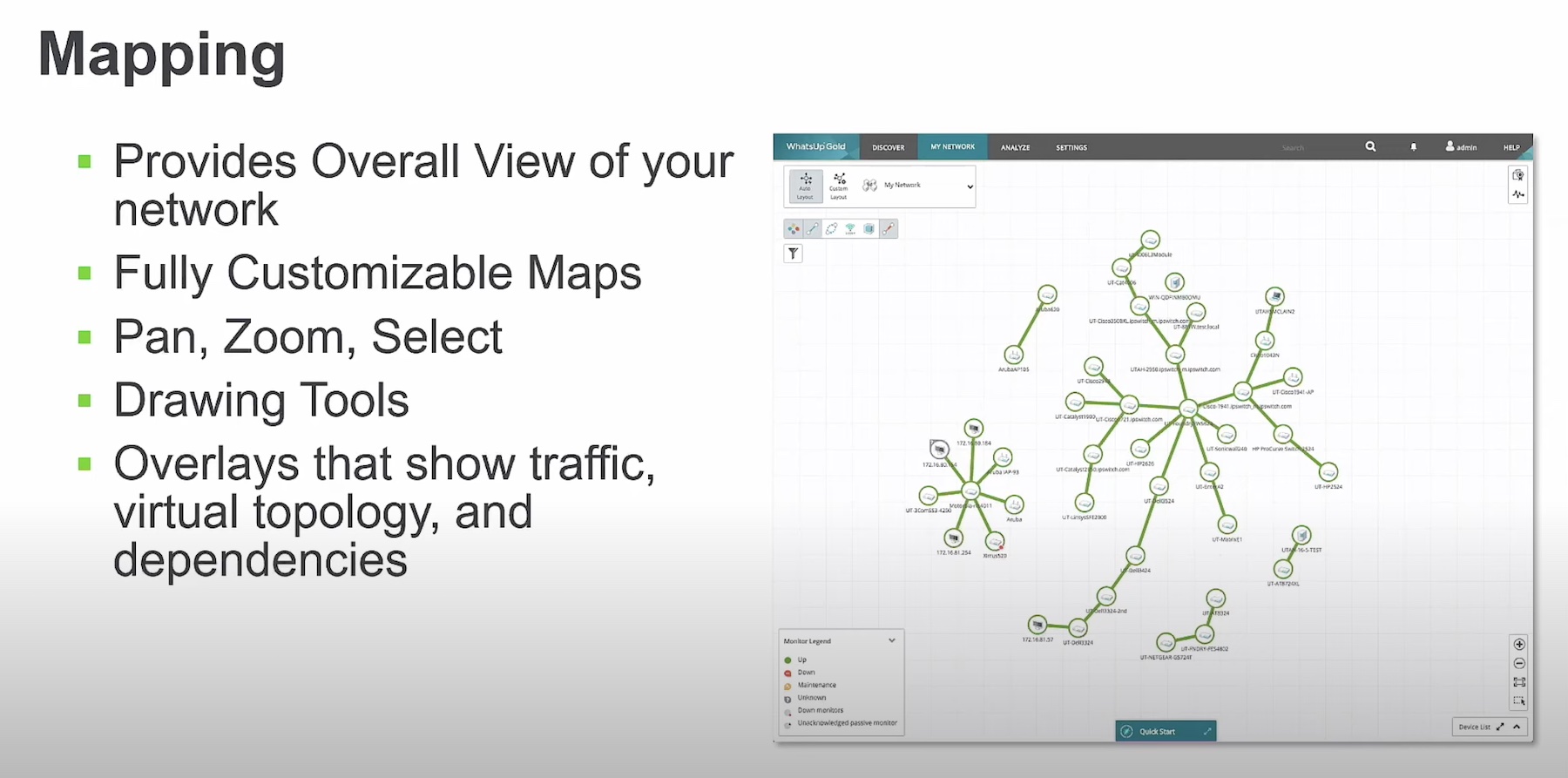
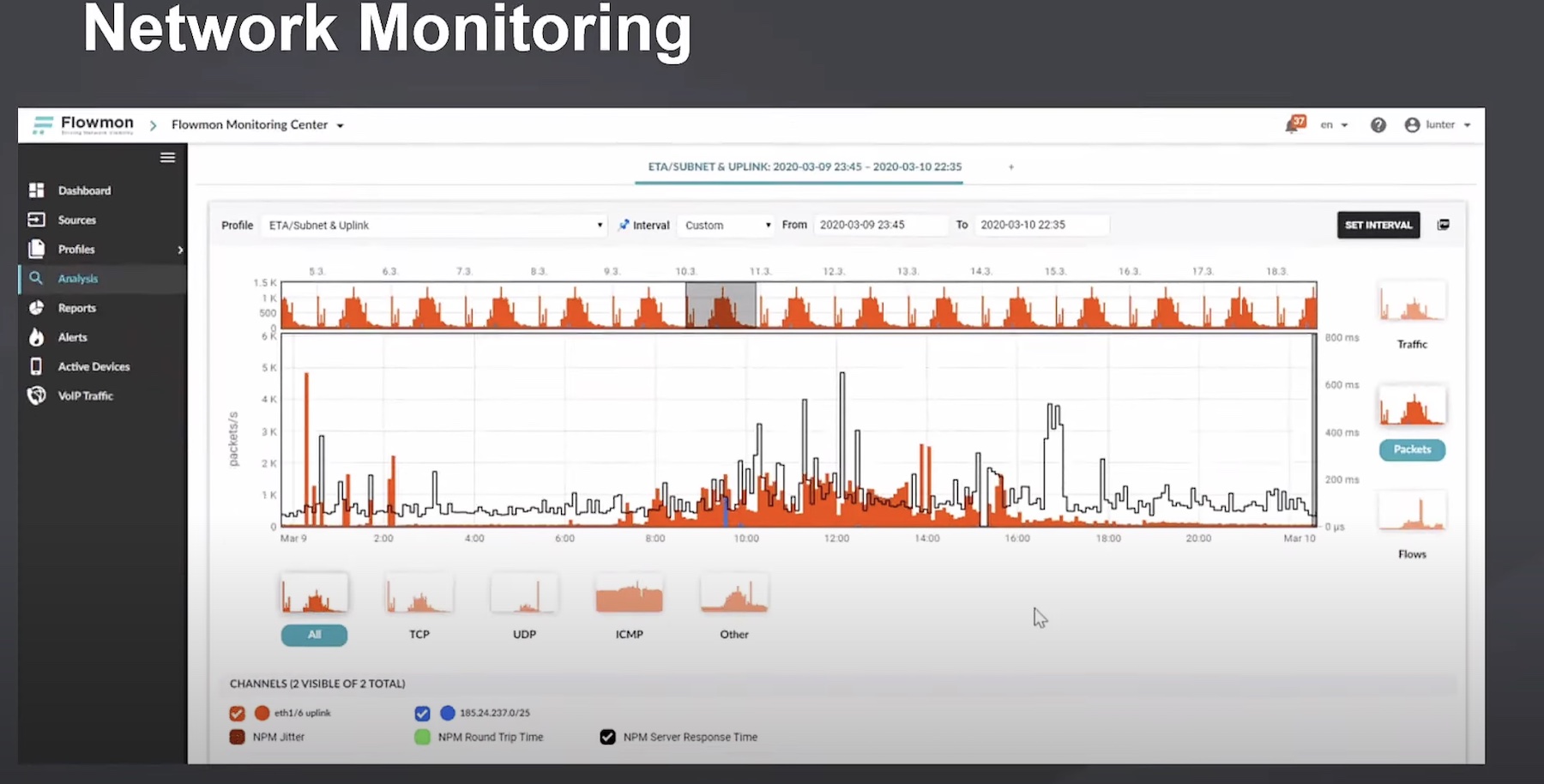
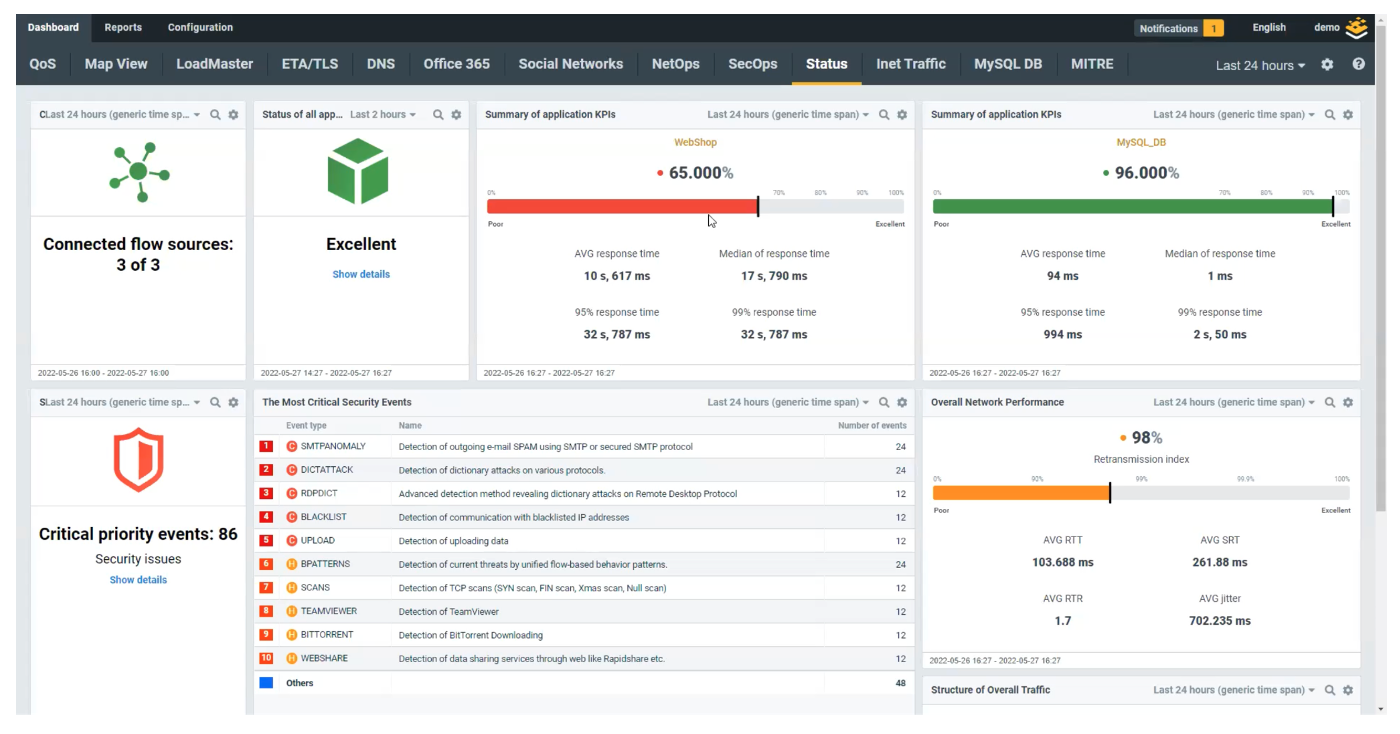
You’ve collected a bunch of data, and hopefully done something about classifying it and only keeping the useful stuff, instead of hoarding all the data you can get your hands on just in case.
Now what?
Let’s assume that you have your house in order and you’ve got good systems in place for dealing with Type I and Type II data. You want to go looking for insights in your Type III (Competitive) and Type IV (Speculative) data, presumably so that your organisation can be more effective. That might translate into more revenue, better margins, or simply better fulfilling your organisation’s mission.
The tragedy of the modern fascination with data analysis is that it’s obscured by a lot of empty marketing, hype, and plain old snake-oil. There are incredibly powerful tools being brought to bear on problems such as that.
From Correlation to Insight
Much of what masquerades as insight in the popular press would be more accurately described as correlation. Just because you’ve found a correlation between an increase in sales and data-centre temperature doesn’t necessarily mean anything. There is a strong, positive correlation between per-capita cheese consumption and the number of people who died by becoming tangled in their bed-sheets. That’s not insight.
 However, an increase in sales could result in a lot of extra data processing, which consumes more CPU time (and therefore electricity) which leads to the servers giving off more waste heat, increasing the temperature of the data-centre. The two things are indeed related, but cranking up the thermostat in the data-centre won’t increase your sales.
However, an increase in sales could result in a lot of extra data processing, which consumes more CPU time (and therefore electricity) which leads to the servers giving off more waste heat, increasing the temperature of the data-centre. The two things are indeed related, but cranking up the thermostat in the data-centre won’t increase your sales.
A large Australian retailer spent a lot of time and energy seeking out insights from their trove of customer purchase history data. They discovered that women buying lingerie also bought chocolate. And then, in a surprising twist, they discovered that people who bought women’s outerwear also bought chocolate. What about men? Yes, they too bought chocolate, because 95% of all people buy confectionery in conjunction with other things. Which they already knew. No insight here.
Computers aren’t magic, which is a surprising thing to have to point out at times. In fact, they are incredibly stupid. They do a great job of doing exactly what you tell them to do, not what you mean. Relying on a computer to tell you the meaning of something is a fool’s errand, and yet that seems to be what many people expect them to do.
Artificial Stupidity
Using computers to find correlations more easily is an excellent beginning, but a poor ending. A computer will happily tell you that, according to its programming, that picture of a hamster is a photo of the Eiffel tower, and it will be 80% sure. This task is something a human finds trivial, yet even the most powerful computers struggle.
Adding yet more data and more complex algorithms doesn’t solve this basic problem: computers are idiots. They will happily calculate a GPS route to your destination that leads over a missing bridge, or through a lake, and blindly following these instructions can lead to disaster. Some sort of sanity check is still required by a suitably qualified human, in order to deal with incorrect answers from computerised models.
Because that’s all the computer is dealing with: a model of the world. The insights you seek are, at their heart, a simplification of the complexities of the real world. All models are wrong, but some are useful, and it is this usefulness that requires human judgement to determine. The computer is just another tool to help us find ways of making sense of the world around us.
The key is to use computers and human judgement in tandem, each checking on the other. Humans perform poorly at overly repetitive tasks, while computers can scan large amounts of repetitive data (such as log files) to find patterns or anomalies – day in, day out – without getting bored. Humans can then use this as input to form testable hypotheses, and then perform experiments to see if their hunch pans out. The computers can further help the humans from fooling themselves into thinking something is important when it isn’t, and the humans can help the computers from doing the same. This is the process underpinning the whole of human progress, commonly referred to as science.
These new and powerful tools available to us, as well as the rich sets of (possibly useful) data mean we could potentially find useful insights. But we may also find nothing, and we need a way to figure out the difference.
 About The Author
About The Author
Justin Warren is an Australian MBA who writes and speaks extensively about the intersection of IT and marketing and how advances in technology are changing both. His blog can be found at http://eigenmagic.com and followed on Twitter as @JPWarren.

This post is part of the NexGen Storage ioControl sponsored Tech Talk series. For more information on this topic, please see the rest of the series HERE. To learn more about NexGen’s Architecture, please visit http://nexgenstorage.com.