Context-rich visibility of platforms is critical to stronger security posture and decreased data vulnerability. As vast data sets are assembled and analyzed daily, businesses require more storage space to retain that data. Built with Splunk and Apache Kafka at its base, the Intel’s Cyber Intelligence Platform itself ingests and analyzes 30 TB of security data every day. Intel, at the recent Storage Field Day event in March, presented a Proof of Concept from a test ran by integrating Splunk with VAST Data Universal Storage to understand how the rising storage needs can be met effectively so that Splunk can be used seamlessly with converged infrastructures. The test results were startling.
Data Storage Equals Cost
Splunk Enterprise has by and large solved the problem of underutilized data in businesses. By accumulating data from different sources and transforming them into actionable intelligence, it has helped close the gap in awareness which loomed large in organizations unable to integrate and utilize dark data. While the insights made way for new and interesting business opportunities, it gave birth to a couple key challenges.
With traditional converged infrastructures, compute and storage are interlocked. One cannot be scaled without the other, irrespective of whether there’s a need. This is more than just a problem of independent scalability. With large systems involved, the resulting cost spike is simply too much to handle. In the end, it boils down to the fact that storing large amounts of data, although imperative, is expensive.
Intel Modernizing Storage for Splunk Platforms
Intel realized that the way to work around these drawbacks is to use a high-capacity storage that shrinks data size substantially while supporting Splunk’s performance. So, they took at stab at modernizing CIP 2.0 with the goal of making it better, faster and ultimately cheaper. How?
The answer was staring right in the face- by leveraging Intel Optane Memory. Utilizing Optane Memory technology that provides innovative data caching with an LRU (least recently used) strategy, Optane SSDs enable super-fast access that SSDs are known for, but with the high capacity of HDDs. Separating hot data from cold data, Optane Memory saves the commonly used data sets in the fast cache while offloading less used data onto the slower HDD.
Capacity Optimization with Intel Optane Memory
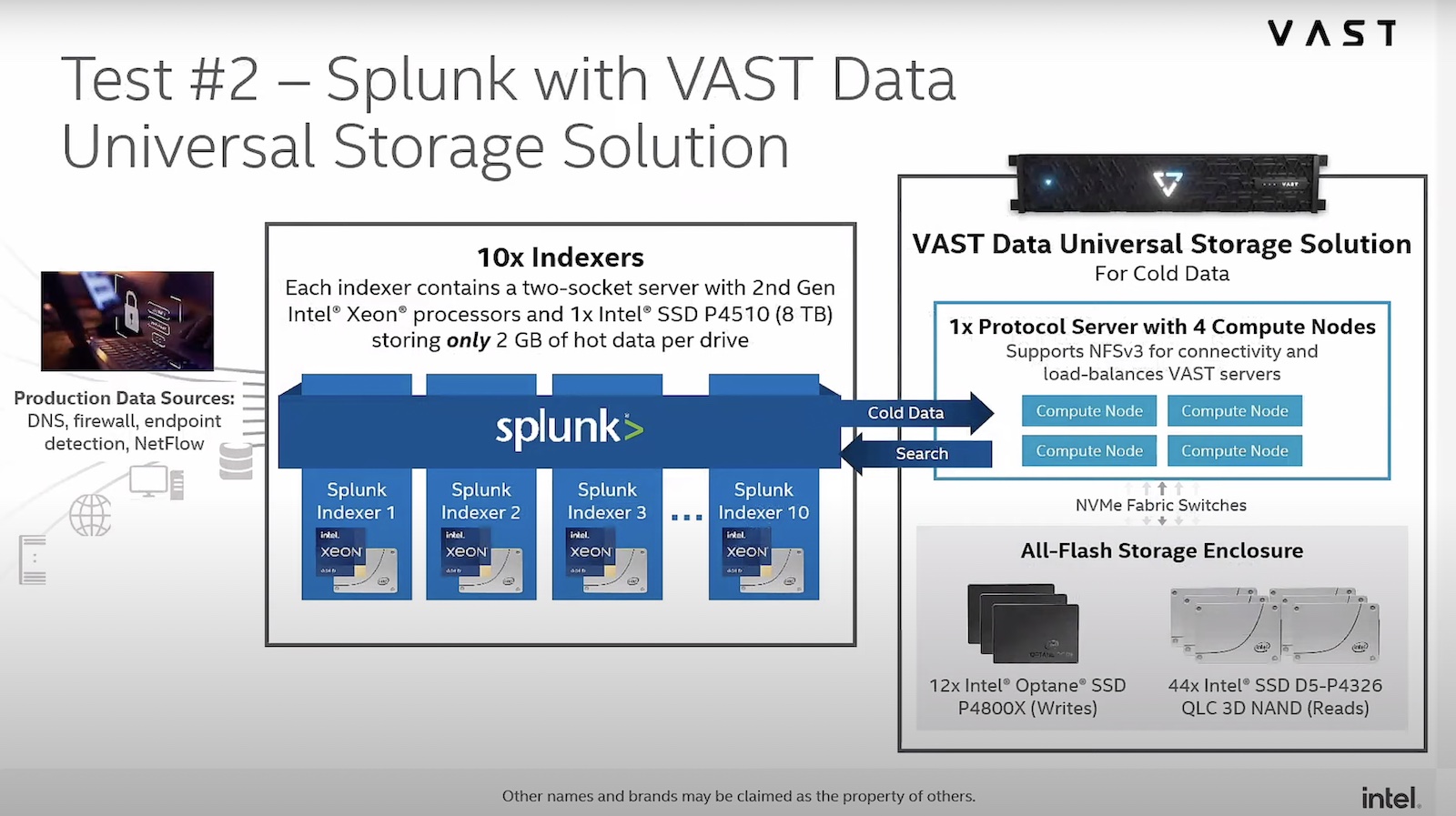
At the recent Storage Field Day event, Victor Colvard, Information Security Engineer at Intel IT presented a PoC which the teams at Intel built after testing Splunk with VAST Data Universal Storage. With the use of VAST Data Universal Storage which uses Intel Optane SSDs, they were able to decouple compute from storage, with some very surprising results.
Powered with Intel’s low-cost QLC NAND SSDs and Intel Optane SSDs, VAST Data Universal Storage is a fabric that is purpose-built to store data at petabyte scale. Through VAST Data’s advanced data reduction algorithms, and Optane Memory, Intel was able to achieve a 2.5x reduction in Splunk data at little to no impact on data ingestion rates and search run time. This significantly reduces capacity requirements for cold data.
The VAST Data fabric also enables disaggregation of compute and storage which makes independent scaling of either and both possible, resulting in reduced costs. In terms of performance too, there’s no sacrifice of search run time and data ingestion rate. Intel Optane SSDs can simultaneously maintain the normal Splunk performance.
That’s not all. With space worth petabytes of data freed up in data center racks, operational efficiency is likely to improve too.
Final Verdict
Intel seems to have found a way to minimize platform costs through disaggregation of storage and compute for Splunk users, something that has been a huge roadblock on the face of surging data. This will change the way organizations leverage Splunk for data intelligence in a major way.
Be sure to check out Intel’s other presentations from the recent Storage Field Day to learn more about Intel Optane Persistent Memory.



