Many of today’s organizations rely on their proprietary applications to fill their customers’ as well as their own needs, but feeding those applications with data can be tricky when the data needs to be sourced from virtually everywhere in the environment. Hazelcast, who appeared at June’s Cloud Field Day event, offers a solution for this problem by way of their In-Memory Compute Platform, which creates a unified data layer for creating intelligent context for applications in real-time.
Combining Data Sources from Across the Environment
For many IT admins, running their organizations’ proprietary applications has become an integral part of their essential duties. This mashing of the roles of DevOps and IT has sparked several other crossovers as well, such as the incorporation of data collected from both around the organization and in-app sources into the app itself. Leveraging multiple sources of data allows IT to automate application processes, making their apps work more effectively while also saving them time.
However, with environments that are growing more disparate by the day, being able to actually ingest data from a variety of different sources is often easier said than done. For example, keeping data flowing between hybrid cloud environments and on-premises mainframes can be painstaking, requiring multiple tools and operations that take their toll on an IT department’s budget and time.
The Hazelcast Unified Data Plane
Hazelcast offers a solution to this issue, creating an underlying, unified data plane with their flagship In-Memory Computing Platform. Combining the data collected from the data plane with context data pulled from traditional sources, Hazelcast provides intelligence to business applications that allow them to operate more efficiently than they would without.
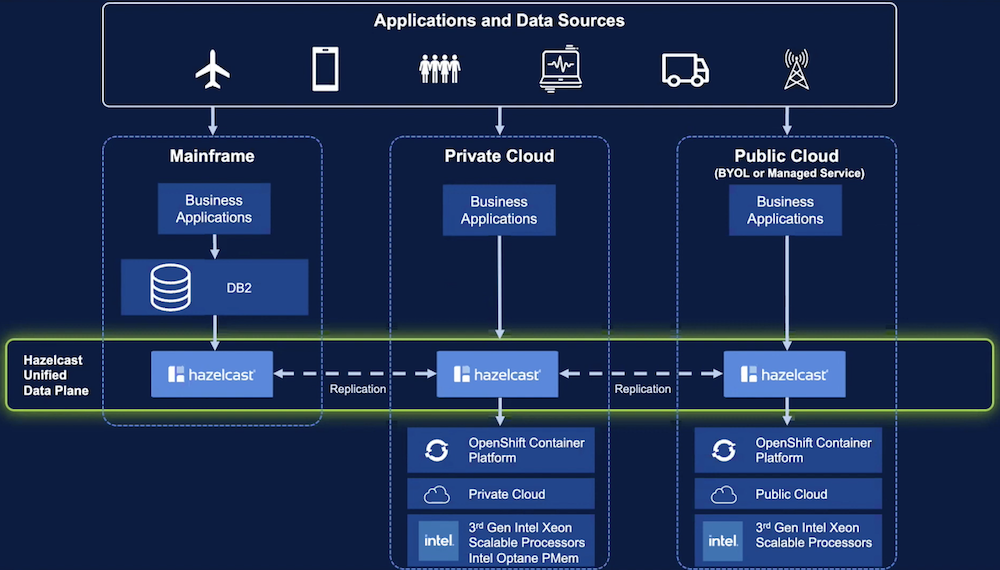
Hazelcast works by pulling data from practically every source and ingesting it into its in-memory compute engine. There, the data is analyzed and compared to existing systems of record, both to obtain context and adjust those records based on the newly ingested data. The data then outputs back to endpoints that consume it, using the context generated by the Hazelcast product to automate processes. Because data is processed in near-real-time, Hazelcast speeds up application processes tremendously, making IT admins’ lives easier while ensuring high application performance.
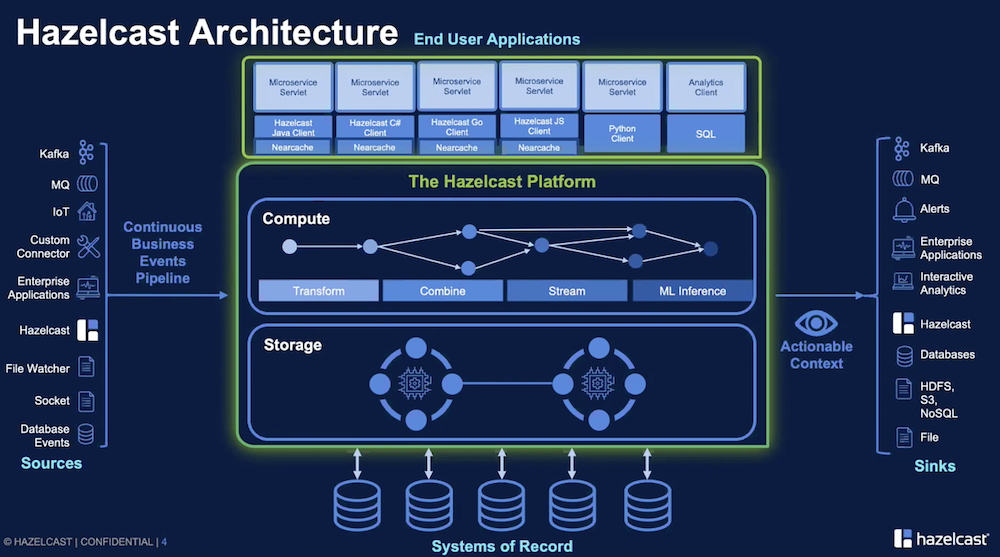
Hazelcast in Action
At June’s Cloud Field Day, Hazelcast’s Senior Director of Technical Solutions, Dale Kim, gave an overview of the product. During his presentation, Kim also ran through several common use cases of Hazelcast in real-world applications.
For instance, with applications running multiple microservices, Hazelcast acts as the underlying storage and compute layer. This enables each process to run simultaneously and locally, reducing latency, while also ingesting the data that Hazelcast processes, making each microservice “smarter” at the same time.
Another key use for Hazelcast is in scenarios with multiple IoT devices acting in tandem, such as manufacturing environments. The information coming in from each device can be likened to a data stream, and since Hazelcast operates in real-time, the data stream is analyzed at the same rate, allowing for fast-paced analytics across every device. That way, instead of having to continuously pull information from devices and interpret them individually, admins can rely on Hazelcast to ensure the entire setup runs properly from a top-down view.
Zach’s Reaction
Hazelcast takes the banality out of analyzing hundreds of data points, using its built-in compute engine to interpret and act upon them intelligently in real-time. For high data operations, such a capability improves process speed while also reducing the work required on the part of the IT department to keep things running intelligently and smoothly.
Learn more about Hazelcast by watching all of their Cloud Field Day presentations, or by visiting their website.