More than two decades ago, John Gage, co-founder of Sun Microsystems, famously said, “The Network is the Computer.”
The network, he said, is at the core of every computer, and with appropriate software and computing, it can be used to distribute intensive computational tasks among separate processors.
His slogan came to be internalized as a Silicon Valley truism, and a core principle in higher computations like AI.
A Breakdown of AI Model Training
AI workloads like large language models are colossal – some newer models have billions of parameters, and the future generations rumored to reach trillions. These require vast amounts of elastic compute that no one CPU or GPU is capable of offering.
It takes hundreds of interconnected GPUs working as a single unit, and thousands of these units working as clusters to train these models. The GPU clusters share the datasets and computation workload providing the models the processing power they require.
But AI networking is unique not just in the insane amount of compute power that goes into processing these workloads. It is also distinguished in the way the models are trained. Large language models are trained in iterations, through repeated cycles of compute, communication and synchronization.
First, a prodigious amount of data is fed into the system. The model learns skills through finding patterns in this data. By looking at thousands of shades of the color red, for example, it learns to recognize it.
Parameters dictate the learning process and outcomes. Across distributed systems, these parameters are synchronized and updated over and over until the models are able to instantly translate data into information.
Time to Completion
The training process has several implications on the network traffic. For one, the traffic flows are high bandwidth because of the massive amounts of data flowing to and fro. Entropy is lower in AI network than is seen in traditional computing applications. Being synchronized, the traffic bursts at a high rate leading to saturation of links within micro-seconds.
Typically, training jobs are time-intensive, and take anywhere from several hours to days on end to complete. An important ingredient in this is network I/O. The higher the tail latency, the longer the job completion time. And with large data transfers, tail latency is often high and unpredictable.
Companies have experienced protracted training times with large language models. According to data shared by Meta at the OCP Global Summit in 2022, 50% of the time in DLR model training is lost in networking. In other words, half the time, the GPU nodes are idle, waiting for the network to pass on the data. “The longer it takes or the longer the network is in the way, the more the training performance is impacted,” said Mohan Kalkunte, VP of Architecture and Technology at Broadcom, during a presentation at the recent Networking Field Day event.
Small Issues, Big Headaches
Several factors contribute to network bottlenecks. A common one among them is oversubscription where less resources are available than is potentially required. Reduced I/O, specifically in AI/ML networking, is caused by flow collisions and link failures. A problem commonly seen with traditional ECMP routing, when more than one flow is mapped to one link, it leads to packet loss and failures, a phenomenon that deeply impacts the performance of the network.
Another factor is incast. This happens in a many-to-one communication pattern where multiple GPUs send traffic to one, leading to a throughput collapse. “If the traffic is not controlled, it will result in incast, and no matter how much packet buffer you have, you might still lose packets, and that impacts the performance of a training job,” warned Kalkunte.
Organizations are slowly pivoting towards network singularity. In the past several years, rise in multi-tenancy has kicked off a shift causing the front-end and back-end networks to merge. What was required only for the front-end network where the compute applications are, is now required at the backend where the AI training happens.
“We see cloud companies wanting to support multiple tenants even for AI as a service, which makes multi-tenancy a necessity for the back-end networks as well. What this means is that you need to have a consistent set of tools and telemetry across the network,” he said.
Melding infrastructures into one network is key to supporting multi-tenancy and promoting operational simplicity, but in no subtle way, indicates the need for a purpose-built network that is practical for AI/ML applications.
Scheduled Fabric Solutions from Broadcom
Broadcom offers two solutions addressing the networking requirements and trends for AI model training. Broadcom markets them as Scheduled Fabric Solutions. Named after the design, the solutions have a receiver-based scheduling, meaning no traffic can cross over to the fabric without the explicit permission of the receiver. This ensures a congestion-free fabric by bypassing the key issues of flow collision or link failure.
The first is a switch-based fabric that uses Broadcom’s two highest performing solutions – Jericho3-AI and Ramon Series. Launched in April, Jericho3-AI has been dubbed the industry’s highest-performing fabric. The Ramon Fabric Devices on the other hand are known for their high power-efficiency and AI optimizations.
In a leaf-spine topology, the GPUs connect to the leaf switches based on Jericho3-AI family using Ethernet connectivity (400GE and 800GE). All intelligence lives in the Jericho3-AI switches that do the switch lookup, queuing and scheduling. Upon receiving the packets, the switches break them down and distribute them across the spine fabric. The Ramon Fabric reorders the packets and sends them back to the GPUs. With no package processing occurring on the spine switches, high energy-efficiency is ensured.
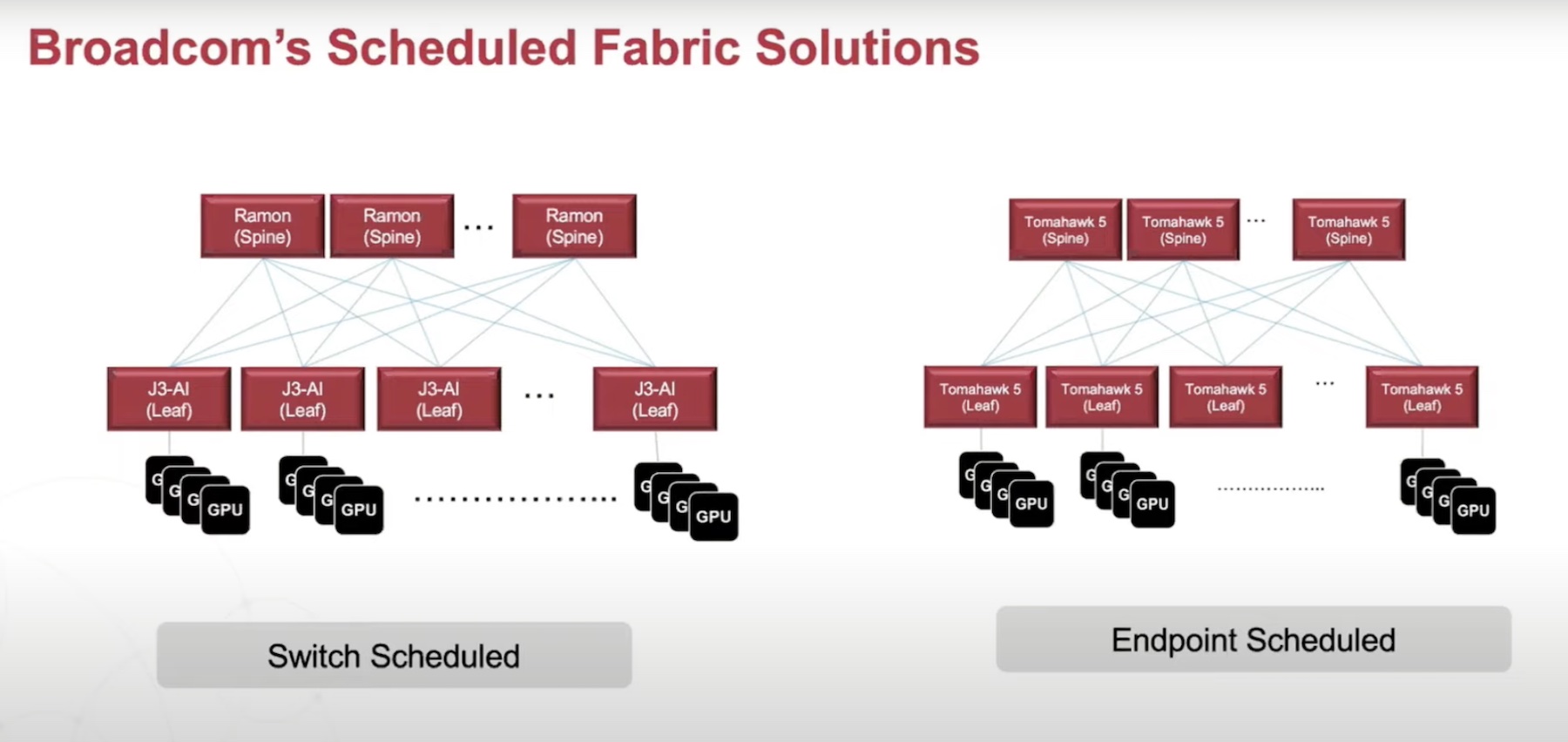
Broadcom offers two deployment options for the switch-based fabric. Users can put the leaf switch in the same rack with GPUs or endpoints, saving substantially on power and cost. Alternatively, they can put the leaf/spine switches in the network rack and interconnect with GPUs over distance.
The second scheduled fabric solution is based on Broadcom Tomahawk 5, a high-bandwidth switch series for AI/ML computing. Unlike the first one, this fabric is endpoint-scheduled, meaning all intelligence resides in the endpoints. The Tomahawk Series comes with high radix and accelerated job completion making it a great product for AI/ML training.
Wrapping Up
Broadcom’s specialized solutions for AI processing bypass the imposing challenges that stymie enterprises’ AI/ML initiatives. The fabrics greatly reduce networking time with increased I/O, creating an opportunity for organizations to accelerate training time and ensure faster job completion. In the process, they unlock substantial savings not typically achievable with AI training.
Be sure to watch the demos of Broadcom’s Scheduled Fabric Solutions from the Networking Field Day event at the Tech Field Day website.