Matt Simmons comments at Standalone Sysadmin:
At one point in time, I was responsible for a data set that consisted of half a million files, totaling around 2 terabytes of data. This isn’t a lot of data by current standards, but for me, at the time, it was a lot of data. The real problem wasn’t storing it, but managing it. We had a disaster recovery site on the other end of a relatively slow link, and we had to make sure that the data sets were as identical as possible. The way we did this was to rsync across all of the changes every hour. Normally, there wouldn’t be many changes, and it might take 20 minutes. Sometimes, there were so many changes that it took the full hour, and the jobs ran over each other. It wasn’t a very good method of doing what we did.
The funniest part of the whole situation was that even if there were absolutely no changes, the sync still took 15 minutes. 15 minutes to not sync data? How? Well, because in order to know that you shouldn’t sync data, you have to know what the files look like on each side, so basically, rsync inspected the metadata of each set of a half million files on each end, and sent the (compressed) results from one side to the other, then compared the two to see which files should get copied.
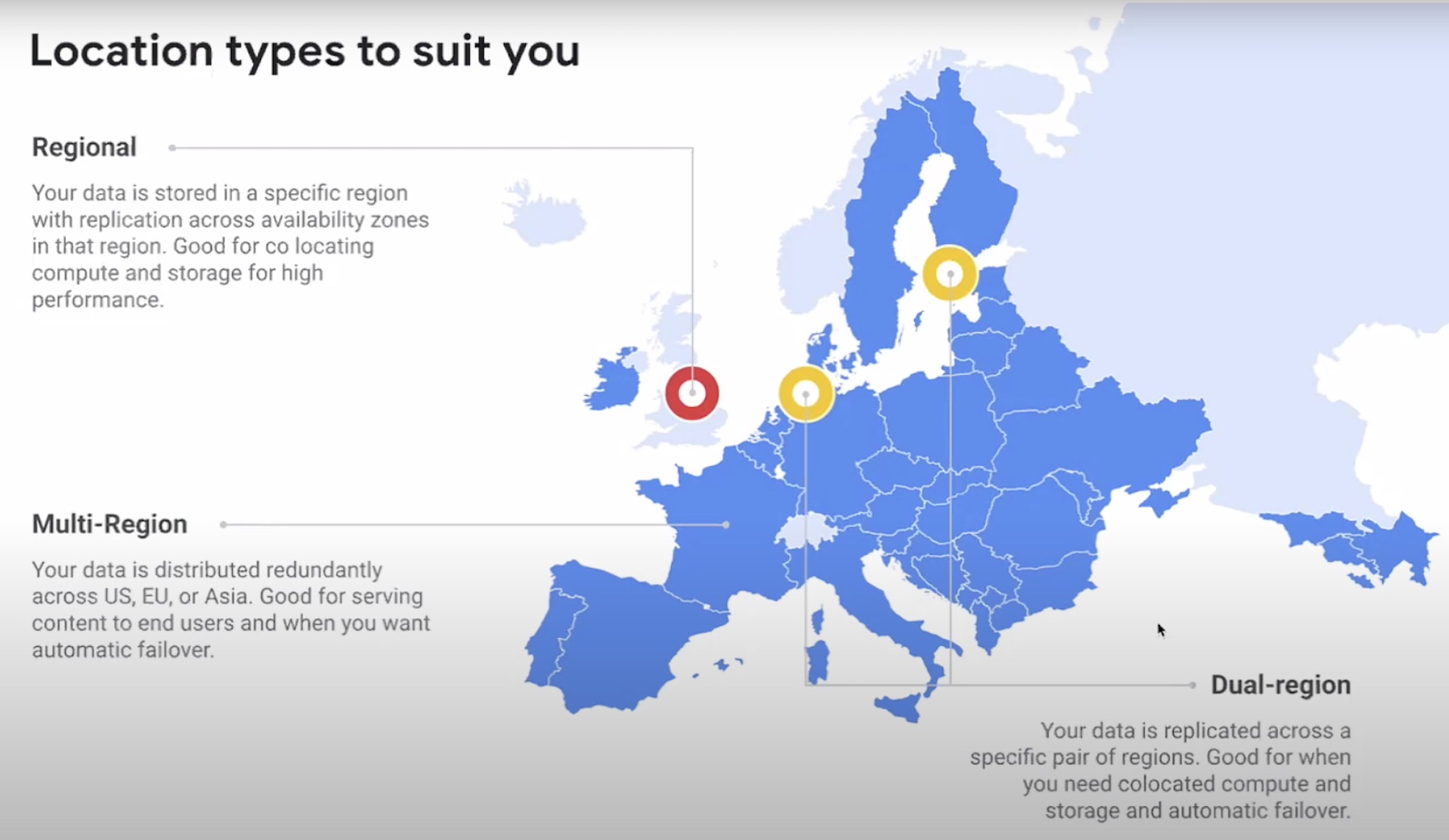
I had this much trouble with a half million files….you’ve got to wonder how companies with actual Big Data problems deal with it. More and more, they’re moving to object-based storage solutions. That’s what Cleversafe is offering, and as you can see in their case studies, there are some really big datasets living on their hardware.
Read more at: Preview of Cleversafe