In the world of technology, ideas develop on a dime, and each breakthrough takes us closer to digital perfection. But unexpectedly, exploring too many options can give an organization its Achilles heel.
Storage is an area that sees relentless product advancements and technology breakthroughs. Over time, companies wind up with a mixed stack, which becomes the source of all problems.
One company that is taking the lead on solving this pervasive problem is StorPool. We met with Alex Ivanov, Product Lead, and Boyan Krosnov, CTO, on the eve of their release of the StorPool v21, to talk about the current state of storage, and learn what StorPool is bringing to the table with the latest version.
A Bizzare Mishmash
StorPool was born of frustration when data storage challenges peaked amid an explosion of innovation.
A complete storage solution remains elusive despite all tech advancements. Companies, depending on their size of IT budget, have adopted miscellaneous strategies to get around this.
Many have opted for a multi-vendor infrastructure by adding products from different vendors. Buying solutions based on price-to-performance ratio gets them the best deals, and access to multiple storage tiers that make the best fit for their datasets.
But this ends up in a solution mishmash. Layering disparate products has some serious fallouts. For one, too many products make the system complex. Each individual solution creates an islands, or as insiders call them, “silos”. These silos with their unique characteristics and learning curves are not just hard to work with, but when it comes to scaling, they need to be expanded individually by procuring products from their respective makers.
One way companies approach this situation is by seeking IT support. IT support provides the care and feeding required to navigate complex systems. But that leads to a web of its own. “It is very difficult for companies that have many different competing needs and workloads to get a single vendor that has the ability to support all their workloads and IT stacks,” explained Ivanov.
With limited deployment options and protocol support of vendors, the choice between a hyperconverged solution and stand-alone products is no choice at all, he reminds.
In monetary terms, all these have an eye-watering cost. “As a result of everything taken together, companies end up with a suboptimal datacenter cost structure. As there are silos, you end up optimizing each piece of the IT stack, and resultantly, the whole datacenter ends up costing more for the company operating it.”
A Silver Bullet
A way out is through using a fully managed solution that assimilates the best features of these disparate products. StorPool’s storage solution is inspired by this. The platform ticks all the boxes making it one of the few solutions out there that is complete and holistic.
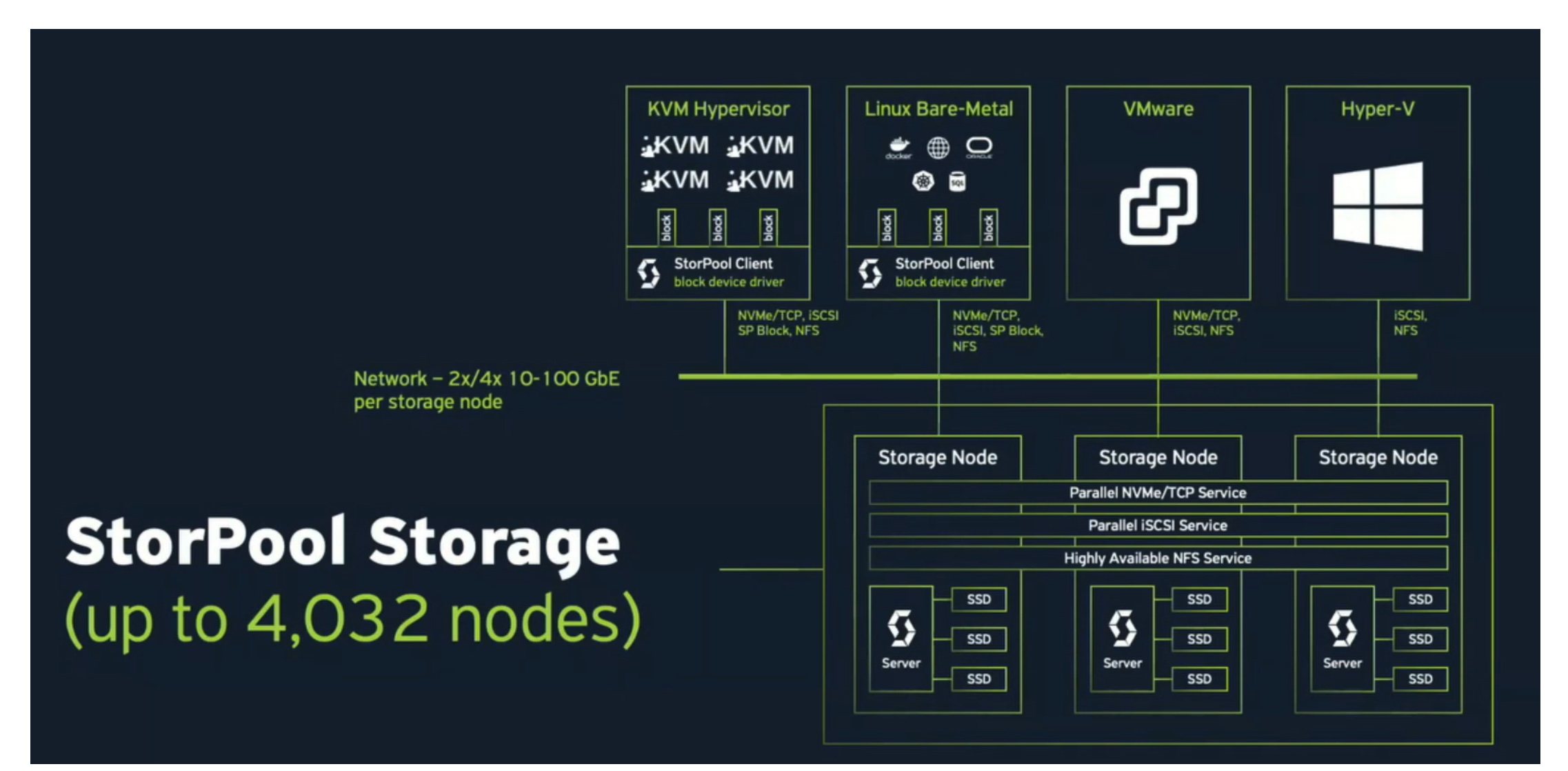
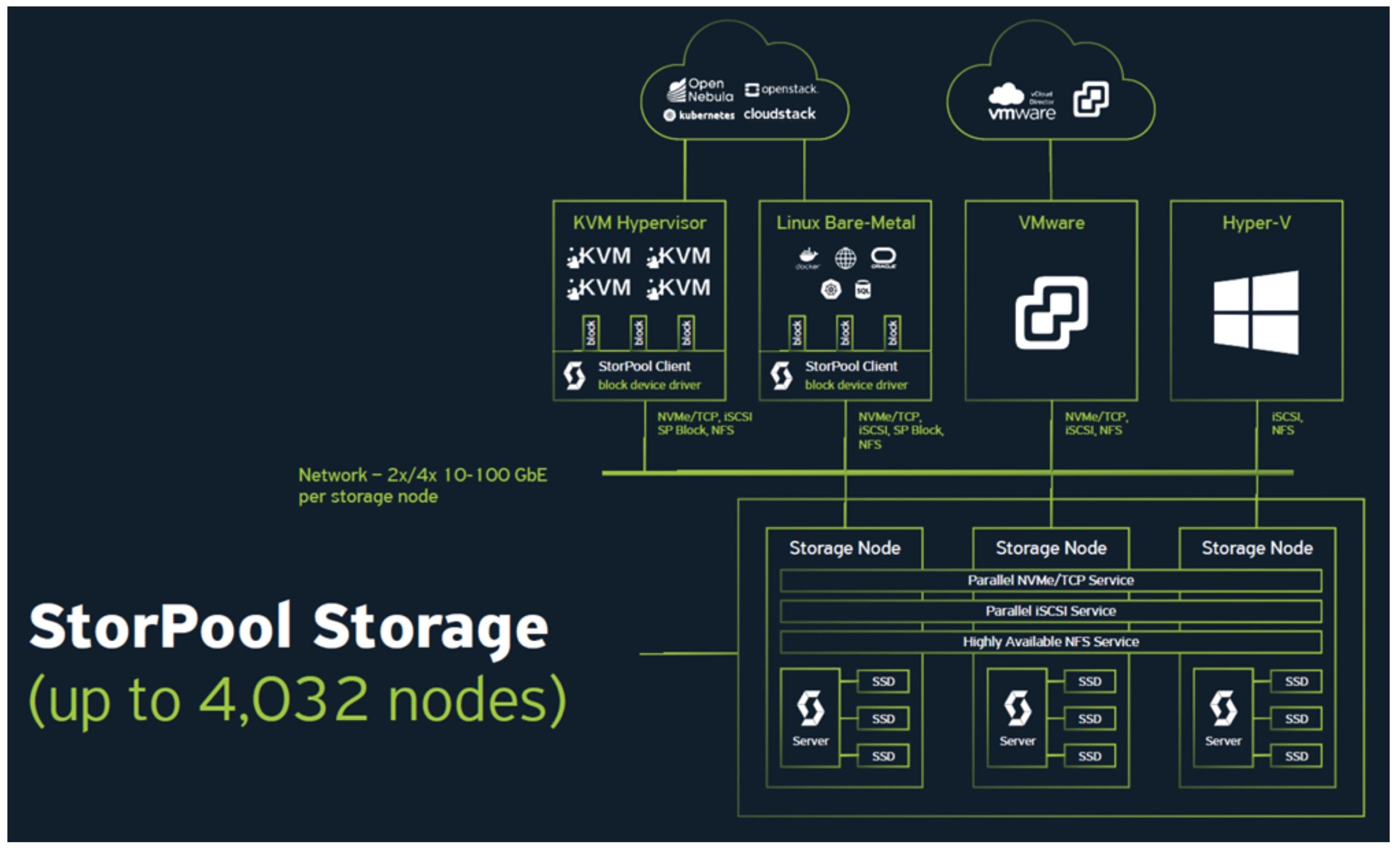
It is a high-performance, linearly scalable block storage software platform. “The product is delivered as a service, meaning that everything we do is fully managed for our customers,” said Ivanov.
Production-proven and hardened since launch in 2012, it is fully hardware-agnostic, and comes with key features built-in like DR and backup that are normally sold as separate solutions. Think of it as storage on rent, where each system is managed by the vendor’s internal team from design to deployment, monitoring to maintenance.
“Since StorPool is delivered as a service, we especially take out a lot of the staff costs that would typically be associated with storage. Companies get to repurpose that for other functions, for the teams to grow, for different projects that aim to grow the business of the company,” he said.
This storage system can be connected to all cloud platforms making it the central repository for all the data.
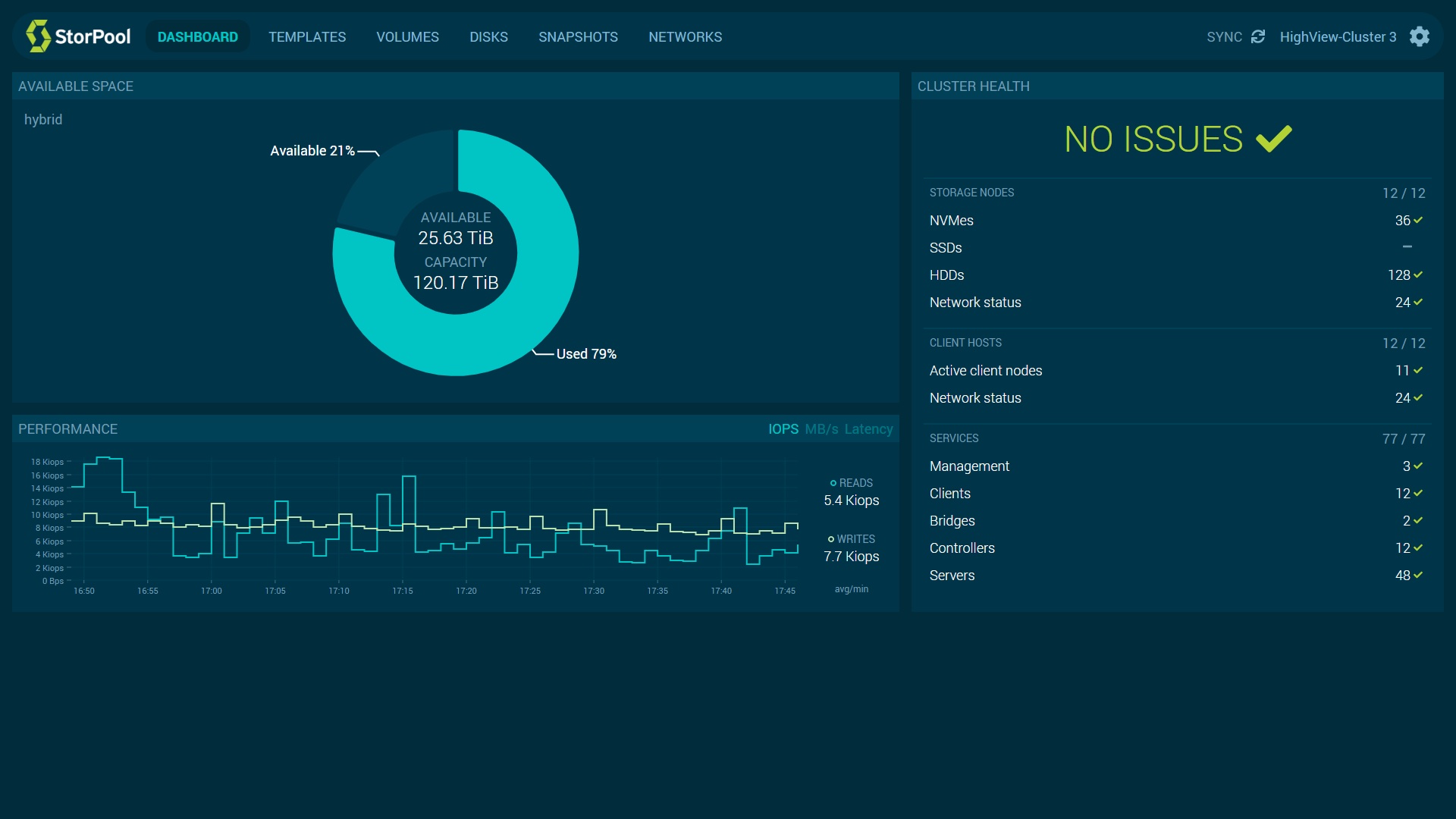
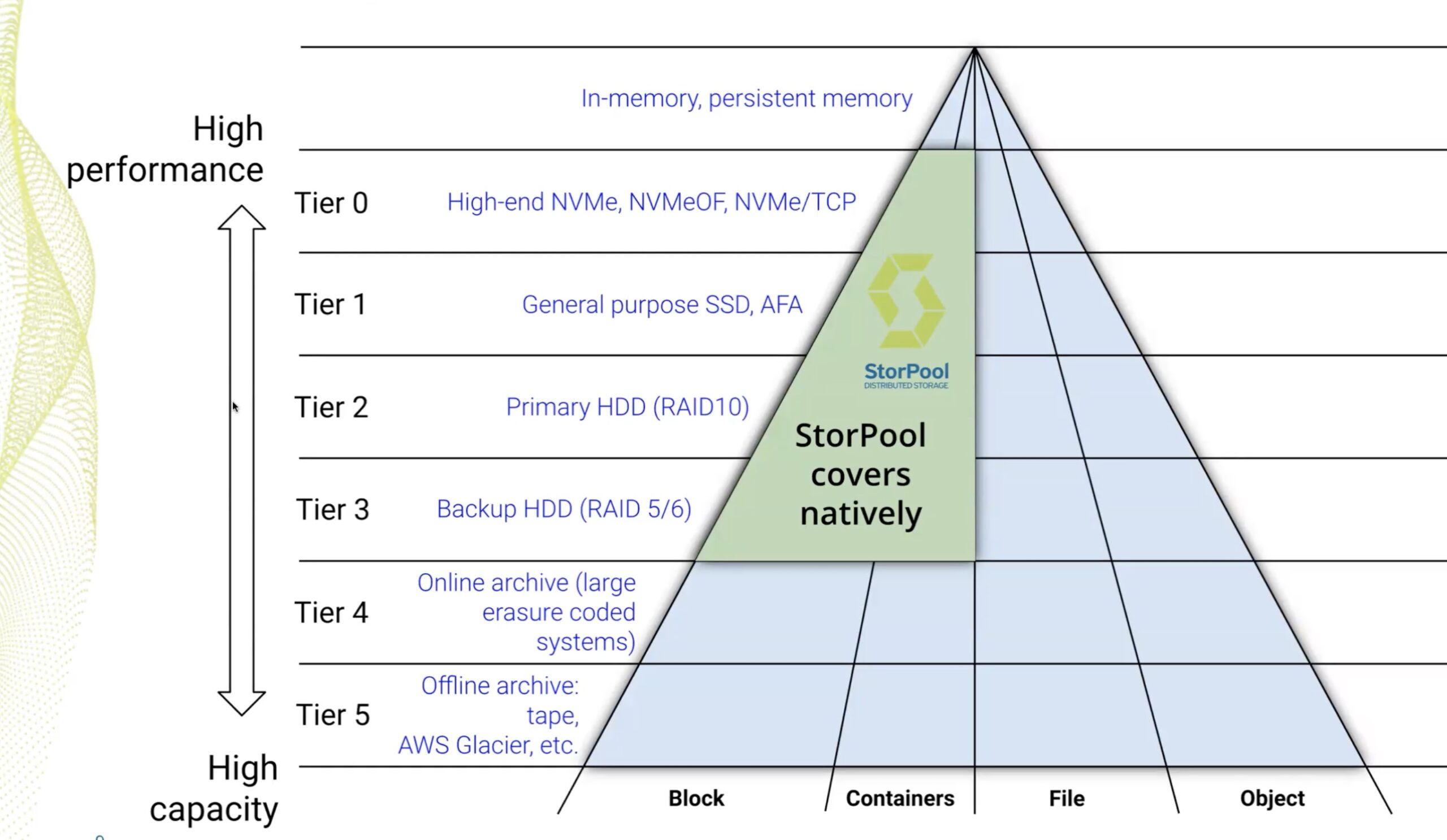
StorPool’s storage platform covers tier 0 which is NVMe to tier 3 which is backup, and can be scaled without limit. From 10 TB to 50+ PB, capacity can be added as required within one system. StorPool also offers support for VMware, K8s, Apache CloudStack, OpenStack, Proxmox, as well as workloads running on transactional databases like Oracle or MySQL. Additionally, it is multi-protocol.
StorPool offers built-in data backup with a service called VolumeCare that backs up data to secondary local and remote systems. “With triple VolumeCare service, we can actually perform backups for user data in the storage system and transport them efficiently to local or remote storage solutions serving secondary purposes,” he informed.
Enhancements in StorPool v21
Continuing on its mission to build a “better world through faster storage”, this week, StorPool launched the 21st iteration of the platform. Like each time, this new version brings a set of vital capabilities taking the platform to the next level.
v21’s highlights are around data protection. It introduces more features around Erasure Coding. Erasure Coding is a method of data protection used to prevent data loss. Data is broken up into chunks, expanded and encoded with redundant data. This is then stored across different storage systems in multiple locations. When a drive fails or the data in it becomes corrupted, it can be redeemed from the datasets stored in other drives.
However, erasure coding across storage nodes is slow, and it is difficult to have that always-on protection. The new version provides workarounds with what StorPool calls “magic scale-out Erasure Coding”. It offers near-zero performance impact for tier 0 and tier 1 workloads, meaning the implementation will have no impact on the performance, and StorPool says, that it can even be used for the most demanding workloads.

As data comes through, it is triplicated, and batch-encoded after an hour through a background process. This reduces data processing eliminating the impact on latency for user I/O operations.
Per-volume policy management allows data to be protected by volume as opposed to per-drive or per-node. Cross-node data protection ensures that data across servers is safe and accessible through failure of up to two nodes.
StorPool offers incremental mesh encoding and recovery wherein it only recovers what is lost as opposed to all of the data in the node. “If a storage node dies and you bring it back, it will recover only the differences. And with mesh recovery, if a node dies and it’s never coming back, we can recover on the remaining storage nodes,” said Boyan Krosnov.
The v21 offers an always-on operational model by letting up to two nodes to be taken offline for maintenance, without disrupting the rest of system or data accessibility. “Conversion between different schemes, expansions, software updates, drive failures – everything is online,” he highlights.
To learn what other enhancements the new StorPool v21 packs, check out StorPool’s website. Catch more on the story on the Rundown that covers this in detail, or watch their presentations from the recent Storage Field Day event to know all about their product. For more stories like this one, keep reading here at GestaltIT.com.