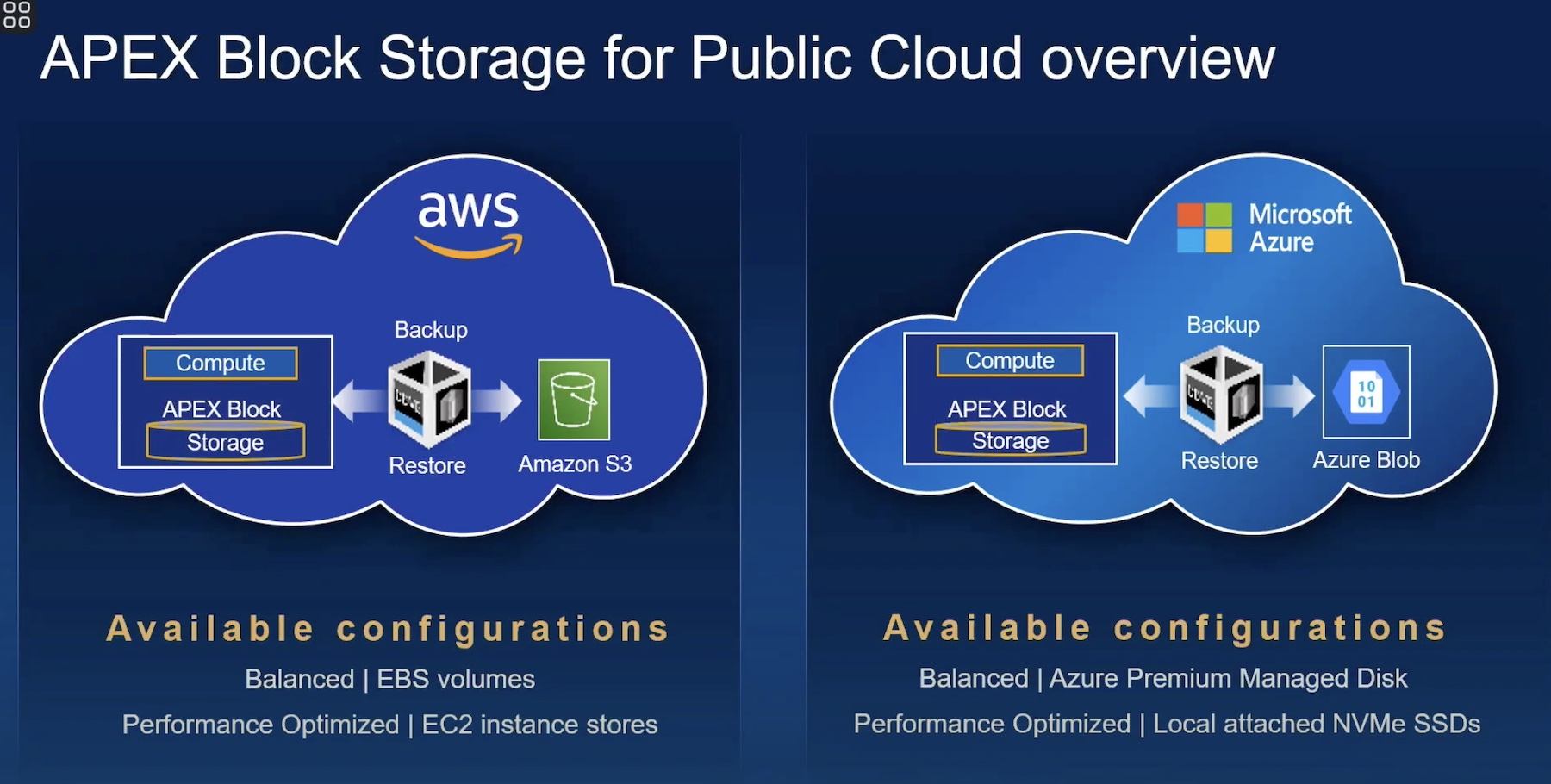
A while back, I discussed speculation from EMC around Emulex’s proposed cloud-block storage appliance, E3s (Enterprise Elastic Storage). With my current focus on Cloud Storage, I thought it would be good to delve a bit deeper into some of the aspects of why block-based cloud computing could prove tricky and why without an appliance it may be impossible.
Block Storage Legacy
Today, block-based I/O still uses the SCSI protocol to communicate between a host/server and a disk storage device. SCSI has been around since 1981 when devices were physically connected to the server itself using a controller board and old-style ribbon cables. Obviously we’ve progressed somewhat since then and seen the virtualisation of the physical SCSI interface into Fibre Channel and IP SCSI implementations (and in the future FCoE). Both FC and iSCSI have removed the need for a dedicated SCSI controller card and replaced it with Host Bus Adaptors (HBAs) and Network Interface Cards (NICs). Irrespective of this, the underlying communication protocol remains the same and the concept of the “Initiator” (host/server) and “Target” (storage device) persist today. The Initiator starts (or initiates) an I/O request; the target services that request, reading or writing data.
Writing In Blocks
We need to focus for a moment on the concept of block-based I/O versus file-based I/O. Block-based I/O has no concept of the format of the data being written to the block device (let’s call it a LUN). This is in contrast to file-based I/O where the storage device understands the data format and manages the content accordingly, ensuring data access is serialised correctly and that files are held in a logical structure (a file system). Unfortunately block-based I/O is just “dumb” storage and the host itself is responsible for overlaying a file system onto block-based devices. These JBBDs (”Just a Block-Based Device”) can be used singly or combined in complex ways to create the file system the host sees. This combination can be achieved using native Logical Volume Managers (LVMs) on the operating system, or add-ons such as Veritas Volume Manager. Consequently, an individual LUN could contain an entire file system or only a small component of one. Either way, the host operating system depends on one feature of the storage device to ensure data integrity and that’s Write Order Consistency.
Write Order Consistency
Preserving the order in which data is written to disk is a fundamental requirement for modern Journalling file systems like NTFS. Retaining write consistency ensures the file system can be recovered in the event of a server failure or failure of the link between server and disk. Ordered writes are also essential where data is replicated from one storage array to another usually at a remote location. In the event that the primary array is lost, the file system can be recovered in a consistent fashion on the remote device, even if it isn’t 100% up to date.
Remote replication can occur either synchronously or asynchronously. In synchronous mode, I/Os are acknowledged from the remote array before the I/O is confirmed as completed to the host. This ensures both the primary and remote copies are write-order consistent because the host doesn’t receive acknowledgement of I/O completion until both the local and remote copies are written. Write-order consistency is implicitly guaranteed. However, the penalty for this guarantee is the increase in latency (or host I/O response time) which results and increases with the distance between the two devices. Asynchronous replication is slightly different. Write I/Os to the primary array are acknowledged immediately, then queued up for writing to the remote device. The delay in writing data to the remote location is dependent on the bandwidth available and the latency (effectively the distance) between the devices. In any event, as long as write-order is maintained, the remote copy can be recovered even if it doesn’t represent the absolute latest copy of data. One last consideration. We touched earlier on how LVMs can combine single LUNs to create complex file systems. When asychronous replication is involved, write I/O for a single entity like a file system need to be treated together for write-order consistency. Therefore Consistency Groups allow multiple LUNs to be grouped together for write ordering, ensuring that all I/O for the file system is ordered correctly. This requirement doesn’t exist for synchronous replication as the consistency is guaranteed by ensuring the write I/O has completed on both the source and target array before acknowledgement to the host.
The Need for an Appliance
Knowing how write-ordering affects consistency is important in understanding how a block-based device would be replicated into “the cloud”. Due to latency issues, it is unlikely that synchronous replication would be offered as a method of replicating data from a host server into Amazon S3 or EMC Atmos. Instead, the most likely process will be asynchronous processing and that means installation of a dedicated appliance. The question is, where in the data path should it sit?
The Splitter
There’s no requirement for a host/server to be connected into a storage array in order to utilise cloud storage. Instead, at some point in the data path between host and local disk, a copy of the write I/O needs to be taken. This could occur at the file system level using a host agent or in a SAN environment could happen in the fabric or from the array itself. Wherever data is taken from, some form of “I/O splitter” is needed to capture write I/O as it is being transferred to disk. This technology already exists today in products like EMC’s RecoverPoint and Brocade’s Data Mobility Manager.
So here are our requirements for a block-based storage protocol:
- Write Order Consistency
- Consistency groups
- An I/O splitter or replicator
A Theoretical Implementation
Here’s how I think block-based storage could be implemented. I’ll use the Atmos and Amazon S3 protocols to demonstrate the process. Firstly, data will be stored in blocks. Both S3 and Atmos store data as objects and so each object will need to represent a block. The file system structure can be used to store individual LUNs, with a directory representing a LUN. For example LUN 12, block 12343 could have the object name:
\S3\Array1\LUN12\12343
It’s worth noting that there’s a distinct difference between the way Atmos and S3 implement updates to objects. S3 replaces the entire object, whereas Atmos allows part of an object to be updated. So, Atmos could store an entire LUN as an object whereas S3 can’t, unless the entire LUN is replaced on each write. Clearly that’s impractical but does indicate that each API implementation will have certain benefits and disadvantages.
So, how big are these blocks going to be? Ideally, they’d be as small as a typical hard drive block at 512 bytes, however blocks of this size will seriously hamper throughput if write consistency is to be maintained; imagine 5ms latency into the cloud; that’s only 200 IOPS and consequently a throughput of 100KB/s. What’s more practical is a block size matching the O/S file system and/or database, say 8KB. Even at this size, with 5ms latency and a single thread of I/O, that’s only 1.6MB/s throughput.
Obviously this level of throughput is not going to be acceptable and there’s a real sticking point here. The cloud isn’t intelligent. It will write data as it’s received. There’s no locking control and the delivery mechanism could be unpredictable. If writes are issued in parallel, there’s no way to guarantee the I/Os are written to the cloud in the right order. So perhaps a different approach is required. Data writes to the target LUN need to be written in a log format, with the name of the object comprising both the block number and a sequence number. This could be something simple as follows:
\Atmos\Array1\LUN12\SequenceNumber-BlockNumber
e.g. \Atmos\Array1\LUN12\123445343434366-12343
As the LUN is written to, the sequence number (unique to the LUN or consistency group) is incremented for each write. The I/Os can then be written in parallel as the sequence numbers track what has and has not been received. At this point there are two choices — retain all the block updates (unlikely due to the growth in storage usage) or post process the writes, deleting all the written blocks where another later copy exists and where there are no gaps in the sequence numbers. If there is a gap, then the LUN writes are only guaranteed back to the point where the sequence number gap occurred. Restoring the LUN for access means processing the LUN block data before it can be read again by the host.
Summary
OK, so this post presents an idea of some of the issues involved in writing block-level data into the cloud. Data needs to retain integrity and consistency, but performance and throughput are an issue. Cloud storage has no intelligence, so writing and managing data needs to be handled somewhere, probably using an appliance. The appliance guarantees the data integrity which can’t be achieved with the cloud alone. Each Cloud Storage API implementation will have similar features, so using generic CRUD (Create/Read/Update/Delete) commands on objects representing blocks means any service could be used to store data. It also enables data to be replicated between services so vendor lock-in can be avoided.
I’d be interested in receiving feedback to see if anyone else has thought how block-based cloud storage could be achieved.