Robin Systems does not mess around when it comes to the scope of their mission. Some companies set out to be iterative. They want to create something a little faster, a little more efficient, or a little easier to use. Robin Systems aims to reinvent infrastructure for modern distributed applications. It’s a company mission that certainly doesn’t lack for ambition.
The Problem of Modern Data Platforms
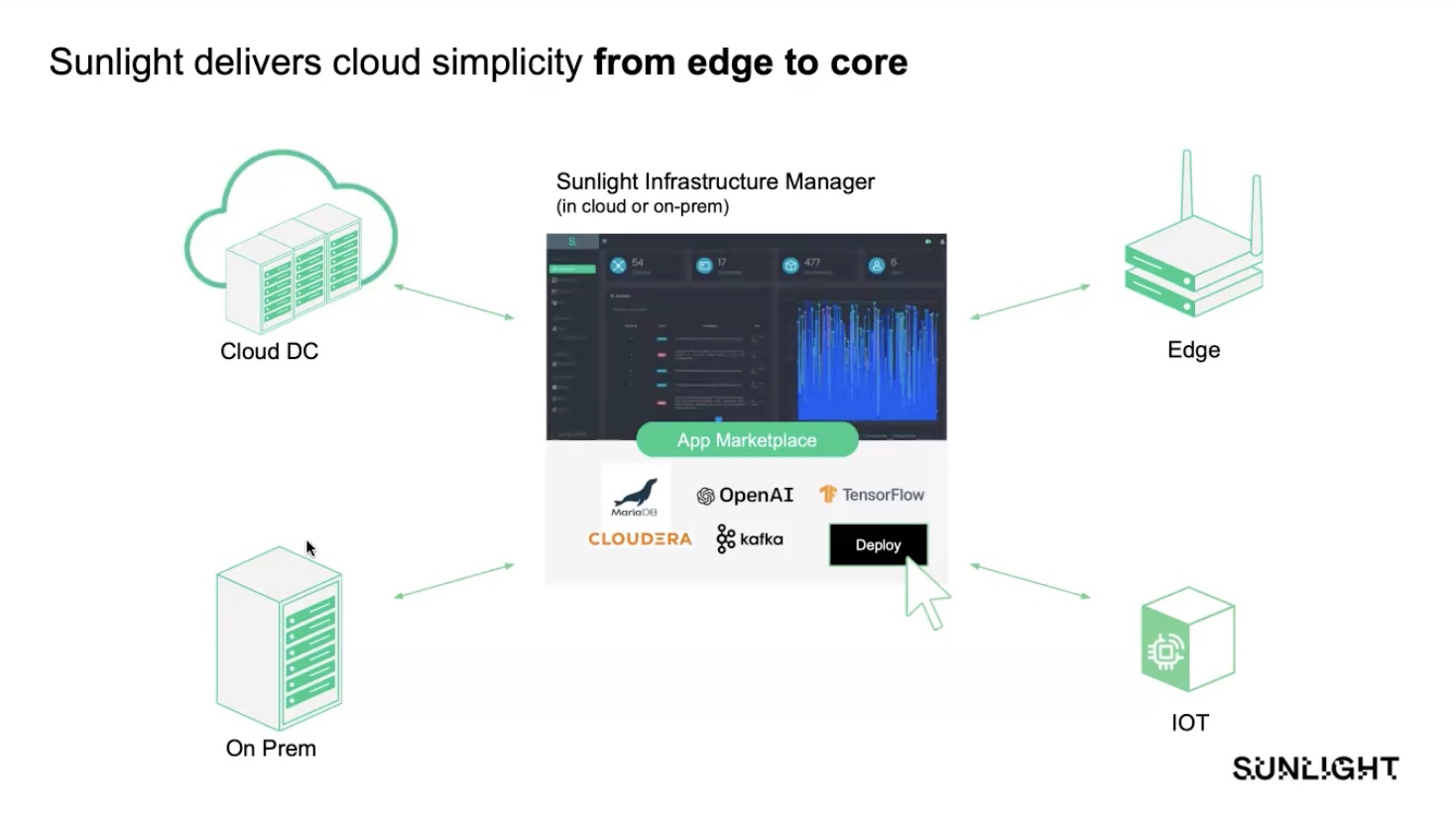
The company wants to embrace the benefits of modern data platforms, but sees them having a number of pitfalls that either impede adoption, or limit their usefulness. These distributed clusters gender tend to require a large amount of hardware CapEx, largely as a result of data duplication as clusters get larger. Because these systems are also designed to run on commodity hardware, they also tend to lack enterprise reliability on a hardware level. Robin Systems thinks they can solve these issues. On principal, they envision their solution to be elastic, easy to manage and includes comprehensive support for big data applications. They call this an application-defined infrastructure.
They are a pure software play, installed on commodity hardware, simply installed on a Linux box. Their solution reviews the resources available, and from that defines discreet application-defined compute and storage planes, essentially aggregating compute and storage resources across nodes. On top of this, apps are deployed in container, with both Docker and LXC apps supported.
Strong Enough for Containers, Made for Applications
But Robin didn’t design their solution to be used as a container management or orchestration platform. Instead, everything is designed around the context of the application. Containers simplify some of the management aspects, but it’s a piece in service of application management, rather than containers managed as an end product itself.
The end result of this approach is allowing applications to not be held up by layers of infrastructure dependency, but instead to built in hooks and tools so that the infrastructure has an “awareness” of the needs of the app. Robin Systems designed their solution so that application needs can be described with simple rules in a YAML file, which they call an application manifest. This would tie into programmable primitives, essentially programmable infrastructure elements used for lifecycle management.
At it’s base, the application manifest is the backbone that will be largely exposed to users of Robin Systems. On a basic level, the YAML file includes directions that define the app for the infrastructure. This includes the services that underlie the application, the container image to invoke it, the basic hardware needs (include QoS considerations), configuration considerations for the containers, and the start stop conditions for the application as a whole. It’s a really interesting concept to make this all human readable and clearly rule defined, without having to know the backend infrastructure details.
Once this is done, the Robin System’s dashboard gives you push button options to launch application. There is a basic provisioning screen where you can specify cores needed or IOPS limits and thresholds. But from there, the actual provisioning and application work on the infrastructure is automated. The compute and storage planes control how resources are distributed, and are directed by the application manifest in terms of what else to launch and provision.
Robin Systems seems to be a happy medium between old models of slowly deploying applications and other solutions that seek complete automation. In terms of usability, the application manifest is a brilliant idea, not simply in terms of how it works into their overall solution, but because it gives a single source that administrators can use as the basis for application definition. The relatively simple structure means it’s easily configured by IT and ingested into the greater automation scheme. It’s an interesting approach to simplifying a lot of the pain points for modern application deployment.
Check out their presentation at Tech Field Day for an architectural deep dive.



[…] Robin Systems Defines Applications […]