The momentum is strong for Artificial Intelligence (AI), and while we are inclined to think it’s a nice buzzword to surf on, there are clear use cases emerging across many industries.
Proponents of AI believe that it will radically transform our lives and become a major enabler for businesses. At our current technological stage, we are talking about specialized AI, (not a full sentient, autonomous and perhaps even ubiquitous AI), but about a myriad of AIs developed each to satisfy a specific use case. In the context of this article, we will use the AI acronym to reference deep learning and machine learning.
AI touches a very broad range of applications, such as improving customer satisfaction, to helping to save lives thanks to better detection of certain pathologies.
In fact, the promise of AI-enabled business is so strong that it may create a divide in organizations, and even in societies. Moral aspects aside, it’s highly predictable that AI-enabled businesses and societies will operate with increased efficiency compared to their “analog” counterparts.
Gartner states for example that in 2020, 80% of enterprises will deploy AI.
A guide to deploying AI
Now, “deploying” AI sounds quite optimistic, right? How do we “deploy” AI, what are the prerequisites and how can we accelerate our journey to AI adoption?
At least three ingredients are necessary to enable AI adoption:
- A vision / map of what AI should help accelerate or improve (existing processes, new features, etc.)
- Scientists / specialists who understand AI and who are able to execute on the vision
- AI-tailored IT infrastructure that has sufficient capabilities to support the challenging workloads that make up the AI workflow
Deploying an AI-tailored IT infrastructure can be challenging. It is possible to build your own environment targeted for AI development with commodity hardware but putting it all together from design and planning to physical deployment can be time-consuming. AI will invariably involve the deployment of x86 physical servers equipped with enterprise-grade GPUs (such as the Nvidia Tesla V100 range) as well as fast storage capabilities.
A do-it-yourself approach requires identifying the proper server type, how many cards are expected and based on the number of GPU, what technology to use for data transport. Up to two cards, and you need to use PCIe. From four GPU cards, NVLink is the preferred method.
A modern high-performance scale-out shared storage platform is not only important – it is essential for customers looking to build their AI workflow. Firstly, shared storage avoids the need to manually copy subsets of the data for each pipeline stage, saving the engineering time as well as improving GPU usage. Shared storage empowers the data scientists to collaborate by sharing their workflow easily and integrating the models developed to the applications seamlessly in a DevOps environment. Secondly, with multiple data scientists exploring datasets and models, it is critical to store data in its native format to provide flexibility for each user to transform, clean, and uniquely use the data. It’s this experience that yields more powerful models. Finally, the importance of high-performance shared storage is critical for the entire AI pipeline not just to store the ever-growing datasets. From a network standpoint, a high-bandwidth, low-latency RDMA interconnects becomes critical. A high-bandwidth network helps in fast data movement from storage to the GPUs. Low-Latency RDMA becomes critical during the training phase especially in a large-scale GPU cluster.
The do-it-yourself approach presents the advantage of a lower entry cost, but over time, the expansion support and maintenance of such an environment surpasses the cost of investing in a dedicated AI platform.
Talking about dedicated platforms, it is of course possible to engage a partner to design a custom-tailored environment. But here again the effort is enormous, and it can take up to six months from initial design discussions until effective deployment in operations, if not more.
Pure Storage AI – Jumpstart your AI initiative
Not all AI consumers are interested in diverting their limited resources and time into becoming an IT infrastructure system integrator. The breadth of work needed to ready the IT infrastructure resources needed so that developers can start their work can be dizzying.
In highly competitive industries, three to six months of delay on critical, competition-driven business initiatives can make a huge difference. Organizations that hire rare and expensive human resources such as data scientists need to leverage their expertise from day one considering that data scientists earn base salaries up to 36% higher than other predictive analytics professionals, according to this Forbes article.
Pure Storage has acknowledged this need and the fact that not all AI initiatives are meant to be an IT infrastructure investment endeavor. For this reason, they developed and built AIRI, a fully integrated AI-ready infrastructure stack that enables organizations to spend more time on delivering value and achieve a faster ROI.
The AIRI Technology Stack

Figure 1 – AIRI consolidates compute and storage in a form factor that is easy to deploy, operate and maintain
AIRI is delivered as a pre-built solution consisting of the following building blocks:
- GPU-based Compute: NVIDIA DGX1 or DGX2
- Storage: Pure Storage FlashBlade
- Interconnect: RDMA over 100 Gb Ethernet (Cisco, Arista, Mellanox) or InfiniBand (Mellanox)
A complete software stack is delivered with AIRI in order to help organizations get started very fast. The solution includes the AIRI Scaling Toolkit, which allows users to run their first multi-DGX training within hours. This important feature helps slash training time from weeks to days so that scientists can get to work with no delays.
The compute nodes (NVIDIA DGX1 or DGX2 servers) are preconfigured with frameworks and tools (MXNet, PyTorch, TensorFlow, Theano, Caffe2, Microsoft Cognitive Toolkit) to enable data scientists to start working immediately with their AIRI infrastructure. Containerization of workloads is made possible thanks to a GPU-optimized version of Docker.
The NVIDIA DGX systems are the de-facto industry standard in AI computing. Each DGX-1 server delivers one petaFLOPS performance in a 3U appliance, pre-configured with eight Tesla V100 Tensor Core GPUs. DGX-2 servers, on the other hand, integrate 16 Tesla V100 GPUs, using state-of-the-art NVSwitch technology to deliver the low-latency, high-bandwidth inter-GPU communication required for greater levels of model and data parallelism.
The picture below depicts how 8 Tesla V100 GPU in DGX-1 servers can form a compute mesh by using NVLink (green arrows) instead of PCIe.
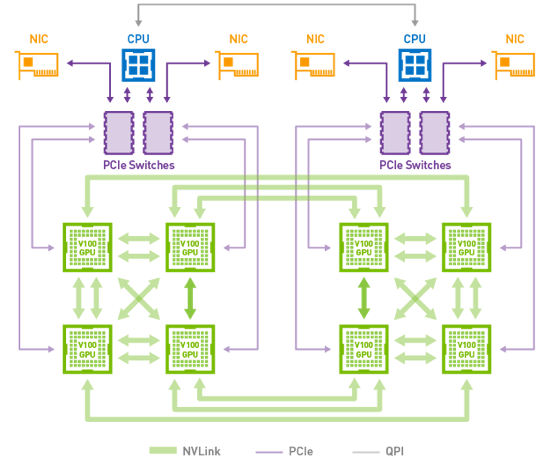
Figure 2 – NVLink connecting eight Tesla V100 accelerators in a hybrid cube mesh topology as used in the DGX-1V server (source: nvidia.com)
From a storage perspective, Pure Storage’s acclaimed FlashBlade is on duty with its scale-out NVMe file and object protocols based on Purity OS. The use of FlashBlade as the AIRI’s storage backend guarantees performance and the lack of any bottlenecks with built-in enterprise-class reliability.
The entire solution has been built to be linearly scalable thanks to 100 GbE connectivity and the right balance between compute and storage. Regarding connectivity, two methods are available. One is to use RDMA over 100 Gb Ethernet (with either Cisco or Arista options), the other one is to use Mellanox-powered EDR InfiniBand.
Both methods are viable, but sharp-eyed observers will certainly not have missed the fact that Mellanox was recently acquired by Nvidia, which may be of added value in the future. Pure Storage had started their integration with Mellanox-based Ethernet and InfiniBand even before NVIDIA acquired Mellanox, which could be seen as a rather solid engineering decision, if not auspicious.
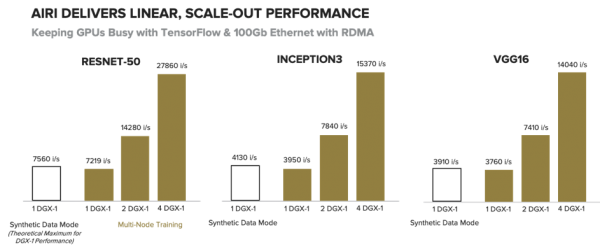
Figure 3 – Several workloads show the linear scalability of the AIRI solution (source: Pure Storage website)
Is AIRI adequately sized for our organization’s AI initiative?
AIRI was built with simplicity and scalability in mind. Pure Storage acknowledges that each of their customers are at different stages of their AI adoption journey. They have therefore developed several flavors of the AIRI platform.
Stage one and two initiatives can begin their AI journey with the AIRI “MINI” (delivering two PetaFlops of Deep Learning performance) or the AIRI (delivering 4 PetaFlops).
Pure Storage has also engineered three options called Hyperscale AIRI for organizations which are in the later stages of AI adoption. Mainstream adoption of AI requires increased compute and storage requirements, and the Hyperscale version of AIRI just does that, with up to nine PetaFlops per rack.
Customer references for AIRI include ElementAI, PAIGE.AI, and also Zenuity, a joint-venture between Volvo and Autoliv which aims to build AI-driven autonomous driving software for production vehicles by 2021. The AI revolution is no longer a fad, it’s happening now as you read those lines.

Figure 4 – AIRI Models & Options
Conclusion – Why Integration Matters
Balance is key in any IT infrastructure but it is essential in deep learning systems. Designing a well-balanced system where none of the components constitute a bottleneck can be a daunting task. It’s not an unachievable utopia, but it takes time, resources and ultimately has a cost.
AIRI is the answer to these challenges. AIRI delivers an AI infrastructure stack that just works, with the right balance and the right toolset ready out of the box.
With AIRI, organizations can finally jumpstart their AI initiatives by leveraging a proven and pre-configured reference architecture that was co-engineered by two market leaders, Pure Storage and NVIDIA.