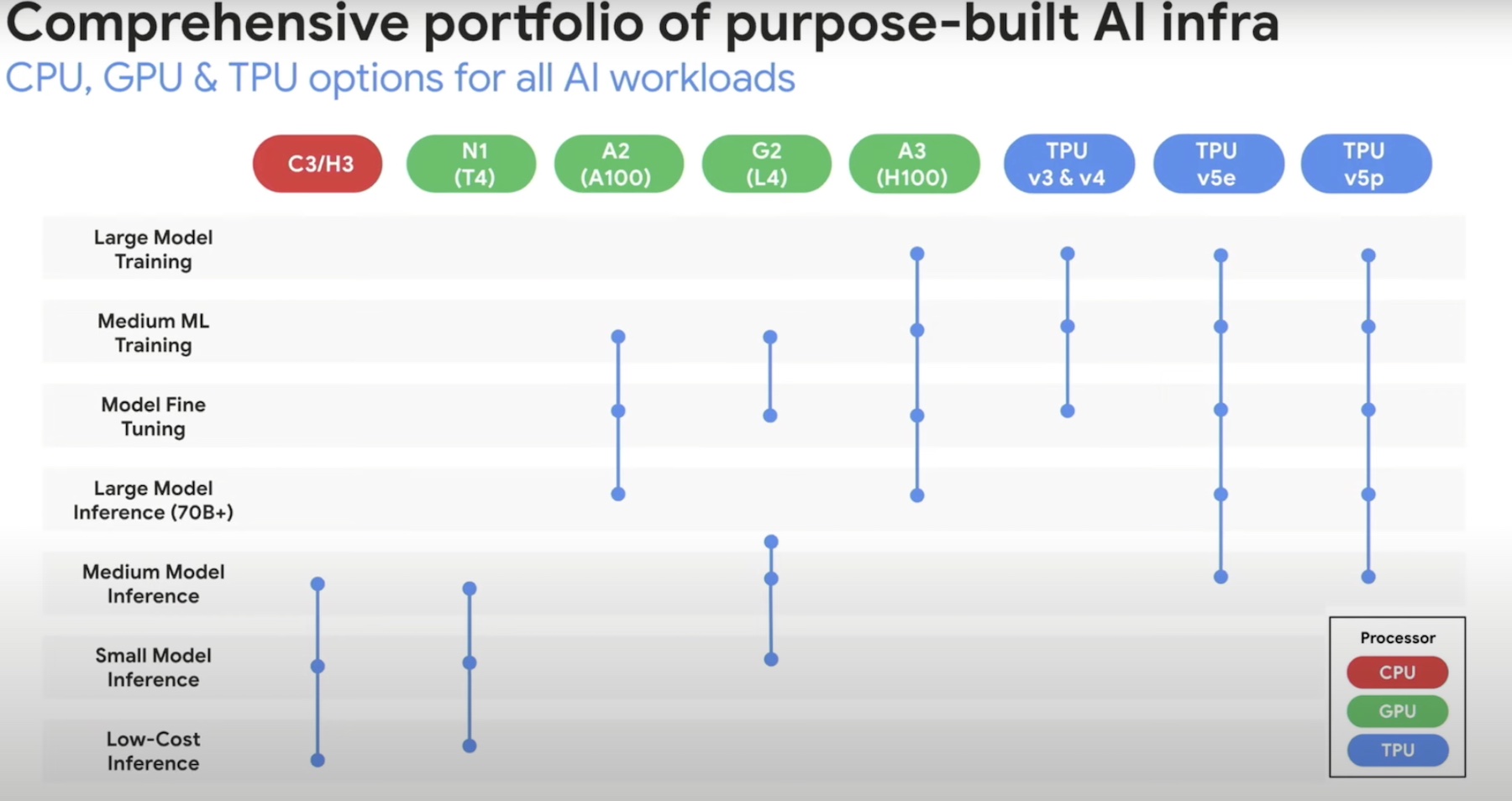
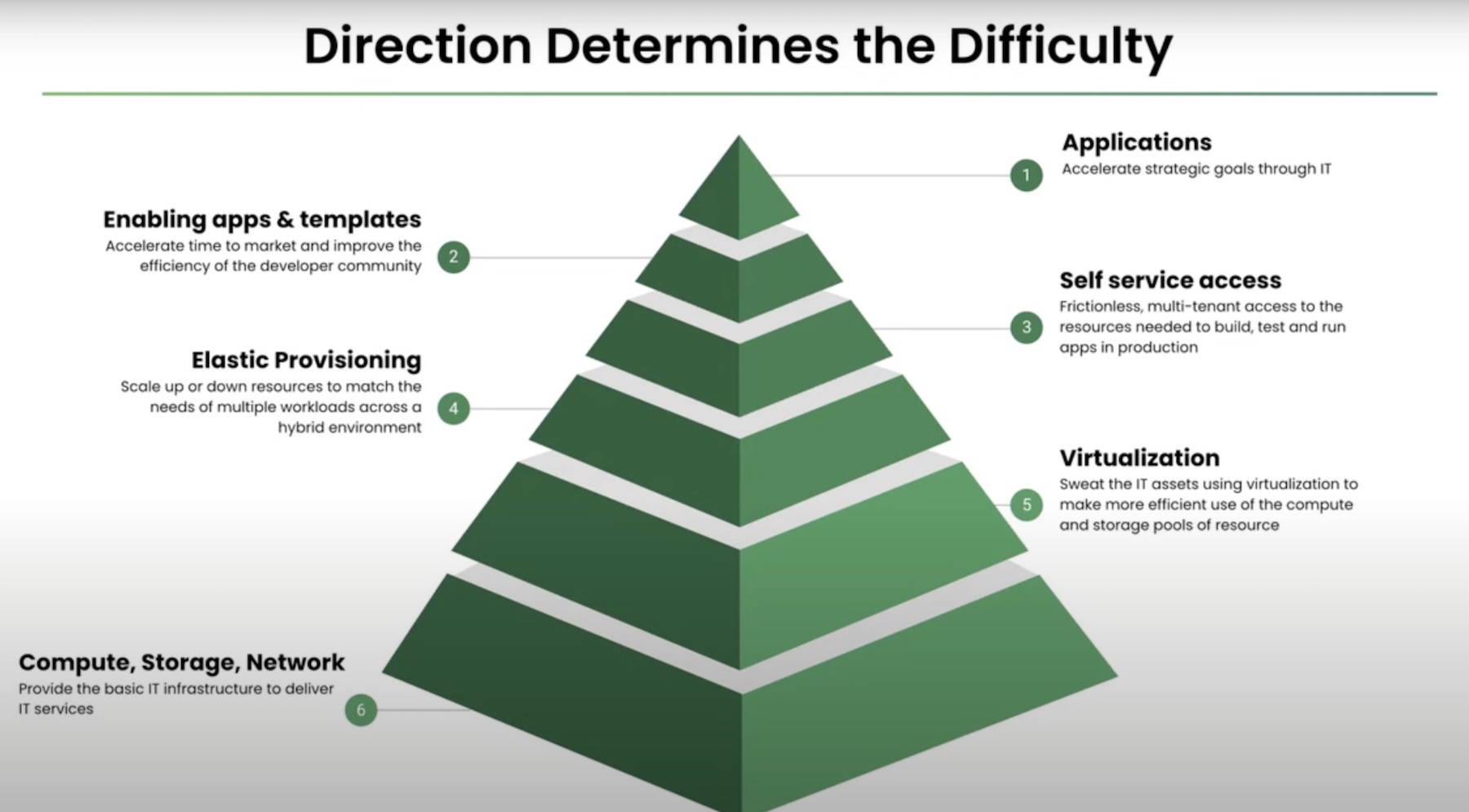
When selecting workloads to migrate to the cloud, it’s important to consider a few architectural decisions and take some common pitfalls into account, since the on-prem datacenter and public cloud services can vary widly in how they work and what kinds of services they offer.
The disconnect between the two becomes clearer when you look at application architectures, the way they’re developed and the assumptions the application makes about the underlying infrastructure. Let’s look at this in more detail.
Traditional enterprise applications
When looking at enterprise applications, the vast majority are traditional Windows-based Client/Server applications. It is sometimes hard to characterize these applications: while most are traditional Windows client/server applications, some represent themselves as web applications, others might run on Linux or Unix, etc.
To determine if an application is a traditional enterprise application, look at characteristics of the application and its architecture:
- Is it a monolithic app? Can the application be upgraded in small portions or only in a single (binary) process? Does the upgrade need a maintenance window?
- Is storage for the application based on fileshares and –services or does it rely on specific filesystems or block protocols (iSCSI, FC)? Does it use traditional SQL- or Oracle-like database structures? How does the app handle storage outages or bad performance (high latency, low bandwidth)?
- Is it tolerant to failures? Does an outage on the infrastructure level cause the application to choke, too? Does it rely on hypervisor or OS-level features for high availability?
- How does the application handle additional or diminishing load? Are there features inside the application to scale it up or down?
- How is the IT department organized around this app? It there a cautious, ITIL-style process approach to minimize risks and have stringent control over changes?
Cloud-native Apps
Public Clouds, like Google’s Cloud Platform, are geared more towards a new generation of applications: the cloud-native architecture, where applications are broken down and separated to individual services. Subsequently, public cloud services tend to be more developer-centric, focusing on application or middleware services for compute (PaaS, containers, functions), storage (object, bigtable, nosql), networking (load balancing, mesh routing, CDN, DNS and service discovery) and more.
Cloud-native apps are characterized by very specific development-centric guidelines. Heroku, a public cloud application platform now owned by Salesforce.com, has published a manifesto on type 3 application architectures, called the ’12 Factor Application’ (further reading on 12factor.net) that outlines a methodology for developers to follow when building modern web-based applications. The manifesto includes a couple of principles that I think are crucial to the definition of a Cloud-native App, and translate well into the application and middleware specific approach Google has taken with it’s Cloud Platform.
- Loosely coupled, tightly integrated services for the app
By cutting an application into its individual services and developing each service independently, dependencies are explicit isolated. This way, it’s harder to assume other services are there (or that infrastructure-level constructs are providing availability), and it becomes easier to ensure availability by adding services explicitly to the software architecture. - Standardize the integrating between backing services
Utilize very simple endpoint mechanisms (RESTful APIs) to talk to backing services (like a database, or a cache, or a load balancer). Doing so makes sure the application doesn’t fail when the backing service changes where it runs (different host, datacenter or different SaaS-provider). This makes scaling different parts of the application so much more easy, as well as migrating from on-prem to public cloud services. - Distribute the workload
With the application now broken up into micro-services, it becomes easier to create process execution code that is stateless and can be distributed across multiple instances (regardless if that’s a VM, PaaS-platform or container). Each individual application instance now only processes a small part of the application workload. - Any and all state is kept in either a database (MySQL, NoSQL), shared storage (like NFS or iSCSI) or object-based storage services (like S3).
Different application architectures go to different cloud services
With a little knowledge about application architectures under our belt, it’s becoming obvious which applications are suitable workloads to migrate to the cloud, and which are not.
For traditional enterprise apps, it really comes down to the matter of how much the application architecture can be influenced. If the conditions (budget, resourcing, skillset) are there, it might make sense to re-architect and align with the cloud-native architecture. This way, the applications can be deployed into optimized cloud services. Depending on the type of application, it’s architecture and dependencies it can be moved into public cloud services that are completely tailored for cloud-native applications and run code in App Engine, store data in the object-based Cloud Storage, use the NoSQL Cloud Datastore service and use independent networking services for load balancing and CDN-functionality.
Now, the previous paints a very optimistic picture, and only works if the applications can get on the cloud-native train. In some cases, development teams or 3rd party vendors don’t have the prerequisites in check, and re-architecting to cloud-native is not an option. For these types of applications, there’s always the option to keep the current architecture when migrating to the cloud, including any virtualization, storage and networking layout.
This results in a Virtual Machine running atop of a public cloud service in an Infrastructure-as-a-Service offering, which usually includes advanced software-driven features for networking and storage.
For storage, a specific approach is appropriate. It’s important to investigate if the data and the application can easily be unglued so that the data can move into a cloud-optimized storage (or database) platform. If so, it might be a good candidate to move into higher-level application services in the cloud, like Google’s App Engine, a Platform-as-a-Service that supports Python, Java, PHP, Go and other programming languages. If it’s not so easy to untangle the data from the application, moving into a more traditional Infrastructure-as-a-Service offering like Google Compute Engine makes more sense, since this allows the current VM-architecture to be retained.
You get the picture: everything you’re acquainted to in the on-prem datacenter exists as a separate function in the public cloud, and each service is highly optimized. For applications that don’t align with this cloud-native architecture, there’s the more traditional approach of IaaS, software-defined storage and software-defined networking services. Being able to use such an IaaS-platform means no application is left behind when moving to the cloud.
Comparing clouds (IaaS, PaaS, etc)
Sometimes it’s hard to distinguish between all those different cloud sercices. Let’s take a moment to discuss the most common types:
Infrastructure-as-a-Service
At the lowest level in the stack, there’s Infrastructure as a Service. The infrastructure (compute, networking, storage) is what’s made available for consumption. Comparing this to a traditional on-prem infrastructure: it’s the physical services, storage, networking, hypervisor and associated management layers exposed for consumption. As a customer of an IaaS-service, like Google’s Compute Engine (with Cloud Virtual Network and Cloud Interconnect), you are able to run Virtual Machines on a public cloud services. This is aimed at applications and workloads that are based on the more traditional enterprise IT paradigm, usually consisting of a monolithic Windows or Linux back-end that rely on hypervisor or Operating System constructs for availability.
Platform-as-a-Service
We’re now one layer up in the stack. A PaaS platform is meant to run native code, abstracts the infrastructure layers talked about in the IaaS-layer, the virtual machine, guest operating system and middleware layers to offer a platform where you can run native programming language code directly. In the case of Google’s App Engine, you can use code written in Java, Python, PHP and Go.
A PaaS platform is much more flexible than IaaS, as complex constructs are automated and presented as standard features using application runtimes. Things like caching, database services, code security scanning, automatically scaling performance needs and more are taken care of, making it more aimed at developers, catering to their needs and offering services in their realm.
A PaaS-platform usually has a set of peripheral services integrated to provide object-based storage, MySQL or noSQL databases, load balancing, monitoring and logging functionality.
Think of a PaaS platform like running a bunch of virtual machines, each contributing a specific services to the application, which is running on a middleware layer on one of these VMs.
More recently, PaaS is morphing in two distinct directions, each worthy of an explanation:
Container-as-a-Service
Container-based infrastructures like Docker are gaining momentum fast. They’re immensely popular with both the development and infrastructure communities, as containers and Docker cater to both sides of the table equally and are very flexible in terms of which application architectures they support.
CaaS is a container-based approach to IaaS (which is VM and hypervisor centric). Containers, and Docker specifically, sit nicely between IaaS and PaaS from a developer view: containers allow for more freedom in terms of dependencies (and packaging those up automatically) and flexibility in the developer workflow and associated tooling. A lot of the peripheral services included in a PaaS-stack are now left to the developer to include, which is often done by adding open-source components as individual container services to the architecture.
Google Cloud Platform is a special place to run containers, too. As part of Google internal development practices, the use of containers has spread widely. They were one of the first to implement a container strategy, and have developed numerous pieces of tooling around this. One of the better known projects to emerge from Google’s container push is Kubernetes, a container orchestration and management solution.
Serverless Computing, a Flock of Birds or functions-as-a-service
Where CaaS is taking a small step down in the stack, serverless computing takes giant leaps upwards. This function-based approach breaks down a cloud-native app even more, focusing on asynchronous events that trigger a certain application function to be executed. This approach allows developers to create small, single-purpose functions without taking care of the IaaS or PaaS layers. In a way, this is the cloud-native reincarnation of the PaaS platform, focusing on specific functions rather the complete package to run the app on.
Software-as-a-Service
And finally, SaaS. Software-as-a-Service is probably the easiest to explain. SaaS is when an application vendor decides to host and publish their application from a cloud platform. Good examples are Google Apps for Work, Microsoft Office365 and Salesforce.
A SaaS-application hides all the complexity lower in the stack, but might be based on other ‘as a Service’ services. For instance, Google Apps for Work runs on top of various Google Cloud Platform services like Compute Engine, App Engine and Container Engine.
The SaaS approach is aimed at those looking to consume a certain (3rd party) application on a pay-per-use, flexibly scaling way. It’s the easiest way for an application user to consume the 3rd party application, as the application is usually browser-based and is publicly accessible.
So, looking back at the different types of cloud, it’s becoming clear that there are, roughly speaking, two target audiences for cloud services: the infrastructure operations and the developer communities. For both, these different generations of services to choose from, depending on the skill set, maturity and application architecture.
 This post is part of the Cloud Migration with Sureline Systems Tech Talk Series. For more information, please see the rest of the series HERE. Sureline has an industry-leading Application Mobility solution that provides high quality recovery points and replicates them remotely. This ensures zero data loss and the ability to test disaster recovery plans easily and frequently without locking you into a specific cloud solution. To learn more, please visit their website at http://www.surelinesystems.com.
This post is part of the Cloud Migration with Sureline Systems Tech Talk Series. For more information, please see the rest of the series HERE. Sureline has an industry-leading Application Mobility solution that provides high quality recovery points and replicates them remotely. This ensures zero data loss and the ability to test disaster recovery plans easily and frequently without locking you into a specific cloud solution. To learn more, please visit their website at http://www.surelinesystems.com.