As a student, I used a number of PCs that weren’t exactly state of the art. In 2007, I was using a glacially clocked Pentium 3 based machine with 128 tiny MB of memory. As such, I didn’t so much become familiar with a swap file, as I lived within its glacially slow confines perpetually. I ended up getting the system semi-functional by installing Puppy Linux and running everything in buttery sweet RAM. Since that time, I’ve always held RAM as the gold standard of speed and efficiency. What could better? Well, after seeing what Diablo Technologies is doing, I’ve changed my tune.
Diablo Technologies doesn’t think RAM is bad. Quite the opposite, they think we don’t have access to enough of it. As everyone from the Fortune 500 enterprise to Hyperscale corporations turn increasingly to Big Data, RAM is at a premium. Diablo’s solution to this is called Memory1. This takes abundant flash storage and make it byte addressable. With this, they are able to provide 128GB DDR4 flash memory DIMMs, with the implication being that a standard dual-socket x86 server now has system memory in the terabyte range.

Reflective surface not required
So they just slap some flash in a DIMM and call it a day? That seems like a solution with no end of compromises with no real benefit other than a capacity claim. My first reaction was that this was clever, but if that could work, why didn’t someone do that before?
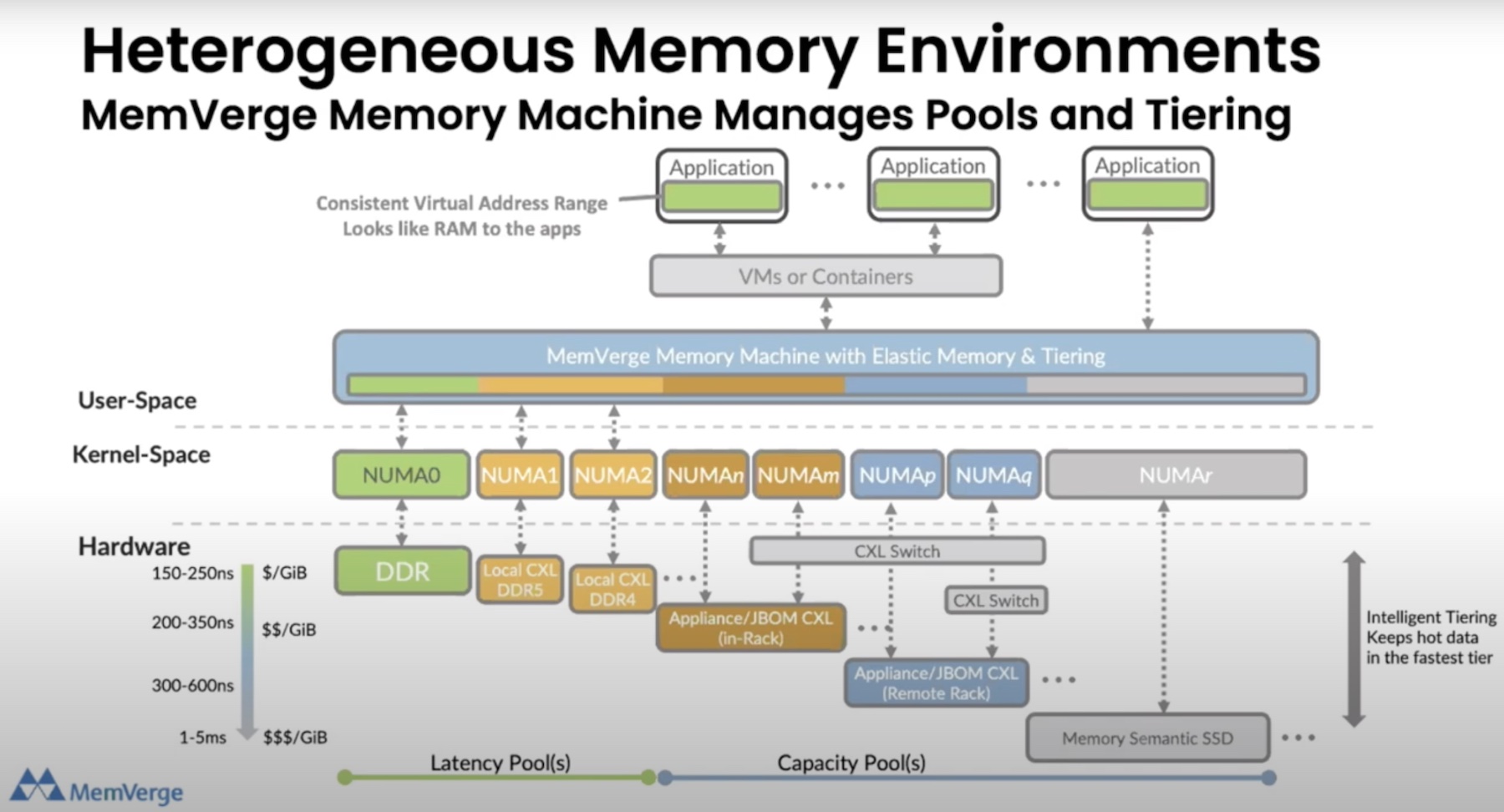
Well, because as a blunt force tool, it wouldn’t work. That’s why Diablo has engineered a system to leverage the speed of DRAM to access the flash storage. The secret sauce is called the Diablo Memory Expansion, correctly abbreviated as DMX. I’ve prepared a highly technical diagram of how the system works below.

Diablo Technologies: Inconceivable Memory
The first thing to understand about Memory1, you’re never using just flash for memory. This would be terribly inefficient, even given the exta capacity. Instead, every memory controller has DRAM upfront, flash in the back. It’s a memory mullet.
The design is setup to have as many reads and writes handled in DRAM as possible. The entire setup runs of standard DDR4 DIMMS. The way this is setup is key. DDR4 can handle a ton of speed, which NAND-flash just can’t match. I was concerned that this would waste some of the bandwidth, and you wouldn’t see this approach scale very well as the enterprise moved on to DDR5 and beyond. But one of the advantages of using the DRAM up front is that it can saturate this bandwidth, leaving none to waste on the slower medium.
That is not to say the NAND-flash is idle. It’s fully byte addressable and put to good use. When I first saw an overview of their memory solution, I was a little concerned they might be using the DRAM as a simple cache for the larger flash capacity. Perhaps just keeping hot data on the DRAM and moving everything else to the slower medium. This would be fairly simple.

But Diablo instead developed DMX. DMX is the brains behind the whole setup. It installs within the OS, akin to a driver, but really more of an active memory management layer. This allows it to monitor all memory transactions. Instead of a simple hot/cold data model, DMX is much more sophisticated. It algorithmically determines how data is tiered on a number of factors, from associated data whenever an application is opened, to configurable quality of service guidelines that users can setup. Diablo is implementing even more robust QoS provisioning going forward. Right now users have to dig into the configuration files, but I was told a more user-friendly is in development. This could be huge for organizations that are worried about providing for their own SLAs, if they can guarantee that data associated with it is always ready to go in the fast DRAM.
The other benefit of DMX is that this is all opaque to the application. As far as the system knows, it just has a huge amount of addressable storage to work with. DMX handles all the dirty work to make sure the read and writes are done on DRAM, then transferred off to NAND-flash intelligently. This transfer also improves over time, as the memory management has a learning engine built in, allowing for dynamic application profiles that constantly are optimized for given conditions. This includes active prediction and pre-fetch provisioning, all within whatever QoS parameters setup within the system.
DMX is also essential for maintain the endurance of the NAND-flash long term. DRAM doesn’t have to worry about the under of writes to a given sector, but flash does. DMX has a number of features to limit this. In databases, DMX will perform dirty page writes. So instead of a database updating the same region a ton of times, DMX is smart enough to keep those writes in DRAM, only moving them over to the flash memory when everything is done. It also does sequential writes on the flash, which helps makes sure certain sectors aren’t hit as much in the overall array.
So what are the implications have having all of this available memory? Like I said at the beginning, this is aimed at Big Data applications. One of the benefits is that entire temporary datasets can often be put entirely in memory, which Diablo shows being 50% faster than using NVMe storage in something like Apache Spark.

Other than time, Memory1 allows for higher density computing. In a case study with a financial services firm, they saw 3 Memory1 nodes working 24% faster than 12DRAM nodes on SQL queries. This could allow for substantial consolidation with the data center.
As far as how you can get Memory1 into your data center, they have offerings from both Inspur and Supermicro, with other suppliers in negotiations. These 1 and 2U servers are dual socket and can offer 1-2 TB of Memory1.
The unique needs of Big Data are causing some interesting stirs in the hardware market. In the past few months, I’ve seen some storage companies (like DriveScale) move to disaggregated solutions, to allow organizations to add a ton of storage regardless of compute needs. Diablo’s Memory1 seems like another solution to the same Big Data problems. While you’re not going to be able to disaggregate memory from a server, Memory1 allows you to achieve a density within a single server that previously was unfeasible. This ability to add scale, density and efficiency makes for a killer combo with Big Data applications.
Disclaimer: Rich would like the reader to know that the lack of references to DMX the rapper were intentional in the piece. Let’s all be adults here.