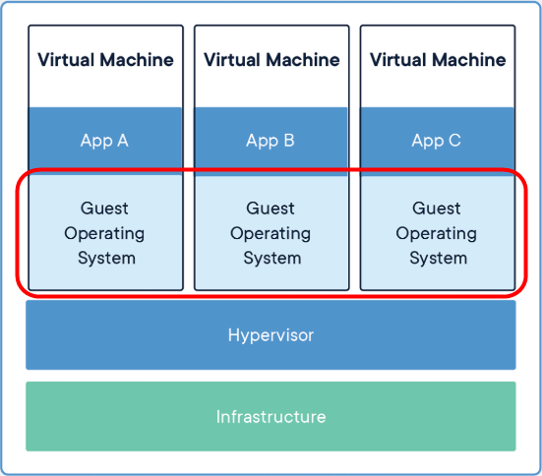
This layer is “wasted” resources the app cannot use…
Along came containers! In brief, containers are an abstraction at the application layer. It packages together code and dependencies so that separate operating systems are not needed for each app. Multiple containers can run on the same machine and share one OS kernel with other containers. There is less overhead per container than there was per VM. This allows us to not only get more performance out of each hardware platform, but we only need to patch & maintain one OS, which eases the burden on the Ops administrators:
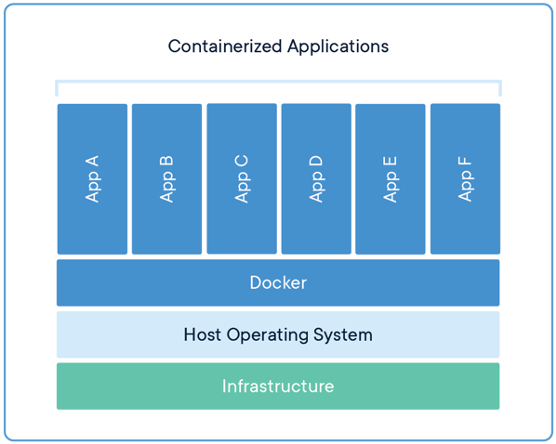
What is a Kubernetes, and Does it Hurt?
Ok, so you now have all these containers and VMs running on individual physical machines. Do you see the Achilles heel of the situation? What happens if the hardware fails?

If you have a lot of applications running on one physical server and that server falls over… you have an issue. What you need are several discrete physical systems that are connected in some way so that you can:
- Move workloads around
- Understand connectivity between those hardware platforms
- Sync and coordinate data movement
- Maintain the hardware with no downtime to the application
- Maintain the OS with no downtime to the application
Enter the orchestrator.
In VMware, we have vCenter. It serves as the central hub around which you manage your infrastructure. Your infrastructure is two or more ESXi hosts that will then hold all of your VMs.

In the container ecosystem, we have Kubernetes (sometimes shortened to K8s), which ostensibly does the same thing as vCenter. I say ostensibly because it does more than that, but the analogy is good. Kubernetes is concerned with the hardware (like vCenter), but it is more concerned with the applications and software running inside of the containers.
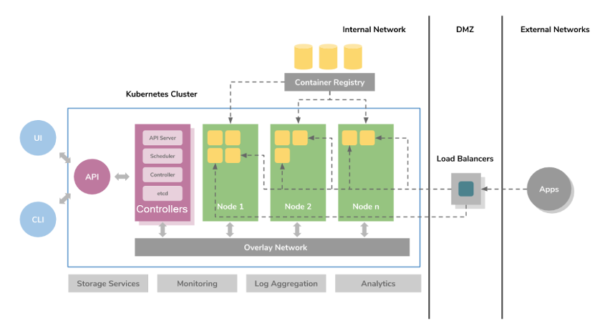
With K8s you can:
- Automate application rollouts
- Configure rolling updates to an application
- Monitor the health of your application
- Scale-up/down your app based upon triggers or needs
- Deploy anywhere (on-premises, public cloud, or hybrid)
- Declare a ‘desired state’ that K8s then tries to satisfy
- Orchestrate persistent storage across ephemeral containers
- Configure networking (and security needs) across a pod/namespace/cluster
- Self-heal an application
- And much more!!
Let’s Talk About Storage
Back before 2018, there used to be a concern around containers and orchestrators about persistent storage. The common refrain was, if your containers were ephemeral (i.e. it could be destroyed at any time), what would happen to the data on it? As such folks were reluctant to use them for workloads that required data to persist longer than the life of the said container. Enter the Persistent Volume! I’m not going to go in-depth here, but this concern has been largely mitigated with the advent of Persistent Volumes (PVs), Persistent Volume Claims (PVCs), and Storage Classes (SCs).
Here are two really good resources to learn more about the storage aspects of Kubernetes and should help allay your fears around putting a database on a container in 2020:
- Demystify Kubernetes and Cloud Native Storage with VMware from Pure Storage
- Kubernetes Volumes explained | Persistent Volume, Persistent Volume Claim & Storage Class by Techworld with Nana
If you want to start learning about Kubernetes, containers or how VMware integrates with both, here are some great links to get you started:
https://training.play-with-docker.com/
https://kubernetes.io/
https://training.play-with-kubernetes.com/
https://tanzu.vmware.com/tanzu
To learn more about Pure Storage’s solution, visit this link.
Also, be sure to check out the On-Premise IT Roundtable Podcast video below featuring:
Jon Owings, Principal Solution Architect at Pure Storage
Cormac Hogan, Director and Chief Technologist at VMware
Chris Williams, Multi-Cloud Consultant for WWT
Drew Conry-Murray, Tech Blogger and Podcaster at PacketPushers.net