Have you ever thought about how a search function operates? On the surface it sounds pretty easy. You take a dataset and you look for things in it. I’m sure that Google and Microsoft will tell you that it’s a lot harder than that but we’ll keep it simple for now. How do you know what’s in the dataset? You have to look at it before you can search through it, right? That means ingesting the data before you can perform operations on it.
When the dataset is just the contents of your phone or your laptop that doesn’t sound like a difficult proposition. When the dataset is petabytes of information in the cloud or the entire Internet it’s an entirely different animal to tame. Setting aside the whole issue of algorithms and ranking for now you have to consider some even more basic challenges. How do you ingest a petabyte worth of data? How long would it take to transfer the data to your search platform? If this is happening in the cloud will you be paying to get that data to the destination just to return smaller results? Why should you have to pay to move something only to leave it there?
Searching Smarter
If you’re scratching your head and wondering why search feels backwards you’re not alone. Cribl is a company that has asked those same questions and figured out a better answer. I had the chance to sit down recently with Nick Heudecker and talk about the latest quarterly release, Cribl 4.1. Cribl search especially got some new enhancements in this version that got my attention.
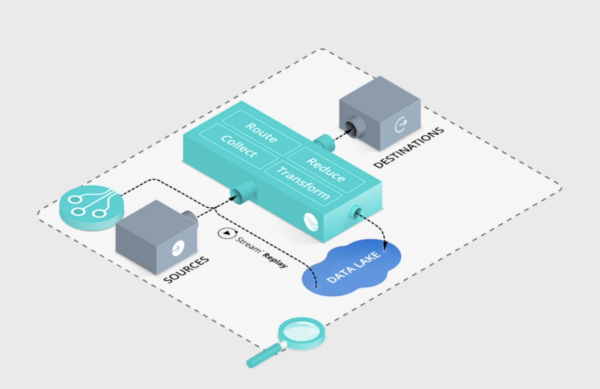
Cribl’s flagship product is Stream. Stream is an observability pipeline that lets people see what’s going on in the data. You need to feed Stream in order to observe things and the product has been growing by leaps and bounds. But you also need to winnow down the data that you’re seeing and that’s why Cribl built Search late last year.
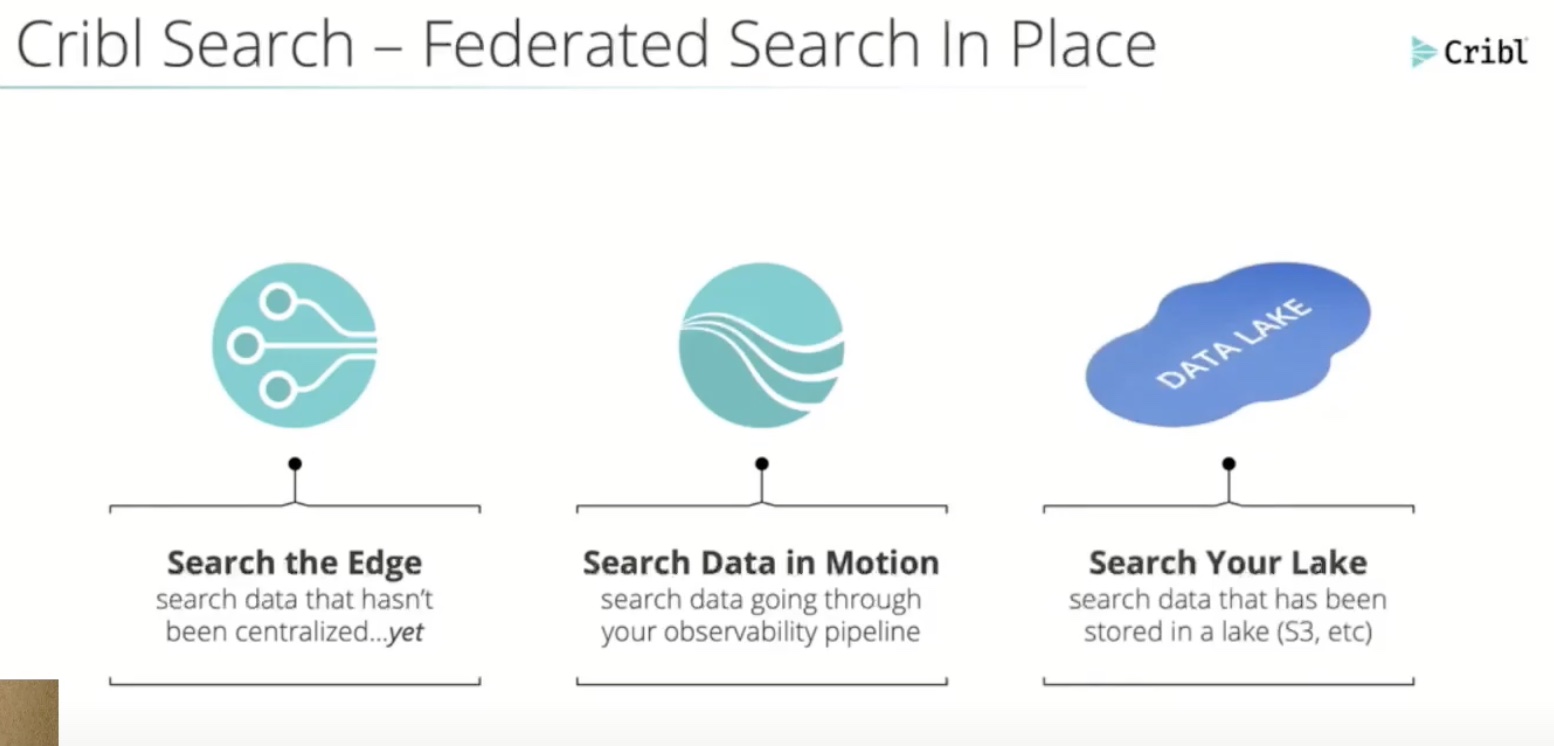
Search is a federated query engine that lets you look through datasets, with a specific focus on security. Nick told me that Cribl specifically focuses on customers that don’t want to run two different environments to separate observability and security.
Cribl Search launched last year and here’s a great video introduction to it that happened at Security Field Day:
In Search 4.1, Cribl is getting even smarter. There’s a new S3 destination that can be added to the pipeline. There’s also a new send operator that allows Search to send data to Stream. This is one of the pieces that I think has the potential for a massive impact on the way that observability platforms operate. Rather than ingesting a huge amount of data and then combing through it you flip the whole idea around. Cribl Search looks in the data where it lives and returns results you want. Those results are then fed into Cribl Stream for your operations teams to make decisions.
While I was talking to Nick about the impact this could have on the way we consume data, he had a quote that stuck with me:
We have no more empathy for our compute infrastructure. — Nick Heudecker
That’s a pretty accurate assessment of the way that most organizations treat their data lakes. Just keep feeding it and eventually something will come out that is important. However, with the traditional search model your attempts to search that data lake are going to look more like a dam bursting. You have to move all the data into the search platform which means paying the costs to get that data out of the cloud. If you haven’t checked recently you might be shocked to see what Amazon wants to charge you to get that data back into your organization.
By using Cribl Search instead you can ensure that only the most interesting parts of the data are sent back. You can make decisions based on what you want to see and not have to pay for the rest of the uninteresting parts. More importantly, you can then use Search to find other things and feed them back into Stream. You have the flexibility to keep looking without moving the data around over and over again. That leads to reduced costs and a reduced carbon footprint over time. You get your precious minutes back and you can work on saving the planet at the same time.
Bringing It All Together
Cribl has committed to a quarterly release schedule, which is something I really like. By having a cutoff for features to make it into the release they can go out when they’re done, not when a deadline needs to be met. Incremental improvements in new tools like Search can be rolled out to help augment mature products like Stream. The rapid build process also allows Cribl customers to request new data types for ingestion. That means the platform is always on the cutting edge for their customers. I’m excited to see where Search will be in the next six months.
For more information about Cribl and their newest release, make sure to check out https://Cribl.com. To see more of their presentation at Security Field Day you can go to the Cribl presentation page.