If you’ve been following Tech Field Day in 2023 you know that there’s been a lot of discussion around replacing InfiniBand with Ethernet. It’s the focus of the Ultra Ethernet Consortium as well as some new offerings from vendors like Broadcom and Cisco. All of those offerings can be simplified to the same basic idea. Why use expensive InfiniBand when we could use really fast Ethernet that you know and love?
The idea may be simple but the implementation isn’t. Ethernet has lots of challenges that need to be overcome, the least of which is latency. the UEC is focused on solving the challenges of Ethernet latency in the fabric that connects the GPUs together in a system dedicated to AI workloads. The key is doing things to the packets in the fabric to make them get to the GPUs as fast as possible. That’s great in the GPU backbone. But what about getting packets to the GPU?
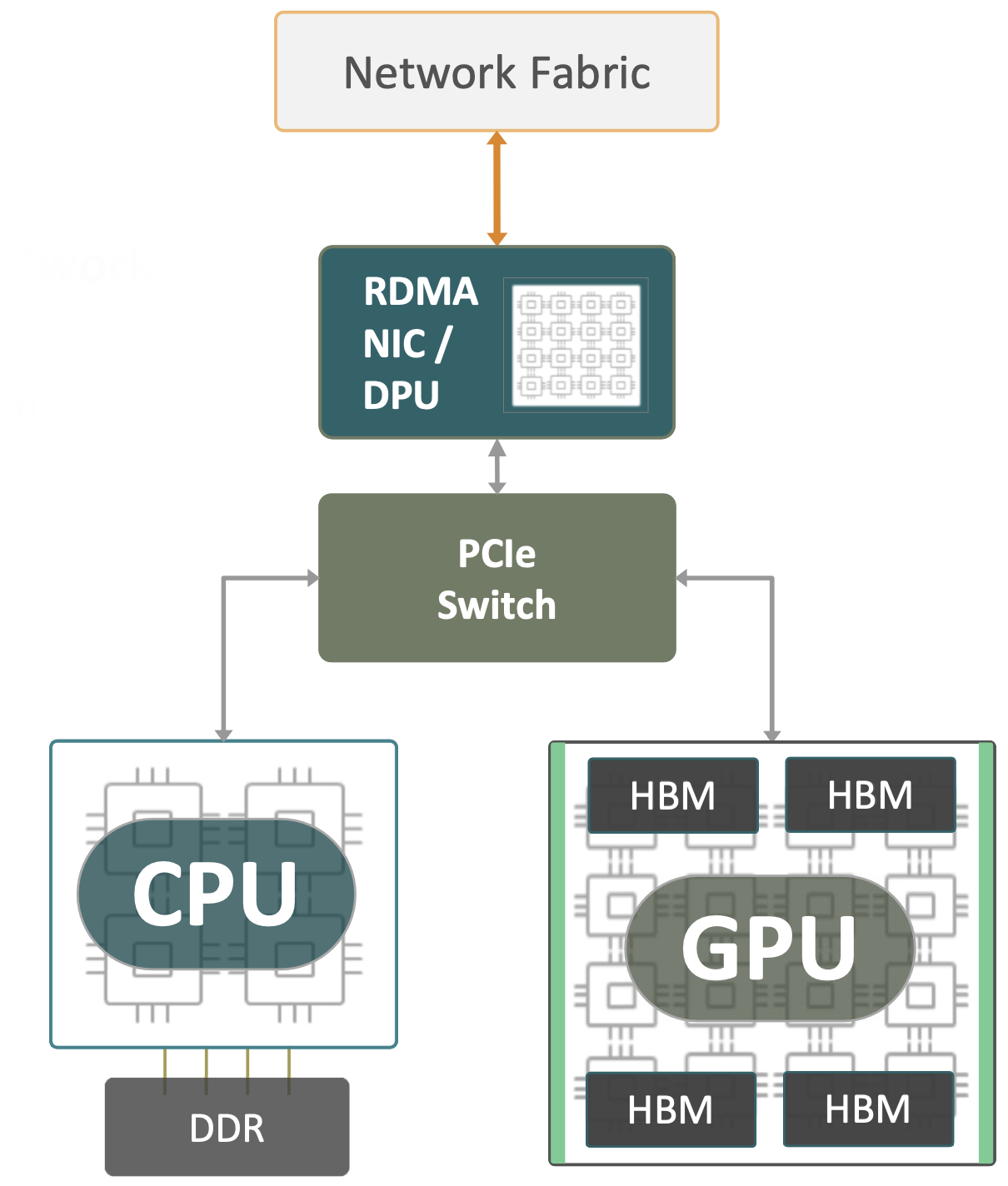
In a modern system you have issues with the connection between the NIC and the GPU. Because GPUs don’t have on-board NICs they rely on the network to deliver packets to the system for processing. InfiniBand is built to handle the communications between the GPUs. You still need to get the workloads and the data delivered to the GPU clusters. That means your expensive resources could be idling waiting on a delivery of raw data to make something critical. You don’t want that, especially if you’re trying to scale your system to deal with huge amounts of data input. You need a way to create scale for the system.
ACF-S From Enfabrica
If you’re Enfabrica, you solve this problem by consolidating it. They have built the Accelerated Compute Fabric Switch (ACF-S) to bridge between the Ethernet on the front of the cluster and the hungry GPUs on the backend. ACF-S also has CXL connectivity as many have written about already but that’s not the critical piece today. The idea behind ACF-S is to reduce latency in getting your critical input data from the network to the GPUs so you’re not wasting that super expensive high bandwidth memory (HBM) waiting for your raw materials to arrive through the network.
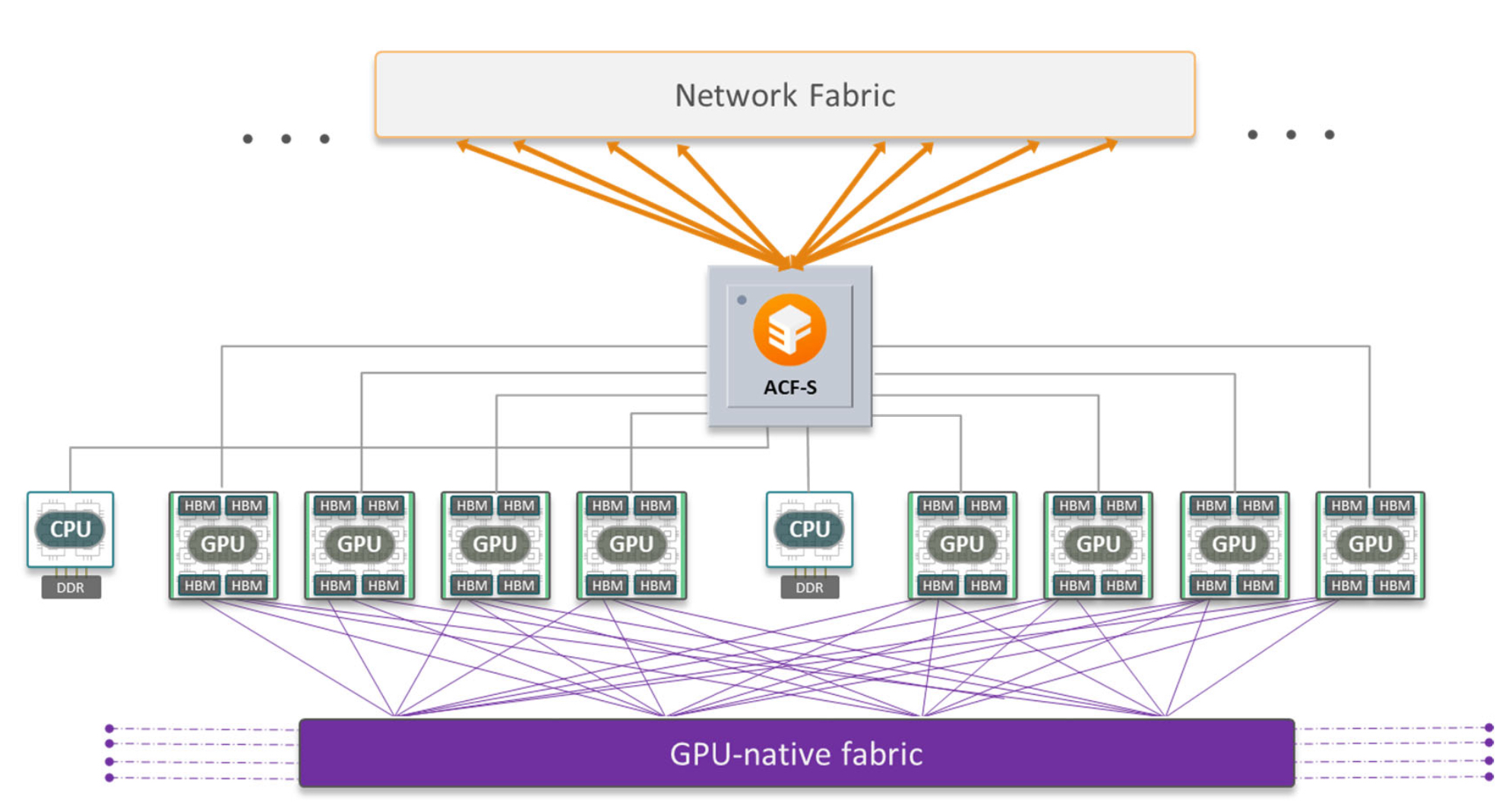
ACF-S replaces the NIC and the PCIe switch and routes the traffic for the GPUs through their system. The idea is to allow up to eight GPUs to connect through ACF-S to provide lower latency. At first that may not sound like a groundbreaking idea. After all, reducing the amount of hardware is going to make it faster, right? But it’s about more than just creating lower latency. It’s also about creating an infrastructure that scales better as you throw more information at it. Right now if you want to scale the workloads you’re going to need to buy more expensive HBM to improve performance. You can’t even be sure that throwing more memory at the problem will solve it. You need a system that can sit in the middle of it all and ensuring the raw data is delivered to the proper place so that no GPUs in the cluster are idling.
Now, instead of spending significant amounts of capital on the GPU side of the house you can instead provide the resources that your workloads really need. Memory is much cheaper than GPUs as of right now, and that will become even more true with the next generation of technologies like the Grace Hopper Superchip or AMD MI300 which will integrate the GPU and CPU onto the same package. Now, your real bottleneck will be memory. And how can you add memory to a system that is already maxed out? Instead, ACF-S allows you to better allocate resources where they should be used instead of overloading some systems while others have nothing to do.
The Next Steps
Since Enfabrica’s ACF-S functions like a logical focus for the I/O in a GPU fabric, who’s to say we can’t abstract more of those functions away as we require increased performance? As the needs of the cluster grow it is easy to envision a world where ACF-S takes on more and more of the I/O scheduling and prioritization to ensure everything is running as quickly as possible.
Think of it more like a Super NIC than anything else. Nvidia is already using the term to describe their Bluefield-3 devices in Spectrum-X but ACF-S has ten times the throughput. It also ensures that you can send important compute tasks to the GPUs to more fully utilize their HBM on the tasks that HBM is best for and leave the other more pedestrian tasks to the system CPU. Because of the way that ACF-S takes over scheduling the I/O for the system you have viability you never had before.
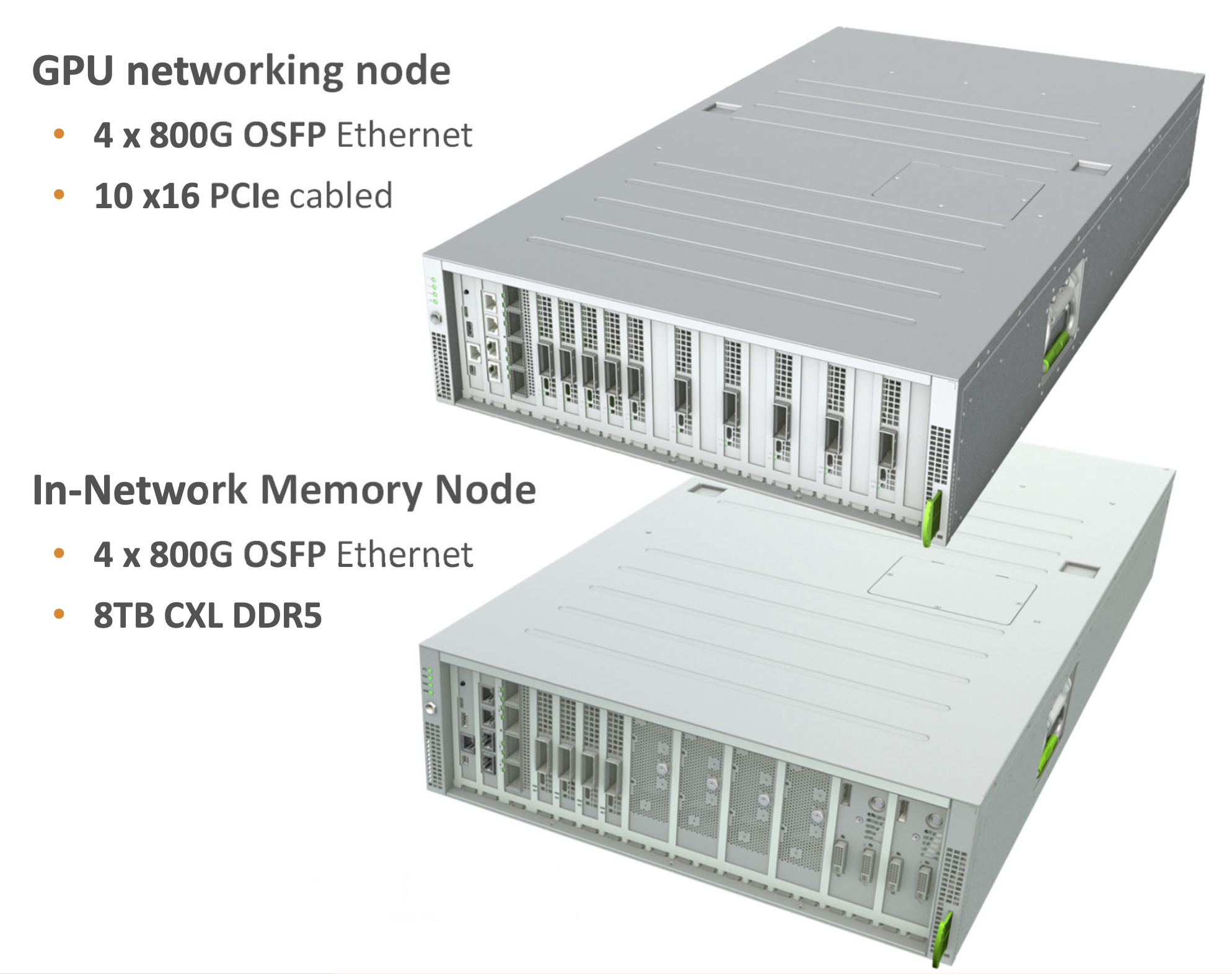
Right now, ACF-S is a functional replacement for NICs. The two units you can order have 4x800Gbps and are focused on either GPU networking or in-network memory. The goal is to replace the PCIe switch connecting your components as well as the Ethernet ToR switch. Because ACF-S speaks RDMA verbs it can work with RoCE, RDMA over TCP, or even Ultra Ethernet when it’s ready. More importantly, it’s an expandable system that provides functionality to help you plan your expansions in the future to provide the resources you need instead of whatever is available to throw more hardware at an uncertain problem.
Bringing It All Together
Seeing the plans that Enfabrica has for ACF-S makes me much more optimistic about where the AI networking space is headed. We have to look at how we’re utilizing the whole stack and find ways to improve it all. That means implementing more than just faster Ethernet. We need to look at everything to help us add the right resources in the right amounts and enable us to make better decisions about how to use what we have to the fullest potential possible. That’s why I’m going to be watching what Enfabrica does with great interest in 2024.
For more information about Enfabrica and their ACF-S solution, make sure to visit https://Enfabrica.com for more details.