When it comes to assimilating training data for AI models, companies take an absorb-everything approach. Text, videos, images, and metadata are scraped and schlepped across the vast expanse of the Internet and private networks. This becomes the fodder for AI models. The volume of data is critical to boost the models’ ability to answer questions, solve puzzles and make discoveries.
But behind the scenes, data orchestration is a complex game. For a small group of engineers, sourcing and taming this corpus of unstructured data is very real challenge.
Using Data from Multiple Sources
Most times, the datasets are scattered across geographies, localized to specific cloud or storage systems. Every minute, this data is changing, making global real-time visibility ambiguous.
“Global access is key in an environment where you’ve got AI applications running,” says Floyd Christofferson, VP of Marketing for Hammerspace. “You need to be able to see all of your data, not portions of it.”
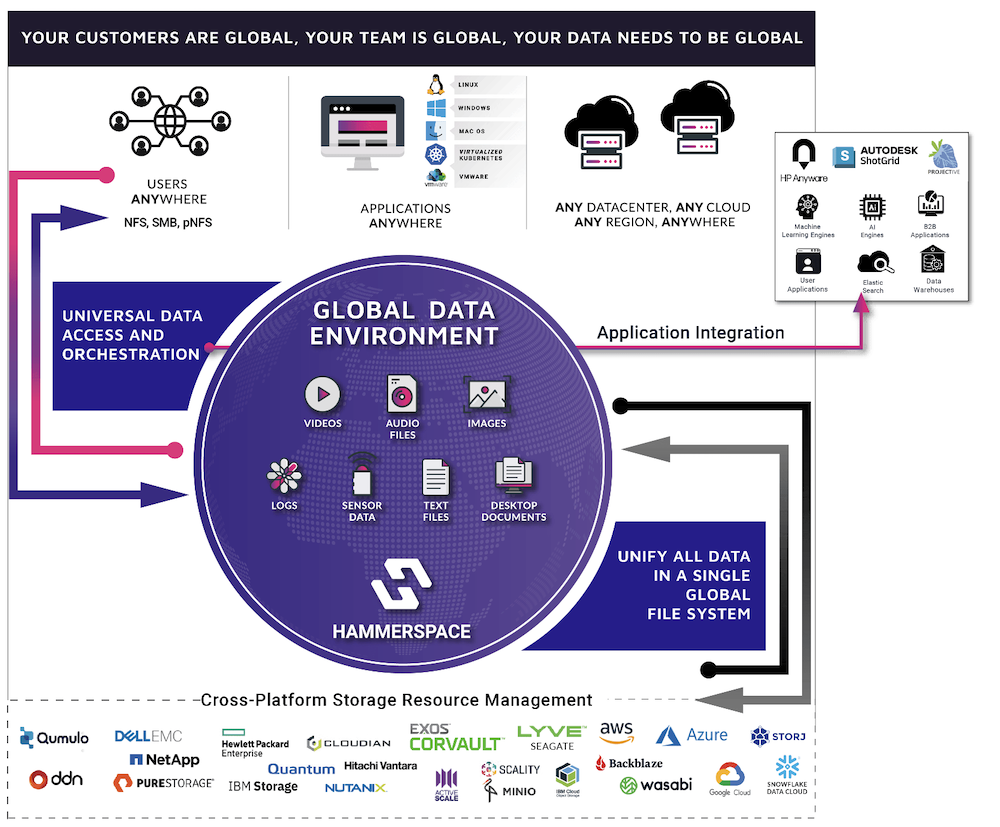
Unfortunately, clear visibility has eluded IT personas the most in this distributed ecosystem. At the AI Field Day event in California, Hammerspace showcased Global Data Environment, a software that automates aggregation and orchestration of this data as it travels downstream.
Distributed storage silos are the bane of AI workflows. “When you have multiple storage types, as is often the case in the enterprises where they’re running training or inferencing workflows off of data that may already exist on different storage silos, you’ve the file system metadata separated from the actual data itself. The file system metadata is locked into the underlying storage.”
This separation means fragmented visibility and access. “This file system metadata which is all of what you see when you look at a screen – the file, the folder layouts – all of that is that file system metadata.”
This poses a problem at both ends – it makes it difficult for users to access data, and a slow-burning complexity slows down administrators.
Unifying Data from Everywhere with Hammerspace
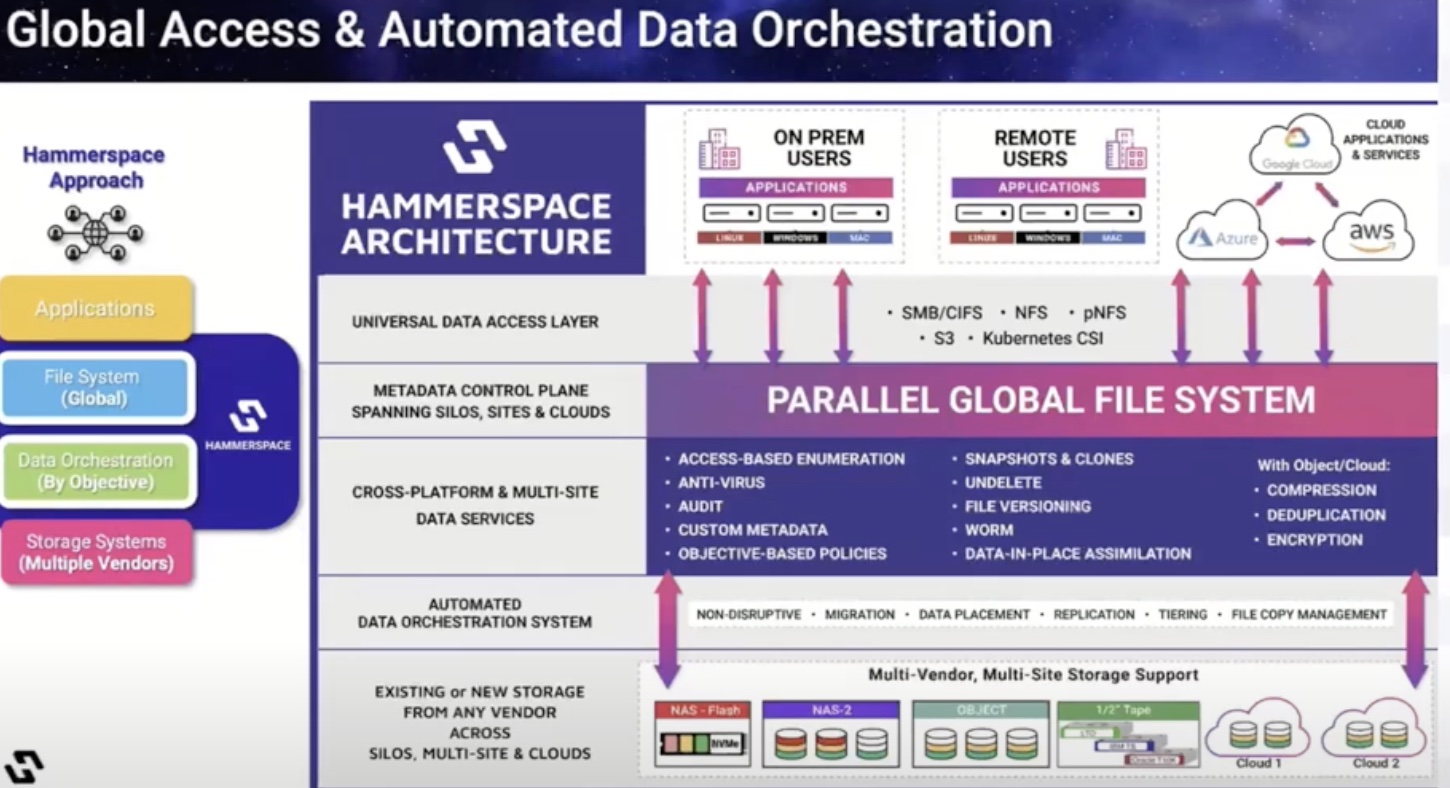
One approach to solve the problem is to lift the file system out of the infrastructure layer. Decoupled, now this file system is separate from the underlying storage, and can be accessed universally.
The Hammerspace Global Data Platform is designed in the same way. It puts the metadata path and the data path apart. Data remains in the existing storage while metadata is aggregated and placed into a parallel global file system. This file system serves as a global data environment for all data and users, irrespective of location.
The Hammerspace shared metadata control plane and namespace span storage silos, sites and cloud platforms, making it the one place where data is live and accessible to one and all.
The visibility is total and transparent, says Christofferson. “You could have a file open and be working on it, and that data could be moved from one storage or even one location to another, and you wouldn’t know, in the same way that you wouldn’t know if you are looking at a file on my disk and it’s active and open and moving from one platter to another or one disk subsystem to another in a standalone NAS.”
File access is done the usual way. Users anywhere in the world view the same data – not copies, but the same files – whether it’s stored in a private datacenter or in the cloud.
A breadth of cross-platform and multi-site data services is offered as part of the global data environment. Encryption, snapshotting and cloning, file versioning, compression and deduplication, auditing and many such tasks happen quietly in the background. “Users are never disrupted, and it doesn’t add complexity to the users,” says Christofferson.
These services can be leveraged for any data, irrespective of the storage it is in. “Data services are now possible across all of the data, whether it’s on a legacy storage, a new storage, in the cloud, or on a remote site. You can take this global view and global control over all of that and automate it.”
Administrators have command and control of the global data orchestration. They can manage storage resources granularly without affecting the users’ visibility and access. Objective-based policies ensure that things like data protection and tiering happen on auto-pilot as opposed to manual management through point solutions.
“The system is constantly monitoring the objectives – if the data is in alignment with the actual objectives, and will send alerts when it is not,” he says.
The local access and global control of data is key to fueling enterprise AI workflows. “By creating a global data environment which extends the parallel file system globally, and using data orchestration to automate where the instantiations of those files are, without interrupting users, without creating copy sprawl, and without limiting to certain types of storage, enabled this to go much farther.”
For a deep dive, be sure to watch Hammerspace’s presentations from the recent AI Field Day event. Also check out Alastair Cooke’s analyst insight on this at The Futurum Group website.