When Nvidia CEO Jensen Huang announced that the company would produce a CPU alongside the current GPU and DPU silicon, the tech pundits lost their minds. To hear them tell it, the new “Grace” processor would see Nvidia challenging Intel and AMD in the server and the cloud, with Arm finally putting an end to x86 dominance. But these hot takes are way off base and miss the point Nvidia was trying to make. Right down to the name, Grace is about filling the pipes of the company’s ever more powerful GPUs by pairing it with low-latency memory. Nvidia Grace does for the GPU what Bluefield does for the network interface.
DPUs Offload CPUs, Not Replace Them
The crown jewel at Mellanox, which Nvidia acquired last year, was their work on intelligent network interface cards. Now called data processing units or DPUs, these place high-performance processing and memory directly on the network card. Compatible applications can then perform certain operations there instead of bringing data all the way to the CPU and system memory.
The idea of putting chips on a network card to offload certain tasks is not new. We had TCP offload engines in Ethernet cards for iSCSI two decades ago, and most network adapters perform more basic functions independently. But a DPU is way beyond an offload engine, with an entire high-performance computer located on the network card. These run full operating systems, virtual machines, or containers, and can handle many more complex tasks than a simple NIC.
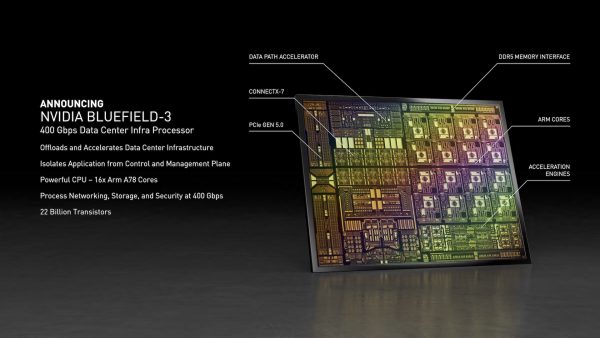
At GTC 2021, Nvidia announced the third generation of their Bluefield DPU. This 400 Gigabit network interface has 16 Arm A78 CPU cores and plenty of DDR5 memory. The DPU can natively run enterprise software like VMware NSX, Fortinet and Guardicore firewalls, and NetApp and Weka storage processing. This frees up CPU resources for production applications.
Latency is the Enemy of Performance
One of the many things Commodore Grace Hopper was known for was her famous story illustrating the length of a nanosecond. The issue then was latency, and how to explain to an admiral how distance impacts performance. Latency is still the ultimate hurdle to performance, and it strangles high-throughput processors like those used in GPUs.
Nvidia knows how to keep their processors busy. They write software libraries after all, and these go hand-in-hand with their famous chips. But no amount of software or hardware can make up for a lack of bandwidth between the data and the processor.

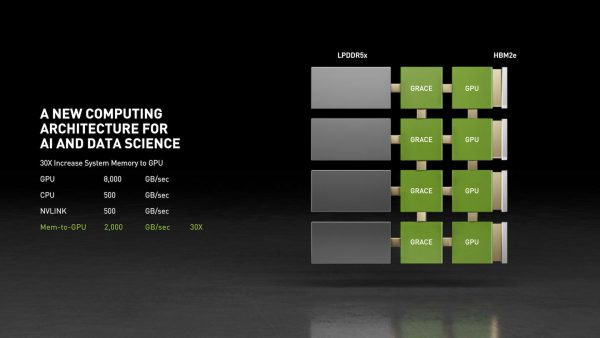
Although PCI Express is fast, it can’t feed data quick enough to satisfy the latest Nvidia Ampere GPUs. Placing a GPU on a PCIe expansion card limits total memory to GPU bandwidth to just 64 GB/s, but native GPU memory can deliver a whopping 8,000 GB/s! This has limited the practical size of machine learning models and thus the questions that can be answered by AI.
Nvidia Grace Is A DPU For The GPU
Now let’s consider Grace, Nvidia’s new CPU platform. Nvidia named this new CPU after Grace Hopper for a reason, and it has everything to do with latency.
On the face of it, one might think Nvidia Grace is a new server architecture based on Arm and NVLink, but this is way off the mark. Instead, think of Grace as an offload engine for the GPU analogous to the way a DPU handles network workloads. Is there really any difference between placing some Arm cores and RAM on a GPU card instead of on a network card? But Grace is also designed to address a critical limitation in modern computer architecture and help extract maximum benefit from Nvidia GPUs.
Grace will use advanced Arm Neoverse CPU cores and LPDDR5x memory to provide general-purpose compute literally next to the next-generation Ampere GPU cores. And these Grace CPUs will have NVLink built in, enabling incredible throughput of over 2,000 GB/s. AI applications will be able to expand beyond the GPU memory without taking the latency hit of a trip across a PCIe bus to main system memory. And Grace cards will be able to interconnect with NVLink just like the GPUs in today’s DGX systems.

Back in 2014, IBM, Nvidia, and Mellanox collaborated on the development of a new supercomputer for the United States Department of Energy. The Summit and Sierra supercomputers used Nvidia’s proprietary NVLink protocol to connect Nvidia’s Tesla GPU to IBM’s POWER9 CPUs, massively improving throughput. And the nodes used Mellanox InfiniBand with state-of-the-art (at the time) offload capabilities.
If this sounds familiar, it should. Nvidia is essentially delivering a supercomputer architecture to the datacenter, with offload engines for the NIC and GPU. Bluefield and Grace reduce the overhead on the server CPU and help move the datacenter to a disaggregated architecture.
Grace and Bluefield in a Disaggregated World
As we discussed in our recent Ice Lake Xeon Scalable Processor review, the enterprise server is on the verge of a massive disruption. Compute Express Link (CXL) enables more flexible connectivity between CPUs, memory, storage, and I/O devices. Thanks to CXL, the servers of 2023 will be more flexible and expandable than ever, enabling rack-scale architecture and special-purpose configuration.
Will Nvidia eventually try to take on Intel and AMD in the server CPU market? It seems likely, especially if the acquisition of Arm goes through. But for now, Grace is all about keeping Nvidia GPUs fed with data, even as AI models expand in terms or memory and compute resources.
Nvidia Grace means that GPUs will have access to general purpose CPU and additional memory regardless of the system interconnect. This future-proofs Nvidia GPU even if CXL, disaggregation, and heterogeneous servers take off. And Bluefield is even more compelling in a disaggregated world.
Imagine a next-generation server CPU from Intel, AMD, or Arm at the center, with CXL links to memory and I/O complexes all around it. Most of these I/O devices will include CPUs and memory of their own, offloading special tasks like network, storage, and machine learning processing. This is the future that Nvidia and the rest of the industry are building.