In recent years, a move toward automated storage tiering has begun in the data center. This move has been inspired by the desire to continue to drive down the cost of storage, as well as the introduction of faster, but more expensive storage in the form of Flash memory in the storage array marketplace. Flash memory is significantly faster than spinning disks, and thus it’s ability to provide very high performance storage has been of interest. However, its cost is considerable, and therefore a way to utilize it and still bend the cost curve downward was needed. Note that Flash memory has been implemented in different ways. It can be obtained as a card for the storage array controller, or as SSD disk drives, and even, as cache on regular spinning disks. However it is implemented, it’s speed and expense remains the same.
Enter the concept of tiered storage again. The idea was to place only that data which absolutely required the very high performance of Flash on Flash, and to leave the remaining data on spinning disk. The challenge with tiered storage in the way that it has been defined in the past was that it meant that too much data would be placed on very expensive Flash since traditionally an entire application would have all it’s data placed on a single tier. Even if only specific parts of the data at the file, or LUN level were placed on Flash, the quantity needed would still be very high, thus driving the costs of for a particular application up. It was quickly recognized that the only way to make Flash cost effective would be to place only the blocks which are “hot” for an application in Flash storage, thereby minimizing the footprint of Flash storage.
The issue addressed by automated storage tiering is that you no longer need to know ahead of time what the proper tier of storage for a particular application’s data needs to be. Furthermore the classification of the data can occur at a much more fine-grained block level rather than the file or the LUN as with some earlier automated storage tiering implementations.
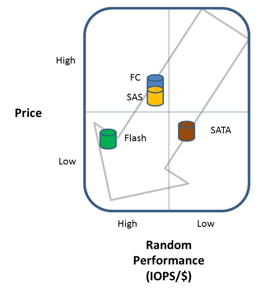
Flash has changed the landscape of storage for the enterprise. Currently, Fash/SSD storage can cost 16-20X what Fiber channel, SAS, or SATA storage can cost. The dollars per GB model ends up looking something like the following:

However the IOPS per $ model looks more like this:
The impact on the tiered storage architectural model of Flash storage has been, in effect, to add a tier-0 level of storage where application data is placed that requires extremely fast random I/O performance. Typical examples of such data are database index tables or key lookup tables, etc. Placing this kind of data, which may only be part of an application’s data, on Flash storage can often have a dramatically positive effect on the performance of an application. However, due to the cost of Flash storage the question is often raised, how can data centers ensure that only data that requires this level of performance resides on SSD or Flash storage so that they can continue to contain costs? Furthermore, is there a way to put only the “hot” parts of the data in the very expensive tier-0 capacity, and leave less hot, and cold data in slower, less expensive capacity? Block based automated storage tiering is the answer to these questions.
Different storage array vendors have approached this problem in different ways. However, in all cases, the object is to place data at a block level, on tier-0 or Flash storage only while that data is actually being accessed, and then to store the rest of the data on lower tiered storage while the data is at rest. Note that this movement must be done at the block level in order to avoid performance issues, and to truly minimize the capacity of the tier-0 storage.
One approach used by several storage vendors is to move blocks of data between multiple tiers of storage via a policy. For example, the policy might dictate that writes always occur to tier-0, and then if that data is not read immediately it is moved to tier-1. Then if the data isn’t read for 3 months that data is then moved to tier-2. The policy might also dictate that if the data is then read from the tier-2 disk then it is placed back on tier-0 in case additional reads are required and the entire process starts all over again. Logically this mechanism provides what enterprises are looking for, minimizing tier-0 storage and placing blocks of data on the lowest-cost storage possible. The challenge with this approach is that the I/O profile of the application needs to be well understood when the policies are developed in order to avoid accessing data from tier-2 storage too frequently and generally moving data up and down the stack too often since this movement is not “free” from a performance perspective. Additionally, EVT has found that for most customers, data rarely needs to spend time in tier-1 (FC or SAS) storage, that most of the data ends up spending most of it’s live on the SATA storage.
Therefore as the cost of Flash storage continues to come down, the need for the SAS or Fiber Channel storage will continue to decline, and eventually disappear leaving just Flash and SATA storage in most arrays.
Another approach that at least one storage vendor is using is to avoid all the policy based movement and to treat the Flash storage as a large read cache. This places the blocks that are most used on tier-0, and leaves the rest on spinning disk. When the fact that the sequential write performance of Flash, SAS/FC, and SATA is similar is taken into consideration along with a controller that orders its random writes, this approach can provide a much more robust way to implement Flash storage. In some cases, it allows an application that would not normally be considered a good candidate for SAS or Fiber Channel storage to be able to utilize SATA disks instead. In general, this technique de-couples spindle count from performance thus providing more subtle advantages as well. For example, applications which has traditionally required very small disk drives so that the spindle could would be might (many, many 146GB FC drives, for example) can now be run on much higher capacity 600GB SAS drives and still provide the same, or better performance.
Overall, automated storage tiering is becoming a de-facto standard in the storage industry. However different storage array vendors have taken very different approaches to the implementation of automated tiering, but in the end the result is uniformly the same. The ability of the enterprise to purchase Flash storage to help improve the performance of their applications while at the same time continuing to bend the cost curve of storage downward.