Recently, I had the opportunity to talk with enterprise storage vendor StorPool at Storage Field Day 25. Their approach is a refreshing departure from that of traditional storage vendors, and what StorPool likes to call “the storage game.”
The Invisible Girders for Modern Computing
Modern IT systems combine compute, networking, and storage into a complex cornucopia, addressing myriad application needs. The storage side of that conglomeration is often the trickiest bit.
Relational databases typically require huge amounts of block storage. NoSQL databases use both file and object storage for JSON documents. All of this data needs to be protected through redundant copies within the storage environment, not to mention clone them rapidly and consistently for testing, and backup and recovery of crucial systems.
Storage must be performant to support different application workloads – data lakehouses supporting data scientists, intense workloads carrying customer transactions, you name it. And as far as DBAs and DevOps people are concerned, storage should always be available and invisible, like the girders hidden within the walls of a modern skyscraper.
StorPool
StorPool is based out of Sofia, Bulgaria, a place once considered the Silicon Valley, early post-USSR. Their resulting orientation of storage systems flows from the expediency of those years. StorPool believes it gave them a view of storage completely different from the typical storage environments of the past.
Interestingly, StorPool targets a different market sector – the service providers themselves. Several key customers include Atos, Namecheap, and Nasdaq Dubai, who provide services for critical government and fintech companies as varied as NASA, ESA, and Deutsche Borse Group.
Always There, Always On
According to StorPool, an ideal primary storage platform is one that covers an enormous range of requirements. First, it should use commodity servers that are available at reasonable pricing, and are easily replaceable. It also means that the servers fit just about any datacenter fabric design in the real world, and can leverage as close to 100% of the hardware’s capabilities. It must also handle the extreme demands of modern applications – both high IOPS for transactional workloads, and significant MBPS for read-mostly data lakes – by providing high-speed data transfers.
Ideally, it would just be “there”. In insider terms, it would have the gold-standard five-nines availability. Furthermore, it would scale regardless of whatever the customer needs are. Most importantly, it should be simple to use.
From a provisioning perspective, StorPool is essentially software-only, and therefore hardware-agnostic. Practically any recent enterprise IT setup can leverage it, as it likely has compatible underlying compute and networking components.
StorPool designed it as a massively parallel, multi-node system with shared-nothing architecture, and multiple redundancy. Essentially, it is “always on” and requires no downtime for upgrades or expansion.
What Differentiates StorPool’s Storage Platform
The long-standing “building block” model for typical storage platforms eventually becomes non-performant, usually at the worst time in the business cycle. This follows a major fire drill to solve the underlying problem, which could be anything between unexpected storage capacity failure, to compromised, or aging hardware components.
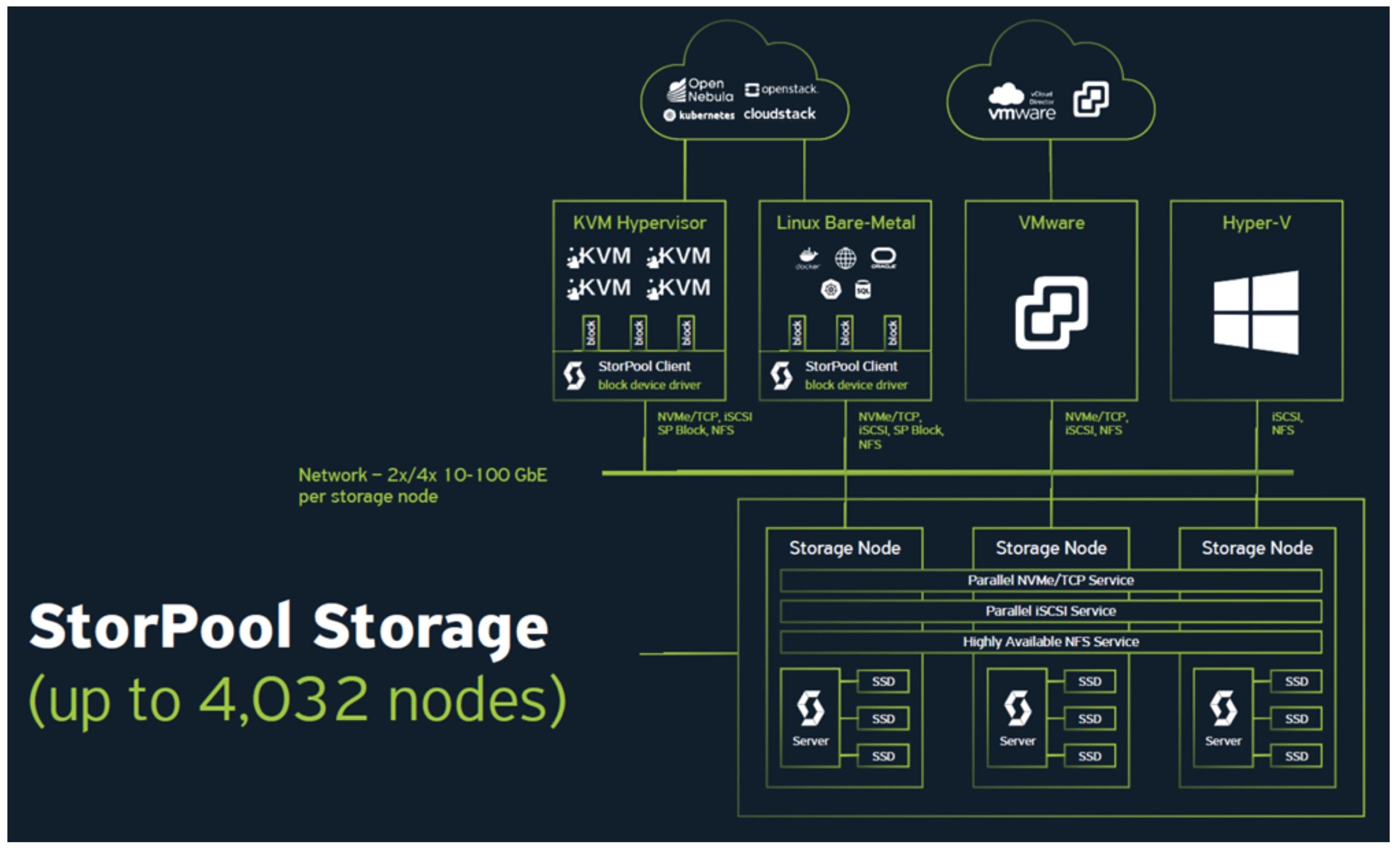
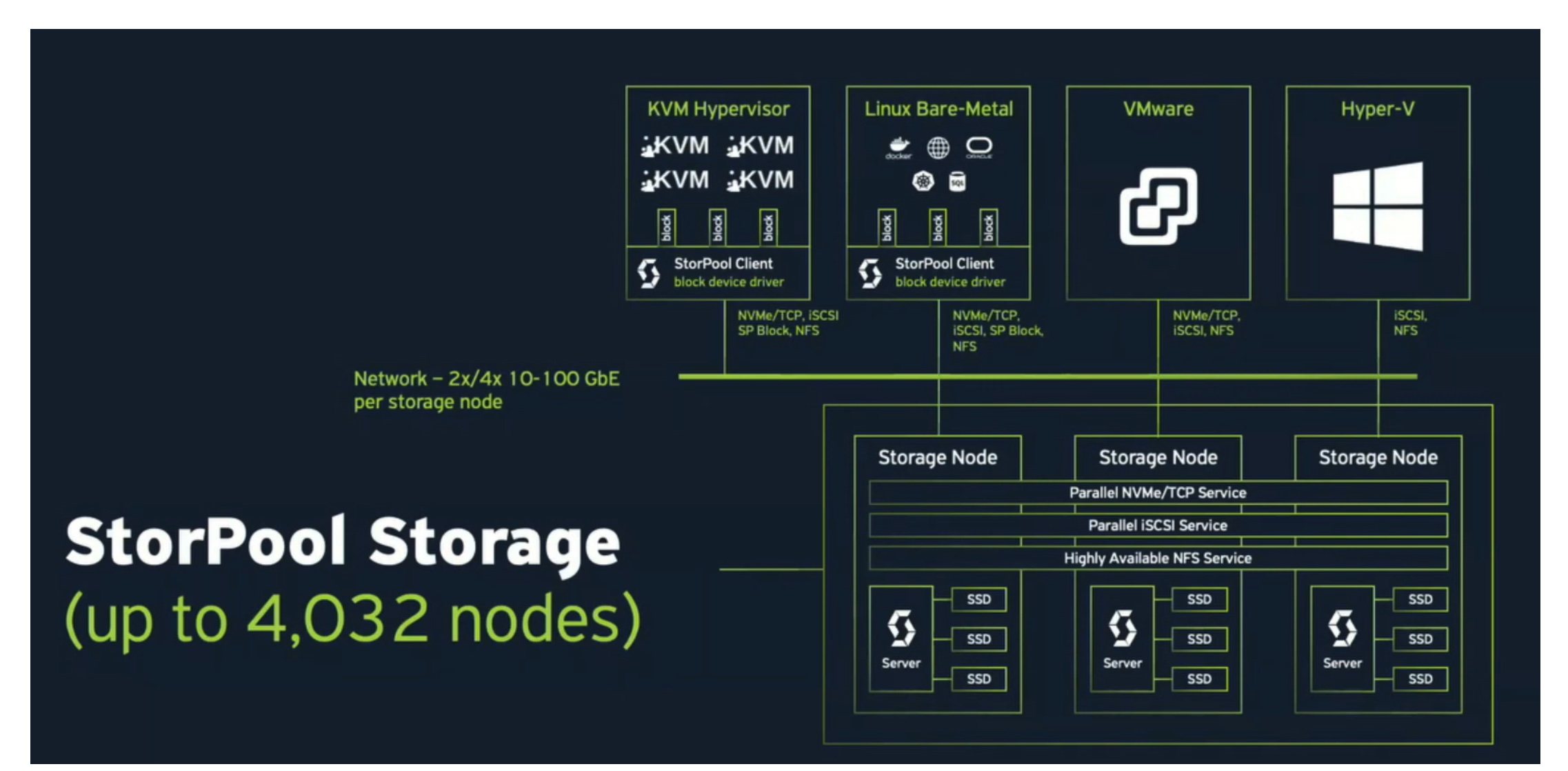
To mitigate these issues, StorPool built their primary storage platform as three or more storage nodes that work together to provide storage as a service. A single storage node consists of a series of a server with its local SSDs, accessed and controlled by server instances, connected via its internal network to dual 10+Gbe pipes (Figure 2).
StorPool provides data protection by triple-writing data across all storage devices within storage clusters, each comprising multiple nodes. Cloze-to-zero impact erasure coding is coming soon as a second data protection scheme.
Figure 1. StorPool: Storage Interfaces
So if a system has VMware compute nodes that need block storage, users just need to select iSCSI or NVMe/TCP storage interface. Similarly, if they want block storage for their Oracle database, they can use the same interfaces that will give them the required storage, while they can also run inside a VM and then use the StorPool native block device service.
Scaling capacity and performance is equally simple and minimally disruptive compared to the old centralized appliance building block model – just add one or more lightweight standard servers to the existing StorPool cluster – from the initial minimum configuration of three nodes to up to 4096.
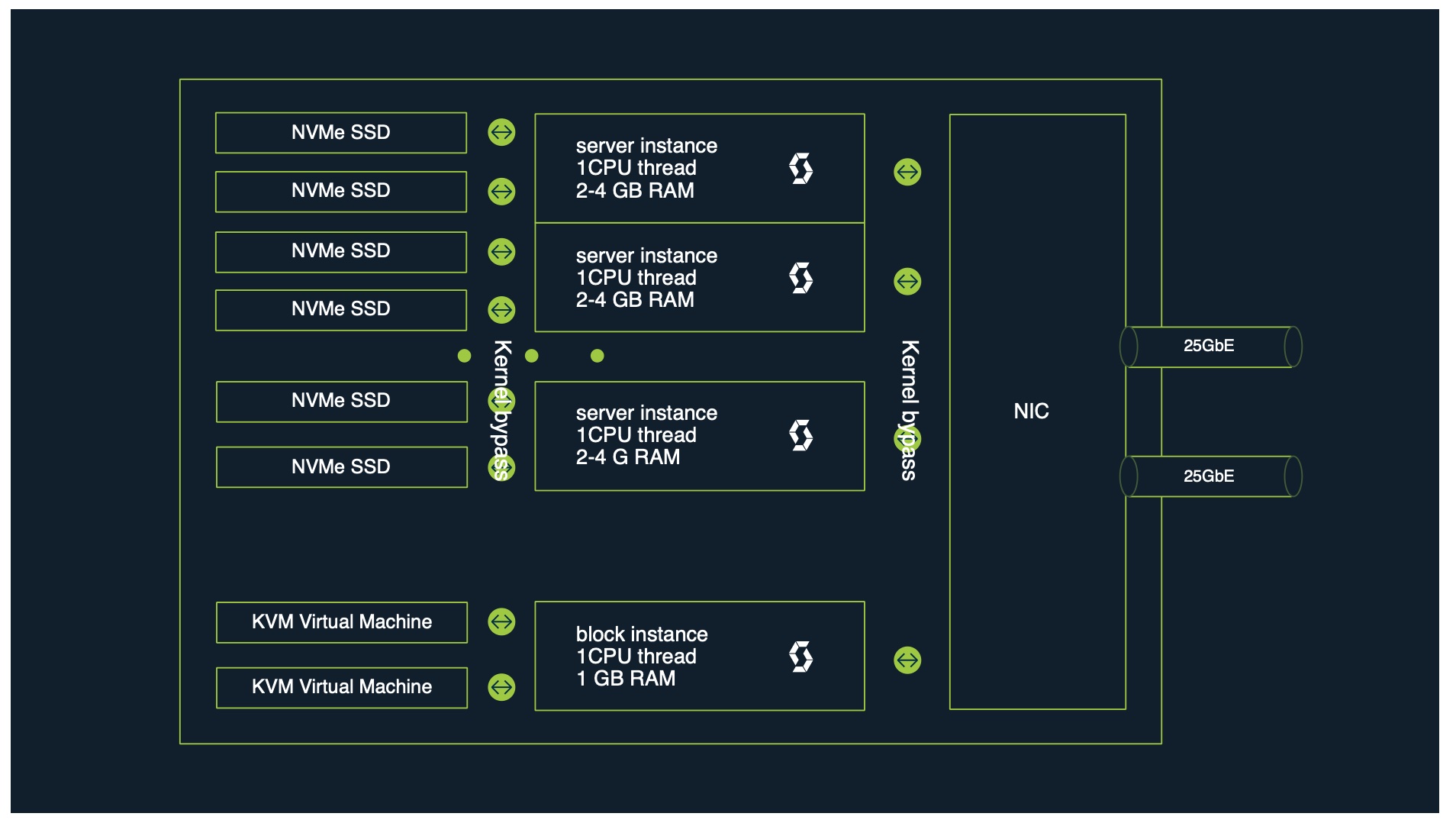
Figure 2. StorPool: Standard Node Architecture
Why Linear Scalability is Important
StorPool recognizes the importance of linear scalability of storage performance, regardless of any expansion in the overall capacity, or peaks in performance demand – for example, when adding a new I/O intensive application workload to an existing storage environment.
StorPool’s tests demonstrated near linear increase in IOPS performance, when the underlying hardware was expanded, while astonishingly still maintaining consistent and extremely low read/write operations latencies.
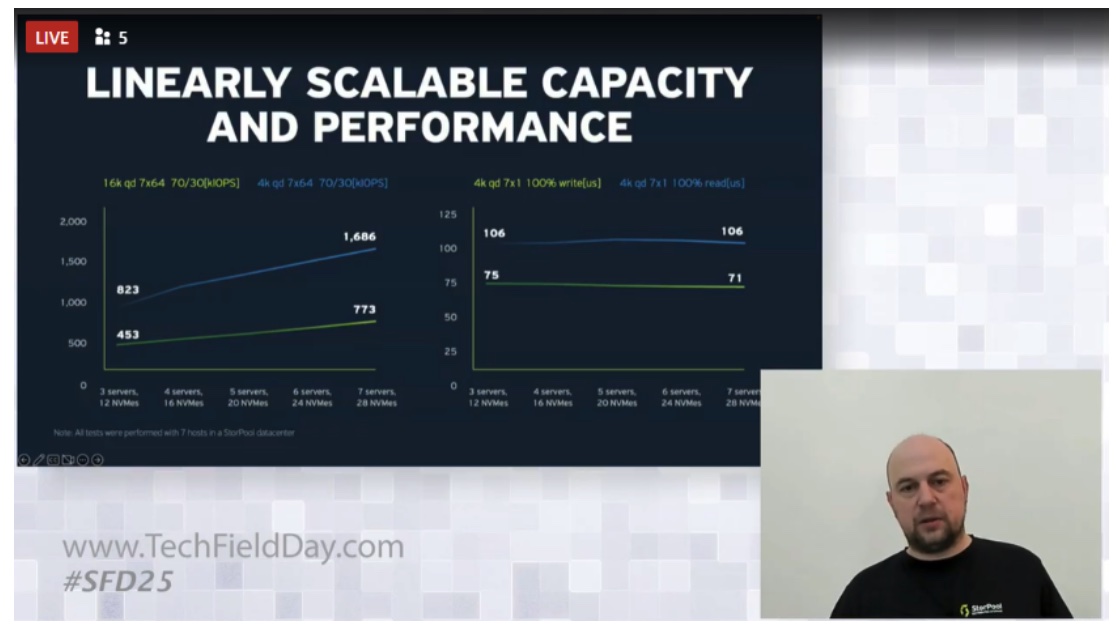
Figure 3. Linear Scalability Statistics

Figure 4. What Happens When a Hungry App Joins the Party?
Can We Get Off the Storage Treadmill?
As mentioned above, StorPool’s viewpoint on typical storage refresh cycles is an interesting departure from other storage vendors. Since traditional platforms require major reinvestments for capacity expansion and performance scaling, it’s not unusual for IT organizations to end up ripping and replacing their storage hardware every three or five years. Or sometimes sooner so to take advantage of the latest hardware, firmware, or software innovations.
This cycle is obviously disruptive, not just from a CAPEX perspective, but also because it’s never just as simple as plugging in the new equipment. Data must be migrated to the new platform, and there’s always a risk of something being lost during that transfer process.

Figure 5. Getting Off the Storage Treadmill
Conclusion
StorPool’s storage model is radically different. By standardizing storage nodes on commodity hardware, and concentrating on provisioning capacity in an as-a-service orientation, it’s much simpler for storage to become and remain what everyone in IT wants – always on, non-disruptive, reliable, and performant.
Learn more about StorPool on their website and watch their presentations from Storage Field Day on the Tech Field Day website or YouTube channel.