Mid of August, Broadcom launched its fifth-generation series of Tomahawk switches. Dubbed the world’s fastest Ethernet switch chip, the Tomahawk 5 offers twice the bandwidth of any silicon in the market. At the recent Networking Field Day event in Silicon Valley, Broadcom presented the Tomahawk 5. Pete Del Vecchio, Product Line Manager of the Tomahawk 5 lineup, detailed the features of Tomahawk 5 switch silicon and explained the way it accelerates AI/ML workloads with its tremendous network bandwidth.
InfiniBand, Not the Only Option for HPC Shops
The rivalry between ethernet and InfiniBand is not a new one. Opinions are very divided on the technologies. But the argument that proprietary interconnects are better suited for niches like high performance computing than native ethernet is not a valid one anymore. Several studies have found that when RoCE or RDMA over ethernet is added to ethernet, the performance levels rise to those of InfiniBand or Omni-Path.
In terms of point-to-point latency and bandwidth, IB sure has it’s advantages, but, Del Vecchio explains, “Because there’s such a broad ecosystem around ethernet, you almost always wind up with ethernet having significantly higher bandwidth and higher radix as compared to these more proprietary interconnects like IB and Omni-Path”. In short, performance-wise, ethernet has the edge. But let’s get deeper into that.
Comparing the Performances of Ethernet and IB
To benchmark the performances, Broadcom conducted a test with a leading hyperscaler to compare the results between ethernet and IB for an AI/ML cluster. The test cluster used switches from both InfiniBand and previous generation Tomahawk.
Between a 100Gb ethernet and an optimized InfiniBand network of the same bandwidth, ethernet was found to provide 4% higher throughput for the larger AI/ML message sizes. Even at default setting, and sans optimization, the Tomahawk network demonstrated visibly better performance. Other areas where ethernet aced are port speed, fabric bandwidth, dynamic load balancing and telemetry.
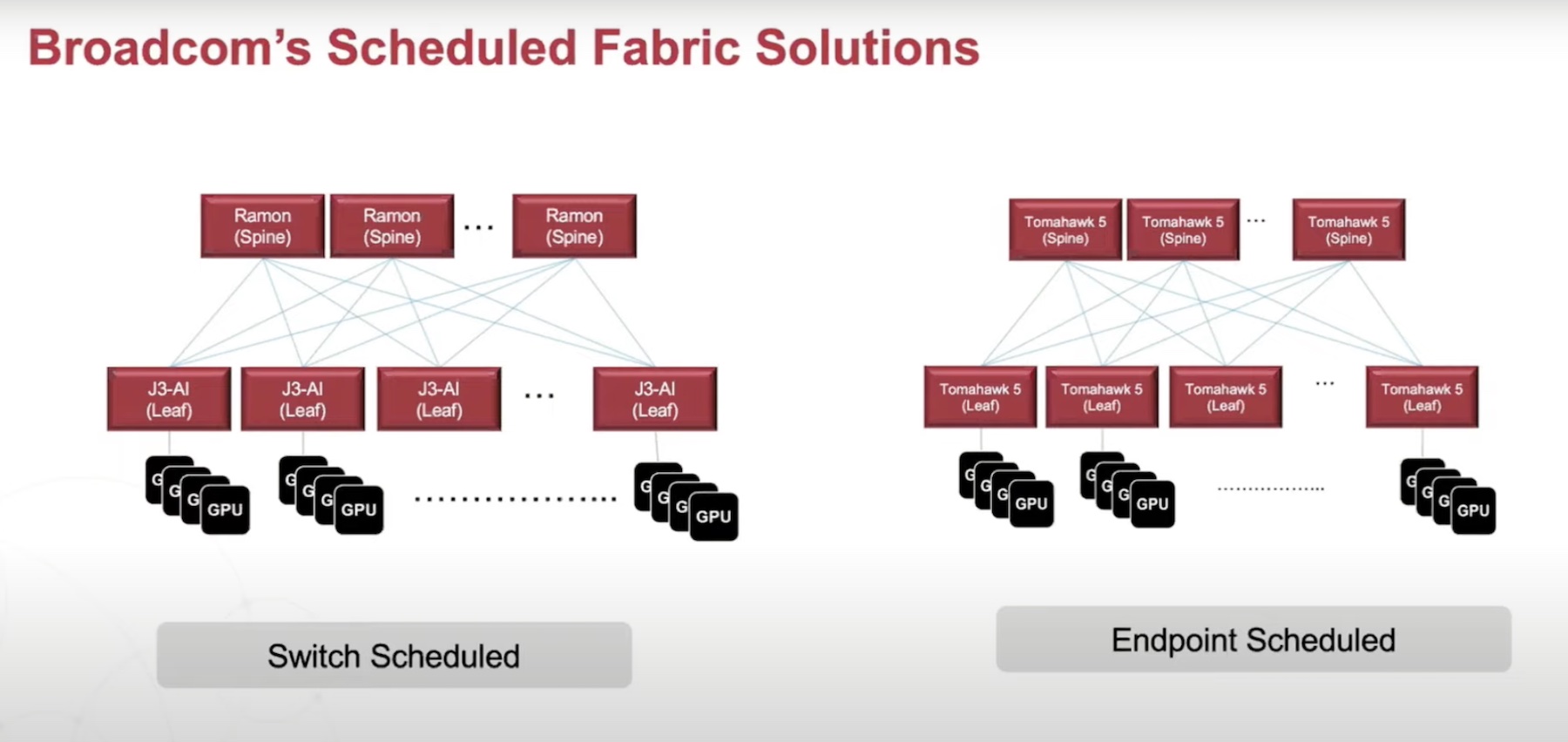
What’s New in Broadcom’s Tomahawk 5
The Tomahawk 5 furthers the legacy of the Broadcom Tomahawk family with extraordinary power and energy-efficiency. Offering double the throughput of all other silicon, the Tomahawk 5 is the world’s first switch to have a bandwidth of 51.2 Tb/s on a single chip.
Implemented as a monolithic 5 nanometer chip, it has ultra-low power consumption of under 1W per 100Gbps, which showed 95% reduced energy consumption than the first-generation Tomahawks launched 8 years back. This is further optimized by its low-power, low-cost physical connectivity via the 100G PAM4 SerDes.
But besides being incredibly powerful and environmentally sustainable, Broadcom’s Tomahawk 5 series is a true enabler of AI/ML computing in the hyperscale cloud environment. Resource virtualization is more secure and efficient with Tomahawk 5. Del Vecchio explains that with features like single pass VxLAN routing and bridging, users can virtualize workloads of both general compute and HPC kinds.
A Rundown of Tomahawk 5’s Best Features for AI/ML Applications
At the Networking Field Day event, Del Vecchio showcased Broadcom Tomahawk 5’s features for AI/ML. Beginning with a rundown of its most advanced feature set, he explained how Tomahawk 5 supplies firepower for AI/ML processing.
One of the top features that Del Vecchio touched on in the context of AI/ML acceleration is cognitive routing. An umbrella name for a set of capabilities, the work of Cognitive Routing is to maximize network link utilization. It is an automated function that dynamically selects the links that are least lightly loaded for each flow passing through, making sure that all links are fully utilized.
Advanced queueing and buffering enables 10 times better packet burst absorption compared to Slicer Buffer and similar architectures. This helps make sure that packet drops are minimal and job completion time is short.
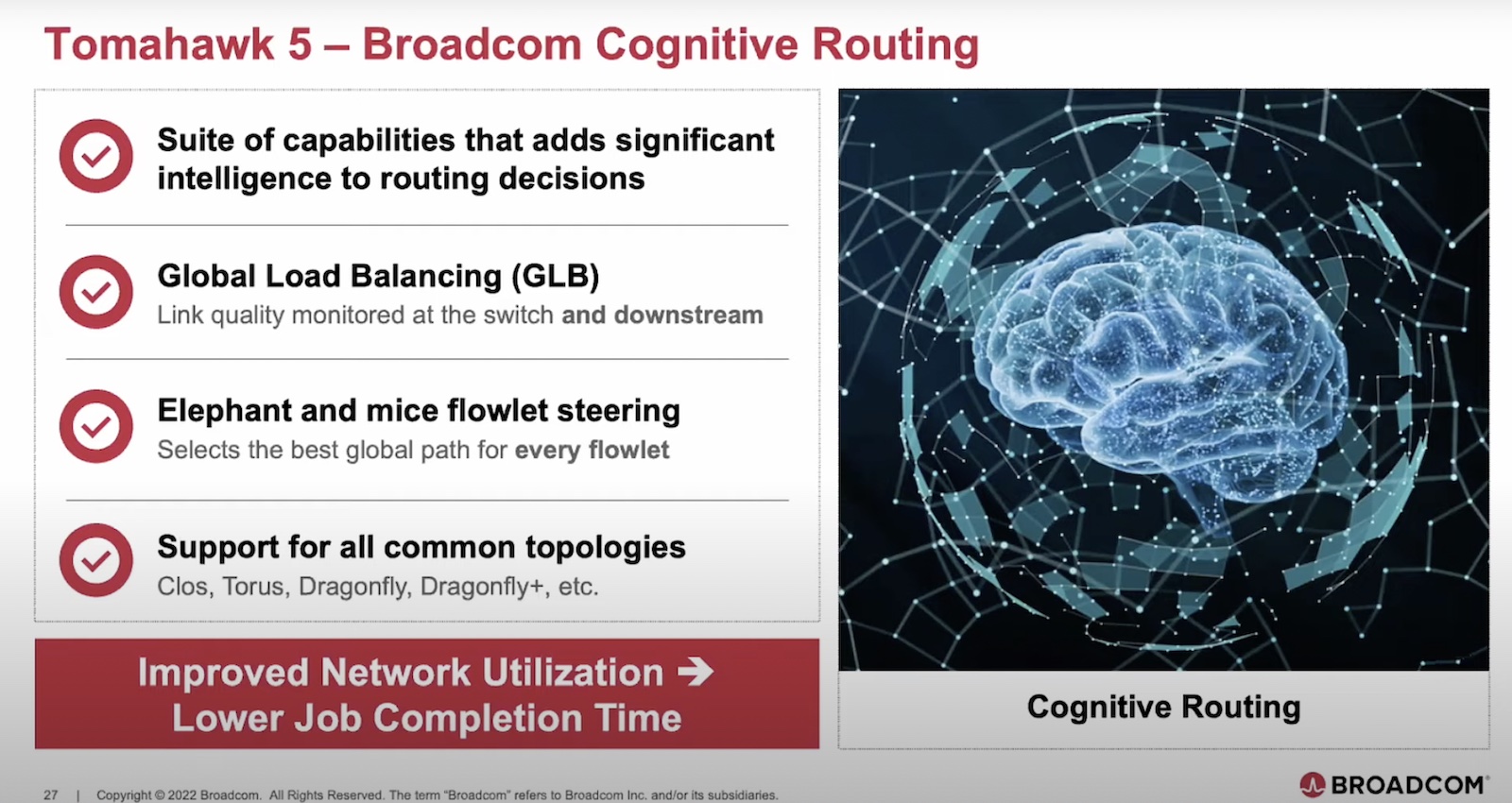
Flexible in-band and out-of-band telemetry help minimize packet drops and subsequently reduce latency jitters, and overall offer good congestion control, end to end. With 6 ARM cores onboard in one die, Tomahawk 5 provides programmable out-of-band telemetry that can be used for summarizing and packetizing statistics and passing them on to the collector. Inband telemetry allows insertion of metadata into packets including line-rate live traffic and network probes.
High precision time synchronization ensures seamless job synchronization and higher congestion control.
Tomahawk 5 offers ultra-fast link failover by detecting a hard failover under 500 ns and redirecting the traffic to a different link. This is again very helpful for smooth communication between jobs, critical for AI/ML processes.
Wrapping up
With Tomahawk 5, Broadcom brings its A game to switch silicon. Just the breakthrough power economics itself is enough to spur a wide adoption of this series in datacenters. But its true power is in its extraordinary high bandwidth and low tail latency which make ethernet the fabric of choice for network-intensive applications. Tomahawk 5 with its suite of capabilities brings unprecedented performance to HPC applications, while truncating job completion times and achieving better load balancing and higher network utilization. With Tomahawk 5, Broadcom makes the network infrastructure whole again with ethernet, eliminating the need for a separate scale-out network for AI/ML tasks.
For more information, check out Broadcom’s other presentations on Tomahawk 5 from the recent Networking Field Day event.